
【金猿案例展】某保险公司——亚信科技大数据产品,助其数据管理 高效运营
原创 亚信科技 | 2021-12-27 23:30
【数据猿导读】 在我国产业升级转型、全面建设数字经济的当下,数据成为重要生产要素,《“十四五”规划和2035年远景目标纲要》、《关于加快推进国有企业数字化转型工作的通知》等纲领性文件,开启了国有企业数字化转型的新篇章。在政策导向下,保险机构加快了数据中台建设,以激发数据要素的生命力与活...

从保险机构自身来看,其产品的售卖渠道不再全然依赖于线下,线上渠道在技术的推动下蓬勃发展,数字化转型成为每个保险机构最重要的课题。另一方面,用户数据的收集、积累成为保险公司进行产品设计、风险控制的基础。
在国家政策指导下,以及业务增长及市场竞争需要,企业“内部高效运营与治理、外部精准拓客与挖潜”需求日益凸显。从完善公司内部系统、统一数据标准、强化数据完整度,加强数据管理和经营分析能力等方面考量,亟需建设一套数据管理平台,以实现数据中台体系的落地执行。
实施时间:
2021年3月进行整体规划方案,4~6月份进行技术方案设计与开发,7月进行产品实施,8月开始进行联调测试,9月底第一阶段上线试运行并交付使用。
某保险公司希望通过建设企业级的数据中台能力,推进公司信息化建设及大数据应用,在业务转型、经营决策与管理、日常运营等方面发挥价值,高效支撑保险数据资产管理、业务应用与市场拓展,提升核心竞争力。该数据管理平台能够整合全量数据和离散的数据分析、应用等功能;建立统一的数据处理规则、接入标准和应用规范;形成统一的数据采集、处理与运维体系;建设企业级数据管理平台,基于保险业务与运营数据、收入与成本数据形成统一的价值指标体系,为基于大数据的批量处理、实时查询、统计分析、移动分析和大屏展示等提供支持。具体应用场景包括:
1. 决策支持——构建全局监测体系,识别经营风险、发展趋势、竞争态势,为企业战略决策、经营方向提供支撑,通过可视化的开发配置,将数据以大屏的形式进行展示。
2. 运营支撑——为各种业务开展提供从业务检测、发现、优化的数据支撑能力;构建自助式的数据分析,提升整体数据的应用能力;为员工提供数字化的支撑,提升员工的工作效率。
3. 数据驱动——通过数据驱动,实现系统与系统之间的自动协助,高效赋能保险业务开展。
4. 数据生态——通过数据服务,为保险内外部系统如前台系统、合作伙伴系统等提供数据查询、消息服务,打造健康发展、充满活力的生态环境。
一. 原系统中的数据库产品:
1. 随着接入的数据越来越多,原系统中友商数据存储和处理的成本越发高昂。
2. 现有基于关系型数据库的数据归并逻辑较复杂、不易扩展维护;对计算存储资源消耗较大,面临扩展瓶颈;新接入的数据较难融入现有数据架构,不易扩展。
3. 现有的数据加工处理耗时过长,导致无法支持前台应用数据及时展示。
二. 前台应用:
1. 应用形式单调,无法支持大屏、手机端应用。
2. 使用的前端产品存在非自主可控,开放程度低,且技术相对陈旧,原厂支持已停止,漏扫安全问题无法解决。
三. 采集和加工:
1. 目前内部生态系统中拥有众多数字资产,这些资产作为单独个体只在公司运营过程中的某个范围内发挥作用,对数据接入的完整性和实时性造成影响。
2. 采用开源ETL工具支撑作为数据采集、加工、调度,影响运行并发数据控制。
四. 数据管理:
1. 缺少指标的管理。前台应用看到的指标存在同名不同义或同义不同名,数据指标不一致。
2. 缺少全局的数据表管理支撑,无法查看数据来源、去向,数据资产分布、存储及运营情况无法进行全景展示。
3. 生产库、备份库与模型设计文档表结构不一致,存在两张皮的问题。
从保单、客户、交易、财务等方向将企业业务数据进行了梳理,整体数据模型采用了模型分层的设计思想,分为基础数据层(ODS)、基础模型层(DWD)、融合模型层(DWA)及展现层(ST)四层数据模型架构。涉及结构化、半结构化及非结构化数据存储,目前总体存储近100T。同时,为了支撑实时风控、实时营销等场景需求,将个人保单、集体保单、赔付实付等时效性需求较高的数据,通过实时的数据捕获加工处理方式,代替T+1的数据接口处理,提升系统的整体处理的时效性。
一、应用技术
数据管理平台定位汇聚企业内外部业务数据,向企业内部员工提供报表分析、自助查询、手机分析等应用,同时为企业内部系统提供数据服务,释放数据价值。系统架构分层如下:
采集计算层:实现批量与实时数据采集、加工处理,为数据中心提供的数据接入与处理支撑。
存储层:通过设计存储模型,提供结构化、半结构化及非结构化数据的存储支撑,包括大数据平台和MPP数据库。
应用层:是最终数据成果和应用的运行环境。
管控中心:为对整个平台的资源、数据、维护、安全提供统一的控制管理中心,保障系统安全、可靠运行。
其中使用的关键技术如下:
1、通过Hudi实现实时数据存储与查询
Hudi上同时实现了Copy On Write和Merge On Read的两种数据格式,其中Merge On Read是为解决他们的fast upsert而设计的即每次把增量更新的数据都写入到一批独立的delta文件集,定期地通过compaction合并delta文件和存量的data文件,可以支持插入更新等操作。

图:总体数据流(全量,实时,增量)
批处理:源业务系统数据通过ETL工具,将数据装载到ODS(Hudi)层中,用SparkSQL进行后续各层数据的加工处理与应用。
流处理:源业务系统通过OGG方式,将实时数据同步至Kafka中,实现ODS层实时数据的存储。之后通过Flink消费Kafka中的消息,将实时数据同步至AntDB表中,用于后续实时报表的加工处理、实时查询等。
2、OGG实时数据同步
OGG是一种基于日志的结构化数据复制软件,能够实现大量交易数据的实时捕捉、变换和投递,实现源数据库与目标数据库的数据同步,保持最少10ms的数据延迟。

图:OGG实现原理
OGG主要进程包括Manager进程、源头抽取进程Extract、源头推送进程Pump、目标端接收进程Collector、目标端复制进程Replicat。
(1)Manager进程是GoldenGate的控制进程,运行在源端和目标端上。它主要作用有以下几个方面:启动、监控、重启Goldengate的其他进程,报告错误及事件,分配数据存储空间,发布阀值报告等。在目标端和源端有且只有一个manager进程;
(2)源头抽取进程Extract:Extract运行在数据库源端,负责从源端数据表或者日志中捕获数据;
(3)源头推送进程Pump:Data Pump进程运行在数据库源端,其作用是将源端产生的本地trail文件,把trail以数据块的形式通过TCP/IP 协议发送到目标端,这通常也是推荐的方式。pump进程本质是extract进程的一种特殊形式,如果不使用trail文件,那么extract进程在抽 取完数据以后,直接投递到目标端,生成远程trail文件;
(4)目标端接收进程Collector:Collector进程运行在目标端,其任务就是把Extract/Pump投递过来的数据重新组装成远程ttrail文件;
(5)目标端复制进程Replicat:Replicat进程运行在目标端,是数据传递的最后一站,负责读取目标端trail文件中的内容,并将其解析为指定消息格式,然后写入到kafka中。
根据保险实时报表的业务需求,可将OGG接入表分为:准实时表、主键变更表。
(1)准实时表:根据准实时接入表信息,加工统计实时报表数据,方便业务实时查询和统计分析;
(2)主键变更表:保单号等主键发生Update操作时,需要通过OGG实时同步至Kafka中,及时更新数据管理平台中的数据,解决源系统和数据管理平台主键信息不一致问题;
在通过OGG进行数据同步时,不区分准实时表和主键变更表,统一以相同方式接入即可,后续由数据管理平台按照实际需要,对接收到的kafka消息进行相关业务处理。
3、实时数据模型设计
在数据建模的过程中,需要充分考虑业务范围的变化、性能指标的变化等。例如未来将可能接入政府、保监会等外部数据,PB量级数据、万级标签、即席查询、在线探索等业务要求,也对数据建模提出了更高的要求。在大数据建模过程中,应以适变的理念建设构建模型,适应内外部变化。
同时,数据模型支持对模型的迭代性演进,当业务需求提出新问题或有新的数据加入模型时,数据模型能够比较灵活、快速的扩展,对现有系统冲击较少。数据模型按照分层分域思路设计,支持业务通用性,针对业务的可变性,支持模型横向和纵向的可扩展。
(1)Kafka模型设计
a)主题设计:按照业务系统的表对应kakfa Topic进行映射;
b)分区设计:基于kakfa只能在单个分区下才能保证数据的时序性,需要保证每个表的操作(insert、update、delete)都存储在一个分区下,因此规划为一张表对应一个分区,或者多表对应一个分区。事物量较小的表对应一个partition;
c)由于数据分区存储的在业务上存在不均衡的情况,建议该kakfa接口集群的的物理存储规划为一个块大盘(例如条带化),用于容错分区不均对集群的影响;
d)kafka的分区,一般根据kafka集群broker规模,topic里面的数据量来定,一般分区数设置成broker个数;
e)可以设置多个分区,但要保证OGG生产消息时候,同个表必须到同一个分区下,保证数据的时序性。
(2)Hudi模型设计
a)Hudi无需专门的建表脚本过程,通过程序里面进行表结构的指定;
b)数据类型:采用MOR的模式进行;
c)采用配置文件配置hudi的数据结构,供实时处理程序读取使用;
d)分区键:优先采用业务数据时间modifydate作为分区建,如果没有modifydate的表使用处理时间作为分区键;
e)每个Hudi表指定Hudi key。Hudy可以是每张表的业务主键。
二、实施过程
数据管理平台定位汇聚企业内外部业务数据,向企业内部员工提供报表分析、自助查询、手机分析等应用,同时为企业内部系统提供数据服务,释放数据价值。系统的实施范围、实施计划及部署架构如下:
1、实施范围
以亚信科技AISWare DataInfrastructure大数据基础平台、AISWare DataOS数据中台操作套件、AISWare DataGo企业数据资产治理平台以及AISWare DataDiscovery数据探索分析平台四个核心产品为基础,完成平台架构的搭建;
以模型分层的设计思想为指导,通过模型设计、数据流设计、字段映射及生产发布等,建立基础数据层(ODS)、基础模型层(DWD)、融合模型层(DWA)及展现层(ST),实时数据同步至AntDB表实现实时报表分析;
针对ODS/DWD/DWA/ST各层进行分层数据治理,实现表/字段级关系、数据主外键关系、数据字典结构导入,并且实现指标/报表关系、指标与数据关系、指标列表导入等。
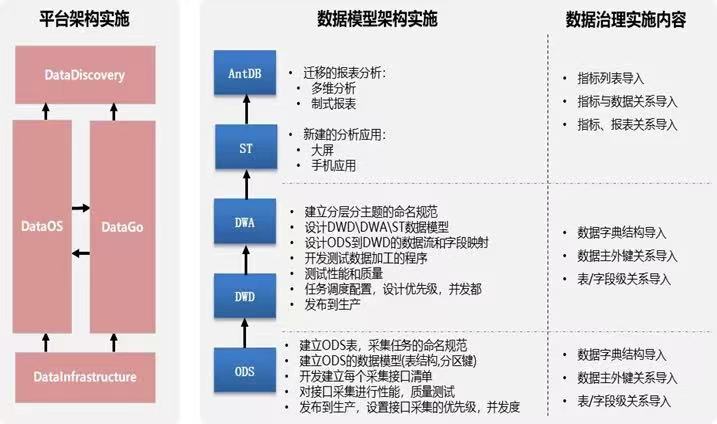
图:实施范围
2、实施计划

图:实施计划
3、部署架构图

图:部署架构图
4、项目组织:亚信科技拥抱“产品+服务”的理念,整合金融保险行业技术骨干,为服务交付提供资源保障,实现数据管理平台项目的量身定制。主要涉及如下支撑团队:
PMO:整体协调资源
应用开发组:应用,指标梳理,开发
数据架构组:数据梳理,DWD,DWA,ST模型设计,数据开发
技术平台组:技术平台实施,运维
5、沟通管理
(1)周报:跟进各组主要事项、规划进展情况及阶段性成果,并形成进度跟踪周报。
(2)会议:为了促进团队建设,强化团队成员的期望、角色以及对项目目标的理解,我们在项目执行过程中,通常会召开以下几种类型的会议:
• 每周例会
• 解决问题会议
• 里程碑沟通会
实际效果及价值:
依托亚信科技建设的数据管理平台,该保险公司实现了统一数据采集、企业“去O”及灵活数据可视化展现的技术目标。
建立统一数据采集平台:接口接入的统一管理和运行的监控,提升数据及时性,更方便和容易接入内外部数据源。
现有数据库迁移到大数据平台:大数据平台架构清晰完善,形成了大数据质量管理、安全管理、开发管理等数据治理能力,提升了数据价值。
构建了灵活的数据可视化工具:提供高效应用开发和快速需求响应能力,提升了数据的应用价值和效果。
在业务应用上,实现了数据一致性、及时性、标准化,同时提供了更丰富的数据展现形式、更快速的数据查询性能。数据开发效率较以往提高60%,报表制作展示效率比以往提高2倍。
提升数据一致性:不同报表数据在统一指标下的一致性得到增强。
增强对数据的理解:使用人员看到数据同时可以知悉数据指标的定义、数据来源信息。
提高数据及时性:优化数据层采集、计算、调度流程,对数据加工大大提速。
业务部门分析指标体系得到规范:梳理合并现有指标并建立新增变更指标的管理体系。
提供更多数据展现形式:除了报表和多维分析之外,还可在大屏、手机查看数据。
提高数据查询性能:通过分布式查询平台,加快前台查询响应速度,报表类<1秒,清单类<3秒。
·亚信科技
亚信科技是领先的软件产品、解决方案和服务提供商,致力于成为“大型企业数字化转型使能者”。公司积极拥抱5G、人工智能、云计算、大数据、物联网等先进技术,秉承“一巩固、三发展”战略,依托“电信级”产品、服务、运营和集成能力,赋能百行千业转型升级。亚信科技拥有行业领先的研发能力,已形成包括客户关系管理、计费账务、大数据、人工智能、5G网络智能化、研发运维一体化、数字化运营、PaaS平台、物联网产品等在内的AISWare产品体系,客户涉及政务、通信、金融、能源、交通、广电、邮政等多个行业。
·某保险公司
该保险公司是经中国保险监督管理委员会批准成立的全国性保险公司。目前经营终身寿险、定期寿险、重疾险、医疗险等80多个产品。
来源:数据猿



































































































我要评论












活动推荐more >
- 【大会嘉宾】威马汽车集团战2021-08-02
- 【大会嘉宾】联通智慧足迹CM2021-08-02
- 2018 上海国际大数据产业高2018-12-03
- 2018上海国际计算机网络及信2018-12-03
- 中国国际信息通信展览会将于2018-09-26
- 第五届FEA消费金融国际峰会62018-06-21















