
英伟达的“围城”:云厂商自研芯片,攻到了哪一步?
原创 桑吉 | 2026-05-20 20:16
【数据猿导读】 英伟达的GPU有多难买、多贵,搞AI的人心里都有数。H100一卡难求,Blackwell还没捂热就被抢光。全球云厂商一边排着队给英伟达送钱,一边闷头在自家实验室里搞另一套方案——自研芯片。

“自研芯片真能帮云厂商敲开英伟达的铜墙铁壁。
英伟达的GPU有多难买、多贵,搞AI的人心里都有数。H100一卡难求,Blackwell还没捂热就被抢光。全球云厂商一边排着队给英伟达送钱,一边闷头在自家实验室里搞另一套方案——自研芯片。
这不是什么营销噱头。这是一场从“省点钱”到“自己说了算”的漫长博弈。走到今天,云厂商的芯片到底干到哪一步了?
算力饥荒与造芯自救:
三大驱动力
云厂商为什么非要自己造芯片?最直接的原因就是:太贵了。
自研芯片在推理场景下,总拥有成本能降30%到50%。谷歌就是个典型。2013年,首席架构师Jeff Dean算了一笔账:如果每个Android用户每天对着手机说三分钟话,用CPU跑语音识别,谷歌得把数据中心规模翻一倍。这笔账把他吓着了,于是TPU项目上马。15个月后,第一代TPU就进了数据中心。
第二个原因是供应链安全。高端GPU产能有限,还受出口管制,云厂商必须给自己留后路。国内的情况最典型,英伟达在中国的数据中心份额,从95%的高点一路往下掉,华为们趁机起来了。
更深层的是技术护城河。软硬一体优化,为自己的AI、数据库、视频转码定制算力,这事做成了就是竞争壁垒。腾讯的“沧海”转码芯片、阿里的“倚天710”CPU,都是这个思路。第三方机构预测,云厂商自研芯片的年复合增长率正在快速攀升。
谷歌、AWS、微软的芯片三国杀:
谁跑在了前面?
海外三巨头的路子各不相同。谷歌TPU出货最大,外部商业化最快;AWS Trainium已经长成几十亿美金的生意,客户版图扩张最猛;微软起步最晚,Maia量产一波三折,倒是Cobalt CPU走得还算稳。

谷歌TPU:出货量最大,生态闭环最完整
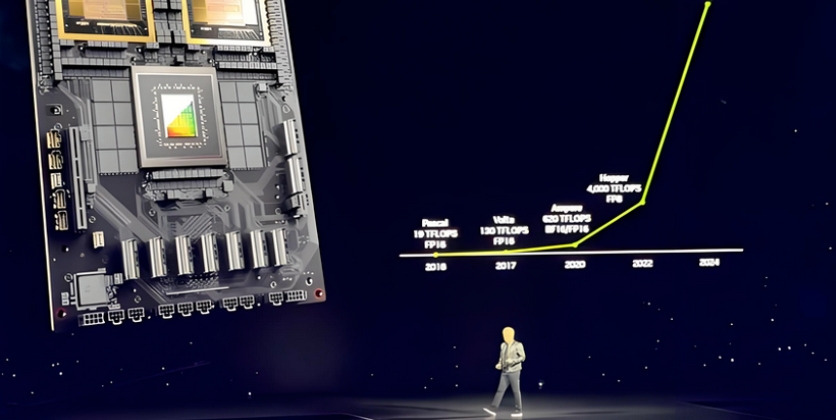
TPU的故事始于2013年那场算力危机。此后十年,谷歌闷头迭代了八代。v5代开始搞“双轨并行”:v5e打性价比,v5p主打训练。2025年底发布的第七代Ironwood,是谷歌第一款面向推理时代设计的主力芯片,FP8算力4.6 PetaFLOPS,比英伟达B200的4.5还高一点,单颗性能是v5p的10倍。单个超级Pod集成9216颗芯片,算力42.5 ExaFLOPS。内部用的话,单颗TCO比GB200低约44%。
2026年4月,谷歌发布了第八代TPU,首次将训练和推理拆分为两款独立芯片。训练款TPU 8t(Sunfish)用台积电2nm,博通设计,FP4算力12.6 PFLOPs,单个Pod 9600颗芯片,总性能121 ExaFLOPS,预计2027年底量产。推理款TPU 8i(Zebrafish)首次跟联发科合作,片上SRAM是Ironwood的三倍,通信延迟降低5倍。两款都搭载谷歌自研的Axion CPU,支持PyTorch原生迁移。
出货量方面,有非官方的市场分析预测,2026年TPU出货量约为150万–300万颗,乐观情形下或可达400万–500万颗。这背后不只是谷歌自用,Anthropic签了上百亿美元的协议,承诺用100万颗TPU;Meta签了数十亿美金的多年租用协议;苹果也在论文里承认,用8192颗TPU v4和2048颗v5p训练了Apple Intelligence的基础模型。
但谷歌的TPU不对外单独卖,生态比较封闭,还是依赖TensorFlow和JAX,跟英伟达的CUDA体系差得远。
AWS:Trainium业务已达数十亿美元
AWS自研芯片的起点是2015年收购Annapurna Labs,花了大概3.5亿美元。当时没人太在意,现在回头看,这是亚马逊芯片版图的钥匙。

首先做起来的是Nitro。2013年AWS发现,用Xen虚拟化方案,将近30%的CPU算力被系统开销吃掉了。收购Annapurna之后,2017年推出Nitro System,把虚拟化、网络、存储全卸到专用硬件上,客户可用算力从不到70%拉到接近100%。Nitro卡已经演进到第5代,每瓦性能提升40%。
推理芯片Inferentia2018年首发,第一代Inf1实例比可比GPU吞吐量高2.3倍,推理成本降70%。2026年4月,Inferentia3发布,性能再翻一倍。
训练芯片Trainium才是大头。Trainium2在2025年全面推出,性价比比可比GPU高30%到40%。AWS CEO Matt Garman表示 Trainium2 业务年化营收达数十亿美元级别。2025年10月,AWS跟Anthropic合作的Project Rainier在印第安纳州部署了近50万颗Trainium2芯片,到年底扩大到100万颗,专门训练Claude模型。2026年4月,Anthropic又加码,承诺未来十年在AWS上投入超过1000亿美金,覆盖Trainium2/3/4以及未来各代芯片。
Trainium3在2025年底re:Invent上发布,台积电3nm,每颗FP8算力2.52 PetaFLOPS,性能比Trainium2提升4.4倍,能效比提升4倍以上。2026年初正式出货,几乎满单。Trainium4的路线图也出来了,FP4吞吐量提升6倍,还支持跟英伟达NVLink Fusion混合部署。
亚马逊CEO Andy Jassy在2026年4月的股东信里说,AWS自研芯片业务(Graviton、Trainium、Nitro)年化收入突破 200 亿美元,机构预估分拆后峰值可达 500 亿美元。自研芯片累计收入承诺超过2250亿美金,覆盖Anthropic、OpenAI等客户。OpenAI也在2026年2月确认,将通过AWS消耗约2GW的Trainium容量。
需要说明的是,AWS的自研芯片主要通过云服务提供,客户买的是算力不是芯片。与此同时,AWS也在大规模采购英伟达GPU,两边不矛盾。
微软:Maia出师不利,起步太晚
相比谷歌和AWS,微软的进度明显慢了。

2023年11月,微软高调发布Maia 100和Cobalt 100。Maia 100用台积电5nm,理论算力1600 TFLOPS MXInt8和3200 TFLOPS MXFP4。但数字好看没用,据The Information报道,Maia 100发布后只做了内部测试,并未实际投产。原因较为复杂:其设计始于2019年,当时主要针对图像处理任务优化,对后来爆发的大模型支持不足;此外,后续芯片Braga在开发过程中遇到设计频繁变更、芯片模拟不稳定以及团队人员流失等问题,导致量产至少推迟了六个月。
Maia 100的拉胯直接拖累了后续芯片。微软原本计划Braga在2025年量产,结果推迟了至少六个月。原因包括OpenAI在开发后期不断提新需求导致设计频繁变更、芯片模拟不稳定,以及团队约五分之一人员流失。
2026年1月,微软终于发布了Maia 200,定位改成“AI推理主力”。Maia 200有超过1000亿个晶体管,FP8性能约5 PetaFlops,每美元性能比上一代提升30%。微软声称它的FP4性能是亚马逊第三代Trainium的三倍。目前Maia 200已在微软中部Azure区域部署,但初期还是内部用例为主,首批用户是微软自家的Superintelligence团队和OpenAI。全面向客户开放,还要等。
反倒是Cobalt CPU这条线走得稳。Cobalt 100是5nm ARM处理器,性能功耗比x86同类实例高50%,已经在Teams、Azure SQL里用了,外部客户包括Adobe、Databricks、Snowflake。覆盖了Azure约一半的区域。下一代Cobalt 200设计已完成。
据Digitimes Research统计,2026年微软自研AI芯片预计出货33万颗,在四大云厂商里垫底。摩根士丹利说,微软在自研芯片上的滞后,让它跟亚马逊、谷歌的云计算竞争中处于不利位置。不过微软砸钱不含糊:2025财年投了800亿美金建AI数据中心,2026年3月又跟英伟达签了采购100万颗GPU的多年协议。
三家海外巨头有个共同点:先推理后训练,先内部后外部。推理是自研芯片最先撕开的口子——推理任务针对特定模型优化,不需要训练那么强的通用性,正是ASIC的用武之地。训练侧短期内还是离不开英伟达的CUDA和NVLink。
TrendForce预测,2026年ASIC市场整体增长率44.6%,远超GPU的16.1%,ASIC份额有望从20.9%升到27.8%。这场“三国杀”的终局,比的不是谁先出牌,而是谁能率先在推理时代把自研芯片做成主力。
从“备胎”到“主力”:
国产自研芯片的真实段位
如果说海外云厂商自研芯片是为了省钱和效率,那国内厂商就是被逼出来的。A100、H100被禁,H20出口受限,国内AI芯片一年缺几百万张,国产替代的窗口突然就打开了。
据IDC数据,2025年中国AI加速卡总出货约400万张。英伟达还是第一,约220万张,但份额从95%暴跌到55%。AMD出货16万张,占4%。本土厂商合计出货165万张,首次突破40%。其中华为昇腾81.2万张,独占国产近一半;阿里平头哥26.5万张;百度昆仑芯和寒武纪各11.6万张;海光信息8万张。国产阵营的基本盘,已经清楚了。

华为昇腾:制裁下的逆袭
昇腾是国产芯片里体量最大的。2019年,昇腾910商用,7nm工艺,FP16算力256 TFLOPS,直接对标英伟达V100,号称当时全球最强AI处理器。后来910B、910C持续迭代,910C用双Die封装,把两颗910B封在一起,算力800 TFLOPS(FP16),国产化率约55%。
2026年3月,华为正式发布昇腾950PR,首次引入FP8/FP4低精度格式,FP4算力1.56 PFLOPS,大约是英伟达中国特供H20的2.87倍。更重要的是,950PR在CUDA兼容性上做了实质性提升,让习惯了英伟达生态的开发者迁移起来容易了不少。
软件生态上,2025年8月,华为宣布CANN算子库和工具链全面开源,轮值董事长徐直军直说:让昇腾“更好用、更易用”。到2025年底,CANN已经跟90多个开源社区深度对接。当然,CUDA有18年的先发优势和数千万开发者,CANN要追上还早。但950PR的兼容性突破和CANN的开源,至少打开了一个口子。
出货量上,2025年昇腾81.2万颗,占国内整体市场20%,占国产近一半。2026年Q1已经出了15万张910系列卡,全年目标更激进。到2026年Q1销售额口径,昇腾市占率升到35%到40%,而英伟达的份额相比此前大幅下降。

阿里平头哥:47万片交付,六成卖给外面
平头哥的路子很务实。2019年9月,含光800推理芯片发布,在ResNet-50测试里性能比业界最好芯片高4倍,能效是第二名的3.3倍。2021年推出倚天710服务器CPU,5nm工艺,当时处于领先水平。
2026年1月,平头哥官网上线“真武810E”高端AI芯片,自研架构,96GB HBM2e内存,片间互联带宽700GB/s,能跑训练、推理和自动驾驶。业内人说,真武整体性能跟英伟达H20差不多,市场供不应求。
2026年3月,阿里CEO吴泳铭在财报电话会上说,截至2026年2月,平头哥自研GPU累计规模化交付47万片,年化营收百亿级别,60%以上卖给了外部客户,服务400多家企业。真武PPU已经在阿里云上了多个万卡集群,客户包括国家电网、中科院、小鹏汽车、新浪微博等。千问大模型的训练和推理也跑在真武上。IDC 2025年数据里,平头哥出货26.5万颗,国产第二。

百度昆仑芯:省钱的起点,性价比突围
昆仑芯的故事起点很朴素——省钱。李彦宏在2023年一个论坛上算过账:买别人芯片1万美元一片,自己造只要2万人民币。“所以就逼着自己做。”2011年,百度内部启动了FPGA AI加速器项目,团队后来成了昆仑芯的核心。
2021年,昆仑芯从百度分拆独立,芯片首席架构师欧阳剑当CEO。2024年推出第三代P800,自研XPU-P架构,INT8算力256 TOPS,16GB HBM内存。P800对MoE架构特别友好,单机8卡就能跑671B参数的大模型,这在业内算比较领先的。
2025年2月,百度智能云点亮了昆仑芯P800万卡集群,国内自研芯片里第一个;4月又点亮了国内首个全自研3万卡集群。2025年8月,昆仑芯中标中国移动AI服务器集采,在“类CUDA生态”标段拿了70%、70%和100%的份额,合计超10亿元。2025年营收约35亿,接近盈亏平衡,高盛预测2026年能到65亿。IDC数据里,2025年昆仑芯出货11.6万颗,跟寒武纪并列国产第三。2026年5月,昆仑芯正式启动科创板上市辅导。

腾讯的“三芯”战略:自研专用,外部补位
腾讯走的路跟别人不一样:自己不做大而全,而是内部做专用芯片,外部投资补通用算力。
2021年11月,腾讯首次披露三款芯片:AI推理芯片“紫霄”、视频转码芯片“沧海”、智能网卡芯片“玄灵”。紫霄在腾讯会议实时字幕场景里,处理能力是T4的两倍,成本节省超45%。沧海在MSU硬件视频编码比赛中包揽两个赛道8项评分全部第一,压缩率比市面标品高35%以上,已经部署了数万片。玄灵实现了主CPU“0占用”,性能提升4倍。
除了自研,腾讯还是燧原科技的第一大股东,持股20.26%。燧原的产品已经在腾讯云、游戏等核心场景大规模部署。但燧原对腾讯依赖很深——2023年对腾讯销售额占总营收33.34%,2024年37.77%,2025年飙到80%以上。燧原至今没盈利,2022年到2025年前三季度累计亏损51.79亿,正在冲刺科创板IPO。
2026年4月,据路透社报道,腾讯跟阿里、字节一起启动了昇腾950PR的紧急采购,带动950PR价格上涨约20%。腾讯现在是三条线同时跑:自研专用芯片、投资绑定训练算力、采购国产通用算力。布局广度不是最深的,但调度灵活度值得关注。
四家国产厂商都先从自己的业务场景里把芯片跑通,再往外走。但在英伟达新的AI加速卡恢复对华销售之前,国产厂商能争取到多少时间窗口,能在多大程度上缩小跟英伟达的生态差距,是这轮国产替代能不能走到第二程的关键。
从训练到推理:
AI算力战场正在悄悄转移
云厂商自研芯片之所以能在短期内看到成效,与AI负载结构的变化密不可分。
训练场景仍是英伟达的主场。前沿大模型需要巨大的算力、高速的互联带宽和成熟的软件生态,英伟达的CUDA生态和NVLink互联技术在此优势难以撼动。但在推理场景中,自研芯片的成本和能效优势开始显现。推理任务往往针对特定模型进行优化,不需要训练那样的通用性和灵活性,这正是ASIC类芯片最擅长的领域。

TrendForce预测,TrendForce预测,2026年ASIC在AI服务器加速方案中的出货占比将从20.9%升至27.8%,而GPU的占比相应下降至69.7%(2025年为75.9%)。
另一个不容忽视的趋势是:如果未来AI训练范式从“大炼模型”转向稀疏模型、小模型加多模态的方向,推理侧的算力需求将进一步爆发,自研芯片的机会窗口也将进一步扩大。
打破CUDA城墙
还差几步?
需要强调的是,以上所有自研芯片的快速增长,主要集中在推理侧。在训练侧,CUDA生态和NVLink互联仍然是难以绕过的壁垒。云厂商自研芯片会成为AI算力体系的重要补充,并在推理、视频转码、数据库等特定负载中分走一部分需求,这已是不可逆的趋势。但从“补充”到“替代”,还有很长的路要走。
CUDA生态壁垒是最大的障碍。英伟达用二十年的时间搭建了数千种工具、编译器与库组成的软件体系,全球累计数亿块设备接入,形成了“装机量-开发者-生态”的强劲飞轮。开发者基于CUDA开发应用,形成对英伟达硬件的深度依赖。
互联技术也是关键瓶颈。英伟达的NVLink和NVSwitch在集群互联性能上大幅领先。硬件互联之外的配套软件工具链,同样需要时间和大量投入才能补齐。
未来三到五年,AI算力市场很可能形成这样的格局:英伟达继续主导训练与通用AI计算,云厂商自研芯片形成“第二算力源”。这不是一场非此即彼的替代战争,而是一场从芯片硅片到软件栈的全方位生态竞逐。谁的生态更开放、谁的工具链更易用、谁能在推理时代率先规模化落地,谁就能在这场博弈中拿到更大的份额。
来源:数据猿




























































































我要评论
不容错过的资讯















大家都在搜


