
从“交易核心”到“数据核心”,国产数据库要换道超车丨数据猿专访
原创 月满西楼 | 2022-11-04 20:13
【数据猿导读】 一直以来,数据库都被国外科技企业垄断,并与芯片、操作系统合称为我国科技产业的三大“心病”。接下来几十年,都将是中国产业升级的关键时期。数据库,既是高附加值的科技行业,又是整个数字化大厦的关键基石,具有重要的战略意义。那么,国产数据库发展的如何?还存在哪些问题?突围的...

一直以来,数据库都被国外科技企业垄断,并与芯片、操作系统合称为我国科技产业的三大“心病”。接下来几十年,都将是中国产业升级的关键时期。数据库,既是高附加值的科技行业,又是整个数字化大厦的关键基石,具有重要的战略意义。
那么,国产数据库发展的如何?还存在哪些问题?突围的关键是什么?带着这些问题,数据猿采访了国产自研分布式数据库的代表企业巨杉数据库,从聚焦金融、银行的数据库厂商的角度深入的思考。
“数据核心”,国产数据库换道超车的
战略机遇,释放全量数据价值
数据库是一个有着几十年历史的行业,甲骨文、IBM等厂商在这个领域长期深耕,不仅建立了深厚的技术壁垒,更重要的是培养了完善的产业生态。在一众国际巨头的铁壁合围下,国产数据库虽然在持续努力,但始终未能突围。究其原因,是因为在过去的40年间,为了填补技术上形成的差距,国产数据库集中发展「交易核心」业务。这个场景下甲骨文、IBM等国际厂商已经领跑近20年,这就像两辆赛车在同一个直线跑道上比赛,前面的车已经领先很远,同时前车还在“进化”,后来者想要追赶不但需要加倍的能力提升,同时还要经过时间的长期洗礼。
所谓的“新赛道”,就是产业需求的重大转变,就如同汽车和高铁解决的是两种完全不同的需求场景。只有产业需求本身发生很大的变革,并出现全新的市场机会,老一代先行者的领先优势才会被抵消掉。
那么,这个“新赛道”出现了么?好消息是,数据库行业的变革正在发生,数字化不再仅仅关注单一的业务系统,跨系统的各类数据在全球数字化的推动下,提出了面向多类型全量数据实时应用的需求。因此推动数据库业界向分布式数据库、云数据库、湖仓一体架构、存算分离、流批一体化、多模数据一体化、交易分析一体化等新技术快速发展,技术日新月异。面对这些新技术,国内外厂商几乎处在相同的起跑线,在技术创新的“新赛道”上,给予了国产厂商与全球同期起步的战略机遇发展空间。
在巨杉数据库看来,传统数据库是以交易为核心的,而分布式数据库等新技术则是以数据为核心的,这会带来很多方面的不同。「交易核⼼」解决的是交易系统的问题,⾯向渠道、产品、客⼾、核算及清算等业务流程,确保业务闭环;而「数据核⼼」则面向交易过程产⽣的全量行为数据、流⽔数据等,依托分布式技术,解决数据的采集、整理、聚合、运⽤等问题。
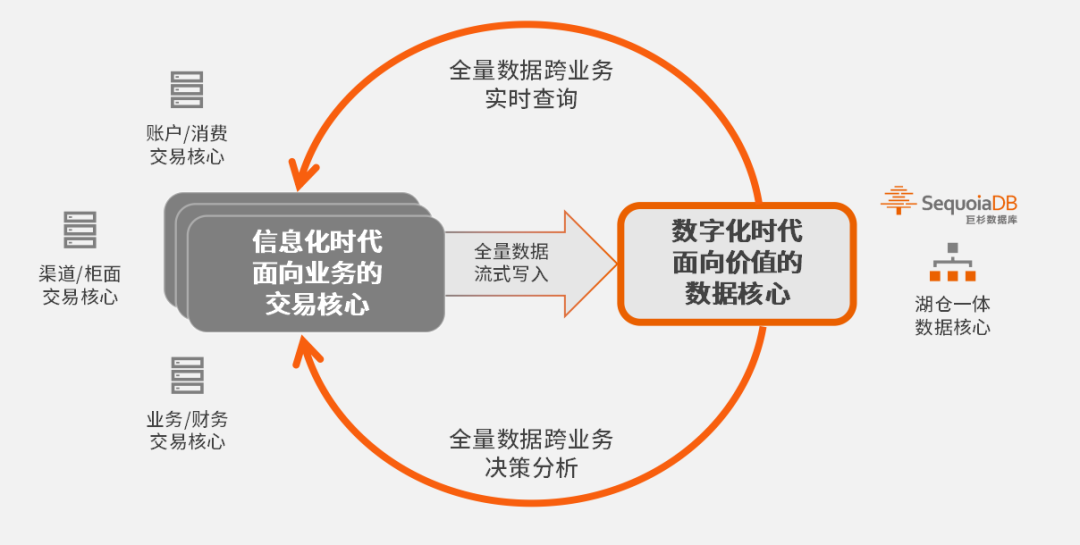
交易核心与数据核心,双核心驱动数字化发展 资料来源:巨杉数据库
这两类数据库在数据量、数据类型、时效性、业务范围等方面存在明显的差异。以数据量与数据类型为例,传统交易核⼼数据库往往仅保存余额、交易账单等业务的单⼀结构化交易结果数据,而数据核心数据库不仅保存交易结果数据,还保存跨业务的全量数据,包括每次余额变化、交易账单⽣成背后所衍生的⼤量结构化、半结构化流⽔记录,以及⼤量通过⾳视频、双录系统所产⽣的⾮结构化数据,这类数据的量级往往在交易结果数据的10倍以上。因而,数据核心数据库所要保存的数据量更大,数据类型更加丰富。面对如此巨量的数据,传统集中式数据库往往力不从心,而分布式数据库技术可以很好的解决这个问题。
巨杉数据库认为,数字化时代需要全新的「数据核心」,分布式数据库是其最佳的基础设施。为了提升分布式数据库的性能,我们还需要在以下几个方向持续发力:如何支持更多不同的数据类型(结构化、半结构化、非结构化的多模管理)、如何在全量数据下提供稳定高并发的查询能力使得分布式数据库成为跨业务系统的全量数据平台底座、如何在保障并发能力的前提下提供可扩展的分析能力等。
聚焦分布式技术的实时能力突破,
国产中国数据库“高铁”正飞驰
“新赛道”的战略机会点已经出现,但要抓住这个机会却并不容易。打铁还得自身硬,当“新赛道”出现的时候,还需要产品自身的性能足够优越,才能建立新的先发优势。值得欣喜的是,在分布式数据库这个赛道上,中国涌现了不少优秀的国产数据库厂商。在与国外产品的技术竞争中,国产数据库已在部分领域形成了差异化优势。
以巨杉数据库为例,由于提前10年完成前瞻洞察,巨杉数据库找到未来长期发展的数据核心,提前布局分布式的新赛道,10年来始终坚持“两个聚焦”,一方面聚焦分布式技术,一方面聚焦金融银行业。伴随金融行业过去10年对数据需求的发展,巨杉数据库在技术方面从「多模数据湖」,到「实时数据湖」,再到「湖仓一体」,持续进行技术架构的升级。目前,巨杉数据库⼴泛应⽤于⾦融、证券、保险、政府、能源、电信、交通等领域,企业⽤⼾总数超过1000家,其中在金融银行业付费客户已经超过100家。

巨杉数据库部分客户展示 资料来源:巨杉数据库
巨杉数据库⾃研原⽣分布式内核,⽀持⽆限弹性⽔平扩展。其核心产品SequoiaDB基于原生分布式数据库架构提供了弹性的横向扩展机制,可以根据业务需灵活扩展,其分布式数据库的存储层及计算层均支持弹性水平扩行能力。用户可以通过增加服务器数量或创建额外的数据库实例实现对应⽤的⽔平弹性扩张。目前,巨杉数据库不少商业客户的数据量规模都超过100亿行记录,容量达到百TB甚至更大,已在多个金融银行客户的生产环境中达到PB级的数据存储容量,单客户生产部署集群规模最高达到400台物理服务器,1.4万亿行数据记录。
如此多客户之所以选择巨杉数据库,关键在于其产品性能经受住了金融级考验。分布式数据库在全球来看都是新兴技术,同时在国内经济及互联网的高速发展下,在数据体量和增长上远超国外市场,从而产生了国内特殊的数据应用场景。海量数据所产生的创新需求,推动了底层数据库技术的发展,使国内在数据的业务创新上有着天然的基础优势,并跟在部分场景形成差异化优势,技术上领先于全球。以巨杉数据库为例,其在以下多个技术领域都进行了有益的探索:
「湖仓一体」技术架构。基于「湖仓一体」架构,巨杉数据库沉淀出⾯向实时数据湖、多模数据湖、湖仓⼀体平台三类场景,⽀持在同⼀个引擎上进⾏混合多模的数据存储,⽀持海量数据的⾼并发查询与处理等特性。SequoiaDB的「湖仓一体」技术架构,强调数据应该先全量入湖替代原有的ODS,并提供面向多模数据类型的实时对客的高并发结构化数据查询能力,及非结构化数据存取能力,形成可为跨业务提供服务的「实时数据湖」。基于「实时数据湖」能力,再提供增强的数据分析引擎, 达到「湖仓一体」的统一数据管理能力。
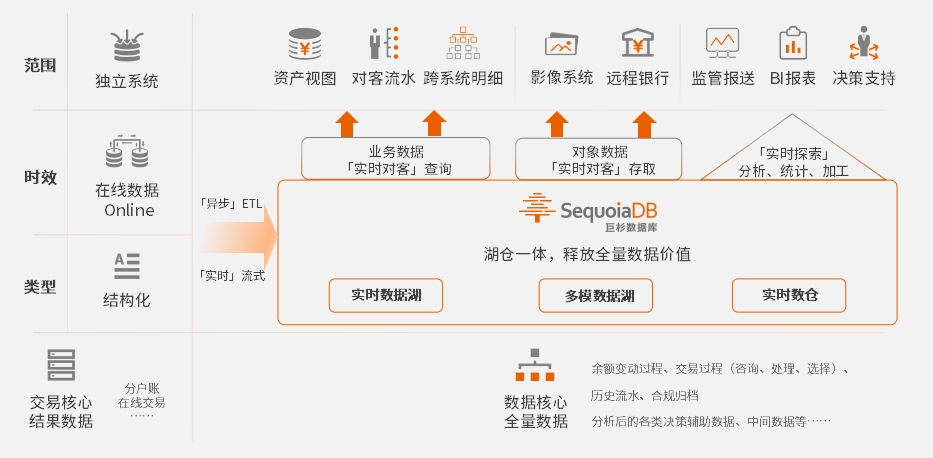
巨杉数据库湖仓⼀体架构⽰意图
实时对客。在巨杉数据库SequoiaDB最新发布的版本中,通过「湖仓一体」技术架构针对数据的实时应用提供了全面升级,让全量数据的价值从「内部离线」向「实时对客」进一步释放。
面向结构化数据,巨杉数据库提供深度的Join优化及列存微分区技术,在多个查询场景下,性能达到了毫秒级实时返回;分析场景中,性能更获得了10倍以上提升,让数据湖的查询分析更实时,实现查询更实时,所有数据可毫秒级访问。
面向非结构化数据,巨杉通过「分片并发」及「可变分区大小」的技术,实现非结构化数据存取更实时,吞吐量提升30%以上。
在运行监控方面,巨杉数据库SAC运维管理工具,基于分布式架构的实时诊断,有效提供全GUI(图形用户界面)的性能及故障分析能力,实现诊断更实时,业务问题分钟级定位。
此外,巨杉数据库还在存算分离、流批一体化、多模数据一体化、跨云平台等方面有诸多创新。
“交易核心”+“数据核心”,数字化的双核心
需要指出的是,虽然以数据为核心的数据库是重要发展方向,但并不意味着以交易为核心的传统数据库就不重要了。巨杉数据库认为,分布式数据库与传统数据库不是纯粹的替换关系,而会长期并存,共同为数字化的「交易核心」及「数据核心」解决基础数据设施的不同需求。
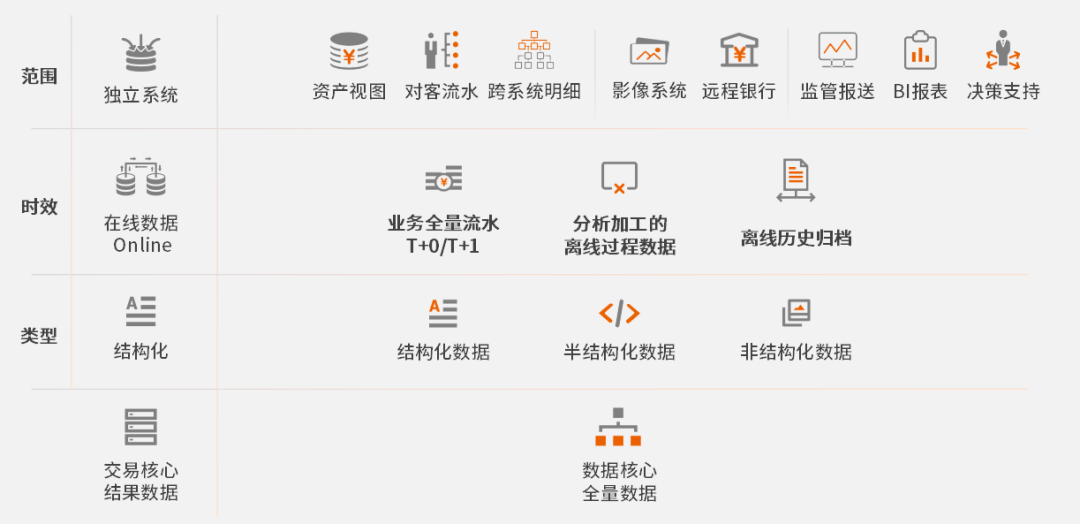
「交易核心」与「数据核心」对数据库的需求 资料来源:巨杉数据库
当前,「交易核心」的数据库的国产化替代是一个重要的场景,得到了政策重点关注。在这个场景下,Oracle、DB2、SQL Server经历了40年甚至更长时间的磨练及生态建设,存量系统迁移需要一定的时间周期。在“替换”的市场中,达梦、人大金仓等国产数据库厂商也经历了20年的产品迭代,相信基于市场的驱动,进一步建立新的生态,未来持续发展的前景是光明的。
在面向「数据核心」的创新发展方面,重点在于将新技术与客户创新的需求相结合,以此推动产品创新,形成与老一代产品的差异化发展。中国是世界上人口最多的国家。众多的人口及领先的移动互联网业务发展,也让中国成为数字化创新最快的国家,金融银行业的科技发展更是催生出领先于全球的行业需求。例如:巨杉基于中国金融银行客户需求,在“实时数据湖”方面,已经率先在超过万亿级数据量的生产系统中,稳定提供高达一万并发压力下,百毫秒内查询响应能力。可以说,巨杉的“实时数据湖”技术,已经领先于业界同类产品。基于客户需求的创新,将助力巨杉打开更大的市场机会及空间。
这一观点,与国外分布式数据库厂商的发展趋势不谋而合。海外大部分分布式数据库厂商都在致力于基于应用场景的创新,例如Snowflake专注于云上的数仓,即数据共享的应用创新;Databricks专注于湖仓一体融合,特别是对全新的AI、ML等科学计算的创新;MongoDB专注于JSON的文档半结构化能力创新;Redis专注于高性能缓存的创新。
中国的数字化发展,需要数据库产品聚焦不同的技术及需求场景进行深耕。一方面,要聚焦「交易核心」替代;另一方面,要聚焦全新的「数据核心」创新,与全球同步发展。如果说“替换”是解决底部基础,那“创新”就是要打破并创造新的天花板。
以国产数据库推进产业数字化,
打造数字经济的坚实基座
经济引擎在哪里,是中国接下来二三十年必须要回答的问题。中国人均GDP突破一万美元之后,要继续向上增长,以往通过中低端制造业打造全球工厂+房地产、基建拉动经济增长的方式,显然不太现实。经济的发展,如逆水行舟,不进则退。要跨过中等收入陷阱,中国就必须要找到新的发展引擎。
某种程度上,数字经济是中国未来经济的主战场。依据中国信通院提供的数据,近几年,数字经济在GDP中的占比也在逐年提高,从2015年的27%提高到2020年的38.60%,平均每年提升超过2个百分点。
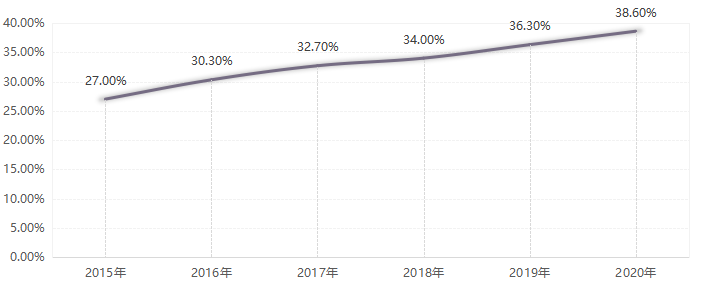
数字经济占GDP的比重数据来源:信通院《中国数字经济白皮书2021》
以数字化赋能传统行业,进而实现产业升级,是数字经济的核心。2020年起,我国信创产业进入大规模落地推广阶段。国家提出“2+8+N”信创体系:两个核心行业,党政+金融;8大关键行业,电信、电力、石油、交通、教育、医疗、航空、航天;N个其他行业。数据已经成为继土地、人力、资本、技术之后的生产要素,并在数字经济中的作用愈发凸显。承载海量数据的分布式数据库,则是整个数据价值链条的基础设施,影响着整个数字经济大厦的稳定性。而国产分布式数据库,则在保障数字化产业安全方面,发挥着特殊的作用。
现在正处于数据库产业变革的关键时期,并且中国有很好的发展数据库的土壤。依据中国信通院、中国网络空间研究院联合发布的《国家数据资源调查报告(2021)》,2021年我国数据产量达到6.6ZB,同比增加29.4%,占全球数据总产量(67ZB)的9.9%,仅次于美国(16ZB),位列全球第二。我们的互联网、移动互联网产业仅次于美国,物联网、车联网、工业互联网、5G网络建设走在全球前列,这些领域的发展都会对数据库产生巨大的需求。市场需求是产业发展的第一驱动力,我国海量的数据存储、处理需求,将极大的推动国产数据库的创新发展。我们有理由相信,在不久的将来,无论是「交易核心」数据库还是「数据核心」数据库,中国玩家的竞争力都将越来越强。我们不仅要在国内实现数据库的国产化替代,还要走向全球,去引领分布式数据库的发展浪潮。
文:月满西楼 / 数据猿
来源:数据猿



我要评论
不容错过的资讯















大家都在搜





