
押注生成式AI,商汤科技要“腾笼换鸟”
原创 月满西楼 | 2024-04-01 20:15
【数据猿导读】 进入2024年,大模型和生成式AI的迅速崛起,正在重新定义技术和商业竞争的边界。在中国市场,有这样一个问题——谁能成为中国版的OpenAI?

进入2024年,大模型和生成式AI的迅速崛起,正在重新定义技术和商业竞争的边界。在中国市场,有这样一个问题——谁能成为中国版的OpenAI?
在这个关键时刻,商汤科技的2023年财报成为了业界关注的焦点。尽管财报显示其收入34亿人民币,同比下降11%,这背后实际上是一场深思熟虑的转型——一次“腾笼换鸟”式的业务结构变化。商汤科技主动缩减了其曾经占主导地位的智慧城市业务,将资源和焦点转移到了快速增长的生成式AI领域。
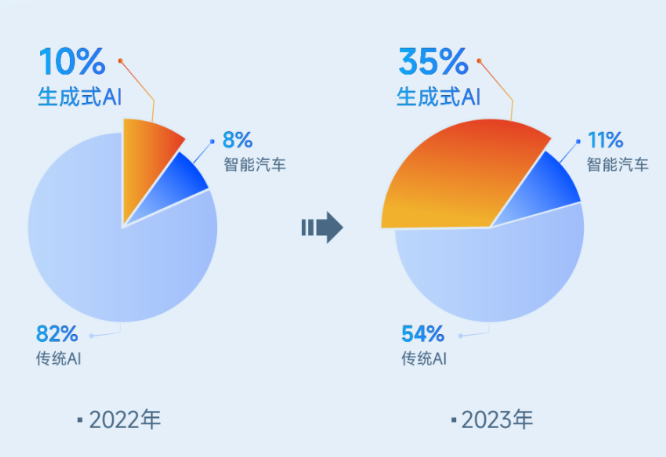
商汤科技各业务板块收入占比变动情况 数据来源:商汤科技财报
这一转变标志着商汤科技已经迈入一个全新的发展阶段,如此看来,它已经不再是人们记忆中的那个商汤科技了。那么,商汤科技变成了什么呢?
AI大装置+大模型双轮驱动,生成式AI高速增长
推出大模型的公司很多,但能这么快通过大模型赚钱的公司却很少。如果说2023年是生成式AI的技术元年,那2024年就是商业落地元年。而商业落地的成败,最核心的评价指标就是能否兑现足够的业务收入。
财报数据显示,商汤科技生成式AI收入贡献较多,达到了12亿元,增速达到了200%。据悉,这也是商汤成立以来,以最快速度从无到有、超过10亿收入体量的新业务。
如何实现?深入分析其业务特征,可以发现,商汤科技在生成式AI领域的增长逻辑,可以归结为:在感知智能、决策智能的长期积累,加上大装置与大模型的深度协同。
一方面,技术实力是基础。
生成式AI的成功商用,核心依赖于其技术的成熟度和实用性。在技术层面,生成式AI需要具备强大的理解、推理和创造能力,这不仅要求模型能够处理和生成前所未有的复杂数据类型,还要求其能在多变的应用场景中保持高效和准确。
然而,生成式AI面临的技术难点不少。例如,模型泛化与适应性就是一大难题,虽然当前的生成式AI模型在特定任务上表现出色,但在面对新领域或新问题时,模型的泛化能力和适应性仍有限。模型需要在保持高性能的同时,具备跨领域应用的能力;数据偏差也是一个严重问题,可能导致模型生成带有偏见的结果;生成式AI的强大能力也带来了潜在的风险,如生成不准确或有害的内容,则可能面临业务合规的挑战。要解决这一系列问题,需要深厚的技术积淀才行。
在过去十年中,商汤科技深耕于感知智能和决策智能,积累了丰富的多模态数据资源,这些不仅增强了其基础模型对物理世界的理解能力,也极大地提升了模型处理多种数据类型的能力。特别是商汤科技推出的“日日新”大模型,在基础模型构建、多模态理解、编程语言处理、工具调用,以及处理百万字级无损上下文信息等方面,达到了业内领先水平。
“日日新”4.0版本在多个应用场景中展现出的能力,如代码编写、数据分析、医疗问答等,不仅与GPT-4持平,甚至在某些方面超越了它。。
另一方面,算力是大模型最大瓶颈,AI大装置SenseCore成为商汤科技攻城拔寨的“弹药库”。
大模型训练的本质是一个计算密集型过程,对算力的需求极其庞大。这种对算力的依赖,使得掌握足够算力资源的企业,能够在生成式AI的研发和应用上取得先机。在这个意义上,算力成为了企业在生成式AI领域进攻和防守的重要“弹药”。风险资本投资大模型创业公司,最关键的就看两个指标,一个看公司有没有厉害的人才,另一个就是看公司手里有没有足够的算力。
对于商汤科技而言,其AI大装置SenseCore的建设和运营,昭示着公司在算力资源配置上的战略远见。财报数据显示,商汤科技的算力规模已经达到了12,000 petaFLOPS,拥有45,000卡GPU。通过庞大的算力支撑,商汤科技成功实现了对万亿参数级别大模型的有效训练,从而为公司在生成式AI领域的快速发展奠定基础。
在AI大模型领域,有一个著名的“尺度定律”(Scaling Law):随着模型大小(如参数数量)、数据集规模、或计算资源(如训练时的算力投入)的增加,模型的性能(如准确率、生成质量)通常会呈现出持续改善的趋势,这包括但不限于更好的泛化能力、更强的推理能力和更高的任务解决效率。
尺度定律,推动了AI大模型规模的不断扩大。然而,模型规模的增加也带来了算力需求的急剧上升。这要求算力大装置不仅要有足够的计算资源,还需要具备高度的可扩展性和弹性,以适应模型规模的快速增长。同时,如何在保证模型性能提升的同时,控制训练成本,避免算力资源的无效消耗,成为算法与算力协同过程中需要解决的重要问题。
商汤科技的AI大装置SenseCore+“日日新”大模型的协同,则是遵循尺度定律的典型案例:“日日新”大模型在万卡算力的保障下,遵循尺度定律不断提升性能;而源于大模型研发的深刻理解,帮助商汤更有前瞻性地设计基础设施,实现领先同行的算力效率和弹性。
需要指出的是,商汤科技所实现的这种协同,不仅是简单的算法优化和硬件升级,而是一个涉及计算架构、模型设计、算法效率和资源管理等多个层面的复杂系统工程。算力大装置的设计需要考虑到模型架构的特点,以及模型训练和推理过程中的计算需求。这意味着,计算架构必须能够灵活适应不同的模型设计,支持并行计算、分布式训练等技术,从而实现模型训练的高效率和低成本。同时,大模型的设计也需要考虑到算力的限制,通过模型压缩、量化、稀疏化等技术降低对算力的需求,提高模型的运算效率。通过改进模型训练算法、引入更高效的优化器和调度策略,可以在不增加额外算力的情况下提升模型的训练速度和质量。
聚焦大模型推理,快速推进商业落地
上面,我们分析了商汤科技的基本能力。要实现可持续发展,需要将这些能力实现商业落地。一个公司要在市场中立足,首先是要找到自己在产业中的位置。那么,商汤科技将自己定位在哪里呢?
商汤科技董事长兼CEO徐立,在2024全球开发者先锋大会(GDC)中提出的“大模型能力的三层架构”理论,为理解商汤科技的大模型应用策略,提供了重要视角。
一般来看,大模型可以分为三层能力框架,分别是知识层、推理层和执行层。
其中,第一层是知识层,大模型通过对海量数据的学习,吸收世界知识,形成对不同领域知识的全面理解。第二层是推理层,在知识层之上,推理层使得AI能够在掌握大量知识的基础上进行逻辑推理和决策。第三层是执行层,关注如何将AI的知识和推理能力转化为具体行动,与现实世界进行互动。这涉及到AI在物理环境中的操作能力,如自动驾驶、机器人控制等。
其中,推理层在生成式AI体系中起着至关重要的作用,通过对海量数据中抽象模式的逻辑演绎和推演,推理层使AI能够在面对未曾遇见的问题时,提出创造性的解决方案。此外,推理过程本身的反馈还能促进知识层的持续优化,形成一个动态学习和进化的闭环。因此,推理层不仅是AI智能处理的核心,也是实现AI技术深度商业落地和跨越式发展的关键。
商汤科技正是聚焦于推理层,将生成式AI深度融入到各个行业和领域中,并取得了不菲“战果”。在C端,商汤科技的大模型C端调用量,在过去半年呈现出近120倍的增长;在金融、医疗、Copilot助手、拟人交互、智能终端等B端应用中,商汤科技的大模型不仅提供了决策支持,更在复杂的数据分析和处理中展现了出色的能力,其客户涵盖中国银行、招商银行、中国工商银行等金融机构,上海交通大学医学院附属新华医院、瑞金医院以及郑州大学第一附属医院等医疗机构,金山办公、小米、荣耀等领域头部企业。

商汤科技生成式AI典型客户
我们可以通过一个具体的客户应用案例,来看商汤科技的生成式AI技术,如何赋能客户。
客户案例:上海银行,基于大模型打造AI数字人,降低服务门槛。
上海银行,在其数字化转型过程中遇到了双重挑战:一方面,需要在有限的人力资源下满足日益增长的、多样化的金融服务需求;另一方面,银行面临着如何缩小数字鸿沟,尤其是对年长客户群体而言,普及和降低数字服务的使用门槛成为了迫切需求。这些痛点不仅关系到服务效率和覆盖范围的提升,也关乎客户体验的全面优化。
针对这些挑战,商汤科技提供了基于日日新大模型体系的解决方案,通过打造AI数字人员工“海小智”和“海小慧”,深度整合了生成式AI的前沿技术。这两位AI数字人员工不仅具备高度拟人化的表达和互动能力,还通过对2000条问答数据和10万条语料数据的深度学习,实现了对客户需求的精准理解和响应,显著提高了服务的可及性和个性化。
目前来看,该方案应用效果显著,特别是对于上海银行60岁以上的客户群体,「“海小智”和“海小慧”有效降低了使用门槛,使得老年客户也能轻松享受到手机银行的便捷服务。此外,这一方案还极大地提升了客户服务的效率和质量,在不增加人力资源的情况下,实现了更高频次的客户交互和服务满足。
商汤科技的天花板,更高了
通过分析商汤科技的发展历程和其业务特征,我们发现其与OpenAI有诸多相似之处。
OpenAI自2015年成立以来,通过不断的技术创新,推出了一系列引领行业发展的生成式AI产品,如GPT系列。直到推出ChatGPT,OpenAI迅速出圈,奠定了自己在AI市场的地位。
商汤科技成立于2014年,比OpenAI还早一年“出生”。成立以来,商汤科技也依托其在计算机视觉、深度学习等方面的深厚技术积累,持续推动技术创新。2023年,商汤推出在生成式AI领域的“日日新SenseNova”系列产品,展现了其在AI技术创新上的实力,并迅速实现商业突破。
在直接的大模型竞争方面,商汤科技正加紧追赶OpenAI的脚步。商汤新近发布的 “日日新SenseNova 4.0”不仅在知识覆盖、推理能力、长文本理解、数字推理以及代码生成方面实现了全面升级,还引入了支持跨模态交互的能力。
尤其值得注意的是,“日日新·商量”大语言模型通用版本(SenseChat V4)在综合评测中与GPT-4不相上下,甚至在某些关键领域如推理和代码编程方面超越了GPT-4。特别是在HumanEval Coding测试中,其一次通过率达到75.6%,超越了GPT-4的74.4%。在医疗领域,“大医”模型在两项行业权威评测中均获得了第二名的好成绩,性能接近乃至部分超越了GPT-4。

SenseChat V4与GPT4、GPT3.5对比 数据来源:基于Opencompass full全集测试
看完技术比较,我们再来看看商业化成果。根据《路透社》报道,OpenAI在2023年一整年的营收16亿美元,商汤科技营收4.7亿美元(34亿人民币,汇率:1 美元 ≈ 7.2 人民币),约为OpenAI的30%;如果只算商汤科技的生成式AI收入,则有1.7亿美元(12亿人民币),超过OpenAI的10%。
而算市值,商汤科技为30亿美元(234亿港元,2024年3月27日市值),不到OpenAI近1000亿美元估值的3%。如果再考虑到商汤科技在生成式AI领域200%的增速,目前商汤科技的价值被严重低估。
2024年,商汤科技迎来了10周岁生日,这也成为他转变的一个契机。商汤在财报中阐释了下一步计划,推动业务增长和核心业务盈利,稳健而前瞻地占据AI 2.0时代竞争优势地位。
来源:数据猿














































我要评论
不容错过的资讯














大家都在搜







