
同样做标注,为什么美国公司这么值钱?
原创 几重山月 | 2026-03-31 21:36
【数据猿导读】 AI的底层战争:中国有数据、有人力、有场景,为何跑不出Scale AI?”

““AI的底层战争:中国有数据、有人力、有场景,为何跑不出Scale AI?”
你敢相信吗,一家2016年成立的数据标注公司,它的估值竟能追平百度与理想汽车?
2025年6月,Meta豪掷143亿美元,拿下美国数据标注巨头Scale AI的49%股份,将其估值一举推至惊人的290亿美元(约合人民币2082亿元)。
这一数字意味着什么?截至2025年6月20日,百度的市值约为287.5亿美元,理想汽车为263.6亿美元。Scale AI的估值,已然超越了许多我们耳熟能详的科技巨头。
在人工智能浪潮席卷全球的今天,高质量的数据资源被誉为新时代的“石油”。而未经加工的原始数据如同埋藏地下的原油,其巨大价值需通过一道关键工序方能释放——这就是数据标注。
成立十年的Scale AI,不做模型,不搞应用,只专注一件事:为全球顶尖AI公司提供高质量的标注数据与数据管理平台。如今,这家曾被视为“AI产业链底层苦力”的公司,正迎来高光时刻。
然而,视线转回国内:尽管中国拥有全球最庞大的数据资源、最丰富的标注劳动力、最活跃的AI应用场景,却始终未能跑出一家Scale AI级别的超级独角兽。
同样是为大模型准备“养料”,为何中美两国的命运如此迥异?是技术的代差,还是商业逻辑的错位?
为探究原因,我们联系到了国内头部的数据标注公司海天瑞声(688787.SH)和本原智数的相关负责人,试图从商业环境土壤、行业运作路径以及未来破局之道等维度,拆解这一现象背后的深层逻辑。
商业环境的温差:
底层逻辑与产业生态分野
营收规模的落差,是中美数据标注企业最直观的差距。
海天瑞声董事会秘书张哲在接受数据猿采访时坦言,国内外数据标注企业的估值差距,本质源于收入规模的量级鸿沟。
公开数据显示,Scale AI收入由2022年2.5亿美元升至2023年7.6亿美元;在2024年营收约8.7亿美元(约合人民币62.3亿元),单笔合同与客单价多在八位数至九位数美元区间。东吴证券研报披露,Scale AI预计 2025 年收入达到20 亿美元(约合人民币143亿元),并实现EBITDA 盈利,2026 年销售额接近 40 亿美元。

Scale AI联合创始人 图源:Alexandr Wang社媒账号
与海外头部企业相比,国内数据标注公司的营收规模大多处在几千万到几亿的区间,两者之间的量级差距显而易见。
这背后,其实暗含了“水大鱼大”的道理——“水”是AI应用市场,“鱼”是数据服务企业。当前,美国市场的“水域”更为广阔。这不仅源于技术层面的先发优势,更得益于其成熟完善的软件商业生态。在这样的土壤上,自然生长出了层次丰富的产业格局:既有Scale AI这类覆盖全链条的全能型服务商,也有Surge AI、Turing等聚焦模型微调的垂直玩家,还有Lionbridge等深耕文本、语音领域的专业机构。
反观国内,尽管AI产业发展突飞猛进,但产业之间的分工与美国相比,还不够专业、不够合理。不少互联网大厂倾向于自建众包体系,将数据标注视为内部闭环的一部分。这种“自成一体”的模式,在短期内保障了数据安全与响应速度,却也无形中挤压了专业数据服务商的成长空间。
更深层来看,数据服务本质上属于广义的软件行业,而中国长期以来“重硬件、轻软件”的发展惯性,使得软件生态的培育缺乏足够的土壤。相比美国从企业级软件时代就积累下来的分工习惯与付费文化,国内的数据服务企业往往更难获得规模化发展的机会。水域虽在扩张,但真正能容纳大鱼畅游的深水区,还有待时间与生态的逐步完善。
产业格局分化:
客户壁垒与市场集中度差异
当前,数据标注产业已形成清晰的上下游生态。其上游是数据源头与需求方:一方面,数据来源广泛分布于互联网公司、政府机构、车企、医疗机构及金融机构等,它们是原始数据的生产者和拥有者;另一方面,需求方主要包括AI算法公司、科技巨头、具身智能企业、高校及科研院所,以及传统企业的数字化转型部门,他们是标注服务的最终客户,驱动着整个产业的运转。
从客户结构看,Scale AI的高速增长离不开顶级客户资源的支持,其核心客户包括OpenAI、微软、Meta、英伟达等科技巨头。2024年公司实现营收的8.7亿美元中,仅Google单一客户贡献便达1.5亿美元。

Scale AI 官网界面
此外,美国军方这一特殊大客户成为Scale AI崛起的关键助力。公开信息显示,军方采购是其核心收入来源之一,巨额且稳定的订单助力公司完成原始积累。
本原智数CTO林震亚提到了客户需求方的原因,中美需求侧对数据外包的态度存在本质差异,这也是制约国内产业发展的关键因素之一。“美国的企业,像OpenAI、谷歌,非常愿意把整块的业务包出去。他相信数据公司对数据的理解是比他自己深的,而在国内,数据团队中反而是很有话语权的供应商,基本上只能在(数据标注)基地里去提供人力”。
林震亚强调,这种模式本质上是需求方将核心的数据理解能力牢牢掌握在自己手中,并未给第三方数据公司留下足够的成长空间,导致国内供应商难以构建真正的核心壁垒。“国内的数据企业没有非常强的核心竞争力,而且国内又特别的卷,然后卷的话就导致分散,国外可能就是三个头部公司就能吃下70%—80%的市场(份额),而国内排名前三的(公司)估计也就吃了20%—30%的市场(份额)。”
市场结构的极度分散,成为阻碍行业诞生独角兽的关键。据林震亚分析,国内数据标注企业数量多达两三千家,行业碎片化严重。这种分散不仅源于企业数量众多,更与政府项目的采购壁垒密切相关。他透露,很多政府项目都是点对点直接发包,即便头部企业也难以与政府建立深度合作,接触不到核心标的,项目最终多被地方小团队承接。缺乏集中效应的市场环境,使得国内数据企业难以做大做强,自然无法形成类似Scale AI那样的规模护城河。
不过,林震亚也表示,国内行业正逐步走出困境。随着市场对模型能力和体系化建设的重视程度不断提升,国内数据企业只要明确发展目标、搭建标准化体系,完全有能力构建核心竞争力,实现高质量发展。
寻找破局之道:
乘势而上与筑高壁垒
海天瑞声相关负责人也对中国市场的未来表现出了强烈的信心,在“水大鱼大”的产业逻辑里,中国AI市场这一“蓄水池”正迎来质变。“当我们的模型能力与一线模型差距在缩短,应用一起来,反倒是‘AI+应用’成了我们的优势”。
他进一步表示,2025年8月国务院印发的《关于深入实施“人工智能+”行动的意见》,已明确了未来十年国家在人工智能领域的战略方向,“就是要举全国之力干这件事,央国企体系的带动下,也会带动民营领域。所以我觉得我们这个‘水池子’变大的速度会更快。水大了,鱼长大的速度也会快,这是自然规律。海天瑞声要做的,就是争取成为比较大的那条鱼”。
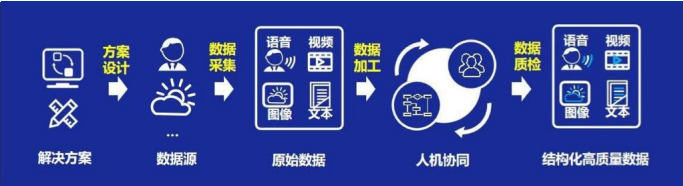
人工构建可信数据集过程 来源:海天瑞声 2025 半年度报告
在国家“AI+数据要素”战略的指引下,重点央企自2024年起加速布局通用+垂向大模型研发,带动了高质量图像、视频等训练数据的规模化采购需求。海天瑞声已成为中国移动重要的数据服务供应商。并且公司也在全面推进全球化战略布局,一方面通过东南亚交付基地的建设构建海外标注产能,重点拓展更具市场潜力的定制化服务;另一方面加快全球化服务网络建设,已在中国香港、新加坡和美国设立区域子公司,并积极推进日本、韩国及欧盟子公司落地,提升客户触达效率和需求响应速度。
与此同时,本原智数正在尝试通过科研实力打破僵局。林震亚进一步指出,纯合成路线难以走远,“标注的本质是把人类的知识精华沉淀下来给模型学习,如果全合成,人类精华产生的价值就非常小了”,并且若企业仅做数据合成,客户最终采购的是合成模型而非数据服务,一旦该技术被攻克,企业便失去核心壁垒。因此本原智数坚持‘人机结合’模式,虽具备合成能力,但对外输出均以人工标注为基础,通过人工全流程校验,沉淀人类知识精华供模型学习。
凭借这一模式,公司构建起独特的竞争壁垒:既以合成能力实现效率升级,又以人工精修保障数据品质;同时汇聚全球顶尖人才产出顶会级科研成果,以技术高度建立与甲方的平等对话权,“我们需要一批全世界最聪明的人贡献自己的精华力量,对去贡献给模型”,将人类专业智慧转化为模型迭代的核心动力。
潮起东方:海外隐忧与本土数据价值释放
数据标注产业兼具技术属性与人力资源属性,其发展逻辑与全球产业格局紧密相连。业内资深人士认为,对于Scale AI的百亿美元估值不必过度焦虑。尽管Meta的巨额投资推高了其估值,却也让该公司陷入身份尴尬与信任危机。受Meta介入影响,谷歌、OpenAI、微软等核心客户出于数据隐私与商业竞争考量,纷纷削减或终止合作,使其面临核心收入流失的风险;而Meta自身也未完全依赖Scale AI,仍保留与其他竞争对手的合作关系,进一步加剧了其商业处境的不确定性。
与此同时,Scale AI的运营模式也暗藏隐忧。据公开信息显示,该公司通过旗下众包平台Remotasks,将基础框选标注任务分包至菲律宾、肯尼亚等地区,其900名正式员工之外,依托超24万遍布全球的低成本临时工完成生产。这种劳动力结构虽能维持成本优势,却引发了数据质量、劳工权益等争议,甚至使其贴上“数字血汗工厂”的标签,光鲜的技术光环之下,潜藏着运营模式的脆弱性。
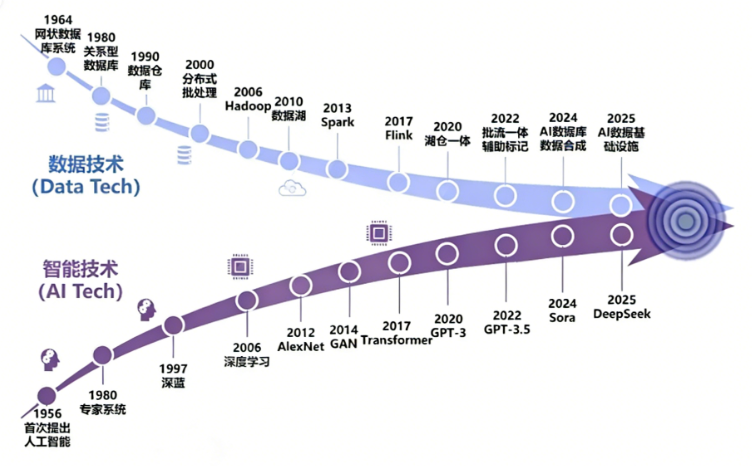
数据技术与智能技术深度融合演进趋势 来源:中国信息通信研究院
与此同时,国内数据要素市场正迎来前所未有的发展机遇,呈现出强劲的增长势头。
2026年3月24日,国家数据局局长刘烈宏介绍,截至2025年年底,全国已建成高质量数据集超过10万个。到今年3月,我国日均Token(词元)调用量超过140万亿,相比2024年初的1000亿增长了1000多倍,相比2025年底的100万亿,三个月时间又增长了40%多。数据调用激增,反映我国AI进入快速增长期,应用从对话向智能体演进,产业竞争力增强,数据要素价值释放,与AI发展形成良性互动。
词元调用量指数级增长,标志着数据要素通过可计价模式实现从供给到价值的闭环,大模型竞争正从能力比拼转向用量比拼,而AIInfra作为支撑调用规模扩张的核心环节,意味着算力、网络、数据调度等底层支撑系统必须同步甚至超前扩张,将充分受益于Token需求的持续攀升。
针对高质量数据集建设“小和散”的问题,国家26个部门组织遴选了72家高质量数据集建设链主单位、140个先行先试工作单位和104个典型案例,构建了链主带动、多方参与、联合攻关、共建共享、合作共赢的高质量数据集建设生态,从而持续推动高质量数据集的建设。
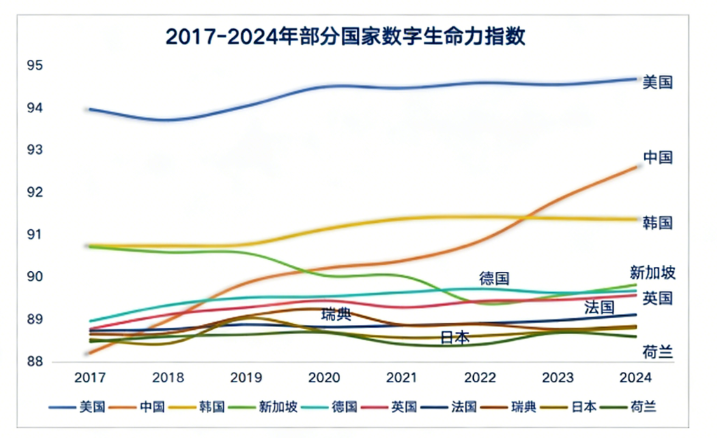
2017-2024 年部分全球数字生命力指数发展趋势 来源:中国信息通信研究院
与海外巨头通过资本与订单构建的“中心化”垄断格局不同,中国的数据标注产业更像是一片“万鱼竞逐”的蓝海。面对中美数据标注产业在体量上的客观差距,或许我们不必急于寻求单一的“中国版Scale AI”。恰恰相反,中国市场的独特魅力,或许正蕴藏于其“去中心化”的蓬勃生态之中。
截止到2025年年底,全国已建成的高质量数据集超过了10万个,总体量超过了890PB,这相当于中国国家图书馆数字资源总量的310倍左右。
“水大了,鱼长大的速度也会快。”当海量的高质量数据集与指数级增长的Token需求成为这片海域的充沛养分,我们看到的不再是孤独的巨鲸,而是万千条充满生机的“鱼”在竞相生长。这种勃勃生机,正是中国数据标注产业从“跟跑”迈向“并跑”乃至“领跑”的最强底气。我们期待,在这场万鱼竞逐的浪潮中,能涌现出更多具有独特竞争力的创新力量,共同撑起中国AI产业的广阔未来。
来源:数据猿


































































































我要评论
不容错过的资讯








大家都在搜


