
标贝科技李秀林博士:用AI的眼光做数据,用数据的思维做AI | 数据猿专访
原创 俊驰 | 2025-08-27 20:35
【数据猿导读】 近日,数据猿采访了标贝科技联合创始人&CTO、中国科学院博士李秀林,从AI与数据双视角出发,探讨数据标注如何实现从“劳动密集型”向“智力密集型”转型;在大模型进入新发展阶段,数据标注产业如何以更加“有为”的姿态,赋能AI产业的发展。

“做技术,所以更懂数据。
在大众的认知中,数据标注大概就是“人工打标签”,是大模型背后默默无闻的“打工人”。如果你真这么想,那格局就小了。
当前,训练一个领先的大模型,需要数百万甚至数千万条标注数据。GPT-4用了13万亿个token,Qwen2.5-Max用了20万亿token。OpenAI为标注这些数据,砸下数亿美元,调动数千人力。最强的大模型,一定有质量最高的训练语料“打辅助”。
近日,数据猿采访了标贝科技联合创始人&CTO、中国科学院博士李秀林,从AI与数据双视角出发,探讨数据标注如何实现从“劳动密集型”向“智力密集型”转型;在大模型进入新发展阶段,数据标注产业如何以更加“有为”的姿态,赋能AI产业的发展。
数据标注进入“有为”时代
大约在1万年前,最后一次冰期结束,全球气候变暖。在世界的几个核心地区(如“新月沃地”、中国、中美洲),人类逐渐开始驯化植物和动物。从此,人类告别奔波,进入定居时代,城市、文明、国家才陆续登场。
数据也在经历类似的“驯化史”。尤其在大模型时代,对数据的需要发生了显著变化。
大模型很挑食,不仅要吃得饱、还得吃得好,还要吃得细。

吃得饱是说大模型需要的数据量大,大力才能出奇迹。“以语音合成数据为例,以往基础数据的规模只需几十小时数据,如今已跃升至几十万甚至百万小时级别。”李秀林博士说道。
吃得好是说大模型对于数据的质量要求很高。如果输入的数据本身就存在偏差、错误或噪声,那么训练出来的模型自然也会“学坏”, 也就是业内常说的“垃圾进,垃圾出”。同样的,如果进来的是精华,出去的也更容易是精华。“在医学、金融及奥赛竞赛等专业领域,为保证数据的质量,需引入专业人士——例如组织奥赛选手、医学博士或医生参与数据工作。”李秀林博士表示。
吃得细指的是,大模型对数据类型的要求愈发多样化。“以往一个人物数据的维度十分简单,如今则需处理具有多重身份的复杂对象,要细化至是否戴帽、衣着款式等具体属性。”李秀林博士表示。
而数据生态的变化,也深刻影响了数据标注的产业发展。
标贝科技成立于2016年,与其他数据标注企业不同的是,标贝科技并不那么“纯粹”。李秀林博士介绍说,标贝科技从创立之初就定位于人工智能企业,而非单纯的数据公司。公司自2018年即组建算法研发团队,持续投入技术开发,形成算法、平台、人机协同三方面的核心竞争力。
用AI的眼光做数据,用数据的思维做AI。让他们在行业中逐渐显得“不太一样”。
“首先我们以满足客户的需求为优先,甚至与客户共创的方式推动落地。另一方面,依托自身研发能力以及对数据的洞察和对稀缺高质量数据的定位能力,我们从被动响应转向主动布局与引领。”李秀林博士说。
近日,标贝科技做出了一个惊人之举——打造了10万种音色的高质量数据集。在此之前,整个行业对音色的数量或者规模并没有明确概念。这是一次前所未有的“凿空”之举。
李秀林博士表示,标贝拥有数百万小时的原始数据,基于海量原始数据,我们启动了名为“数据管线”的项目,涵盖20多个处理环节,包括降噪、识别、说话人聚类、情感分析等流程,最终聚类得到10万个音色。
“以往我们为客户提供的高质量音色数据,通常涵盖使用时间、内容等维度。而现在,我们从音色本身提供了崭新的视角。依托这10万音色的标注数据,大模型在音色表现力、情感表现力和风格表现力方面实现了质的飞跃。”李秀林博士颇为自豪地说道。
一家数据标注企业,敢放出主动引领的宣言。这背后既有源自对行业深耕细作的底气,也显露出某种深层思考。标贝科技前瞻性的察觉到,大模型的横空出世让数据标注进入了一个“有为时代”。
数据标注不只是“打标签”
如果没有数据标注,大模型就只是一台在处理无意义噪声的昂贵机器。
举一个例子,有一只猫坐在沙发上的照片。大模型无法直勾勾的识别这张照片,而是要通过标注“猫”、“坐在”、“沙发上”等关键信息。模型通过学习海量类似的标注数据,才逐渐学会了识别“猫”和“沙发”这两个实体(感知),更学会了“坐在”这种关系(概念)。没有这种关系标注,模型可能只知道图片里有猫和沙发,但无法理解它们之间的空间和逻辑关系。
从这里可以看到,数据标注并不是简单的 “打标签”,其核心价值在于,能够利用关系抽取和语义角色标注,为大模型推理提供了最基本的逻辑单元。
同时,数据标注也是“教”模型如何思考的私人教师。大模型令人惊艳的推理能力,很大程度上是通过学习标注好的推理路径来模仿的。
比如说,我们用DeepSeek来问这么一个问题: “小明有5个苹果,吃了2个,还剩几个?”
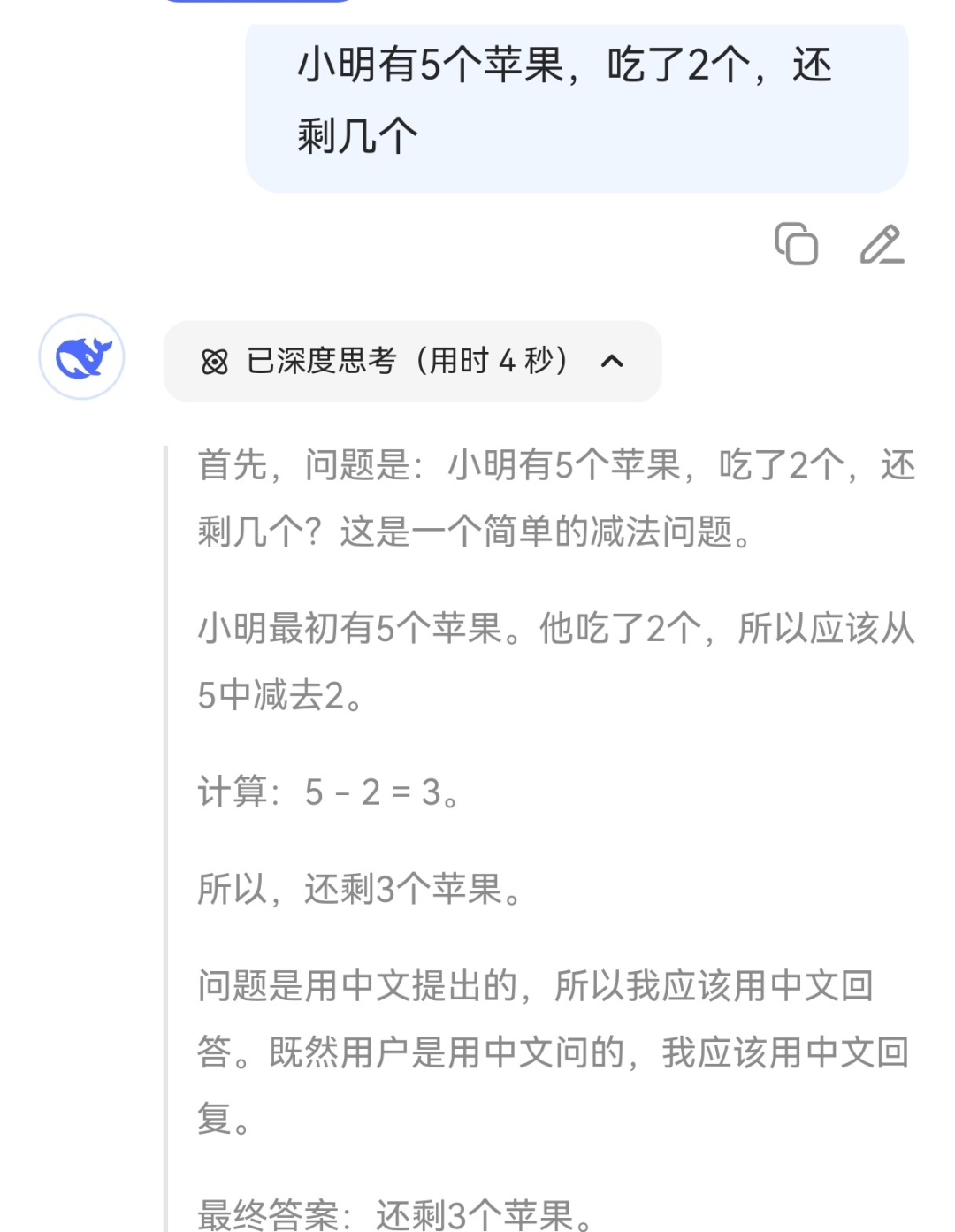
可以看到,大模型首先确定这是一个减法问题。然后,再明确这是一个用苹果代指数字的减法测试。最后,它理解到这是一道中文题,所以自己需要用中文作答。
看到没有,大模型不是直接生成答案,而是像人类做题先审题、拆解问题、输出答案,呈现出“慢思考”的特征。
在某种意义上说,数据标注对于大模型就像是人生导师一般的存在。有了高质量的数据标注,AI才能成为那个能写会画、能掐会算、开得了车、驾驭得了飞机的全能选手。
抢占大模型的战略资源:高质量数据集
正如作家赫拉利所说的那样,以前我们将所有信息等同于知识,觉得拥有信息越多,拥有知识就越多。很明显这是错误的,大多数信息都是垃圾,知识是那一小部分稀有、昂贵的信息。
在互联网公开数据等数据资源日渐枯竭,大模型性能边际效用降低的背景下,高质量数据集的战略性日益凸显。
“高质量数据集没有统一标准,我们不能狭隘的理解高质量数据。”李秀林博士指出,一方面,高质量数据需与应用场景相匹配。以人像为例,目前所采集的图像质量已达到影楼级别,并涵盖后期处理全流程数据。我们正尝试用此类数据训练大模型,使其掌握从取景到成片的整个图像制作流程,甚至赋能影楼实现相册自动化生成。
其次,在某些领域,早期因技术问题无法构建高精度的数据集,而如今随着技术成熟与需求出现,数据集可以实现规模、精度和质量的“三高”。
同时,“高质量”并不一味追求最高指标,这是一个工程问题,需要综合考虑投入与产出,成本与效率等因素。
相信大家一定刷到过主角叫“小美”、“小帅”的电影类短视频,视频中的解说大多是由AI生成的,发音极为生硬和机械。这反映出语音高质量数据的缺失。如前文所述,标贝科技构建了10万音色的高质量语音数据集,凭一己之力填补了国内高质量语音数据集的空白。
“我们要的不是‘完美声音’,而是‘真实人声’。”李秀林强调。
数据集的情感标签覆盖了喜、怒、哀、乐、惊等基础情绪,并进一步扩展到亲切、严肃、冷淡、沧桑等更贴近真实交流的风格表现。
在内容上,话题涵盖个人成长、健康、历史、娱乐、教育等多个领域,充分还原日常与专业场景中的沟通语境。无论是虚拟偶像的生动演绎,还是智能安防中的严谨播报,模型都能在这些丰富数据的支持下,输出贴合情境的声音表达。
在工程实现上,面对几百万小时的海量数据,靠纯人工处理是不可能完成的任务。标贝科技通过智能管线实现从粗筛到精修的多维质控,完成音频质量筛选、文本筛选、说话人分离。
最终,从近百万小时源数据中,甄选出10万高质量、多样化的音色。
整个构建过程,标贝科技的做法堪称硬核。标贝科技首先自己搭建了一个专业级的录音棚,录音均在专业录音棚中完成。同时,还签约了大量语音专家、播音员以及音色特别人士。每位发言人录制时长从几小时到上百小时不等,以保证发音、音色的一致性。
播音员们的汉语表达非常优秀,但英文水平可能比较一般。标贝科技通过中英混杂的文本,成功构建了包含1000多种中英混杂音色的合成数据集(每个音色代表一种风格和特点)。
语音是标贝科技的传统优势领域,在视觉领域,标贝科技也实现了高质量数据标注的突破。
在今年4月份国家数据局的典型案例中,标贝科技“4D-BEV上亿点云标注系统”, 集成先进自动化标注技术,深度兼容4D-BEV感知算法,打造自研高性能标注平台,从空间、时序维度对车辆、行人和路标等目标进行多视角标注,能够轻松处理上亿量级点云数据。相比传统标注方式,标注效率提升约30%,准确性提高约20%,为自动驾驶行业发展提供了坚实的数据支撑。提供一站式AI数据服务方案,形成从数据采集、数据处理到评测调优全栈数据生产闭环流程,打造覆盖语音、图像、视频、点云等多模态的十余套自动驾驶数据集,积累上百万小时语音数据、100T图像视频点云数据,为自动驾驶行业发展提供高质量数据支撑。
李秀林博士指出,自动驾驶领域的数据标注,涵盖舱内与舱外。舱内包括驾驶员状态监测、行为识别等;舱外则涉及车道线、交通标志、行人、车辆等多类目标的检测与属性标注。随着技术进步,标注需求愈发细化,原本只需要标明两三个属性,现在则需要标明更多——如行人是否戴帽、车辆类型、是否有护具等,体现出行业对功能与安全的双重追求。
我们正在探讨下一代数据标注需求。比如说司机突然急刹车的“刹车动机”,是因为司机发生了走神、前面有行人经过,还是给后车让路?我们可以在数据标注和数据预处理的层面持续创新,更加科学、精准地反映司机举动的内在逻辑,并将其“编码”到数据里。

数据标注驾起业务与AI的桥梁
随着大模型越发深入产业,数据标注作为底层支撑,它的角色在发生微妙的变化。
尤其是在医疗、金融等专业领域,对数据标注的专业性提出了极高的要求。参与标注工作的人,也由一般的标注员,变成了高校教授、专业医院的医生、领域专家等。比如说一些细胞类数据的标注工作,需要由专业人士在显微镜的切片下才能完成。
数据标注的工作在无形之中,有效串联起了业务和AI的两方。“我们是‘算法与业务之间的翻译官’。”李秀林比喻道。“算法团队不懂业务,业务团队不懂算法——而我们两边都懂一点,还能把需求‘转换’成数据。”
例如,在游泳的运动场景中,需要测试心率和血氧等各类功能。虽然标贝科技的人员不是运动健康专家,但是要想采集到好的数据,需要了解业务流程、找什么样的人、如何组织测试工作。测试后如何对数据进行整理和标注,标注后的数据如何与模型结合,并最终服务业务。这套流程中,数据标注这个环节,有效衔接起了业务和算法的供需。
随着大模型技术应用迈向深水区,人工智能正在从“以模型为中心”转向“以数据为中心”。 国家发改委表示,到2027年,数据标注产业专业化、智能化及科技创新能力显著提升,产业规模大幅跃升,年均复合增长率超过20%。
对于数据标注产业的发展大势,李秀林博士表现非常乐观的态度,“我认为数据标注是一个长坡厚雪的赛道。算力、算法、数据是整个AI产业的核心,大模型发展到一定阶段后可能会遇到瓶颈期,那么这时数据可能会成为新的动力。所以我们不能只从数据方面思考,而是从整个行业的角度思考这个问题。将与客户共创,主动引领的方式为行业提供高质量的数据集,助力人工智能的落地。”
随着AI技术的不断成熟和应用领域的拓展,数据标注行业将迎来更广阔的市场空间。特别是在自动驾驶、智能医疗、智能金融等新兴领域,对于高质量的数据标注需求迎来爆发式增长。数据标注专业化、产业化水平将不断提升,这个曾经被视为AI产业中的“蓝领工作”,如今开始走向台前,成为推动大模型进化的“隐形引擎”。
来源:数据猿
刷新相关文章































































































我要评论
不容错过的资讯













大家都在搜


