
三大步骤、四个要点,构建高效又灵活的用户标签体系
原创 岳亚雷 | 2020-04-15 23:47
【数据猿导读】 良好的数据整理,可以让运营直观的以业务事件查看数据源,从而可以自主的进行标签建立可行性的评估

本文作者:岳亚雷,TalkingData高级解决方案架构师,专注零售行业CDP(客户数据平台)和智能营销中枢的产品设计及落地,曾负责多家大型零售企业的数智化转型项目,致力于用“数据+算法”驱动客户运营策略、探索业务场景,挖掘客户生命周期价值。
企业对用户的运营可分为两大类:主动运营,即企业侧主动去筛选用户群体进行投放的运营活动;被动运营,即用户和企业发生互动之后企业对该用户的运营反馈。在这个过程中,我们应如何识别用户进行主动营销,又该如何对用户行为做出更好的反馈?标签体系的设计、构建和使用就显得至关重要。
构建标签体系,很多人第一步就走错了。以终为始,在设计标签体系的时候,一定要思考我们将如何使用这些标签,切忌需求大而全,不然结果就是“构建标签一时爽,梳理标签火葬场”。所有标签的创建都伴随着存储和计算的成本,而大量不使用的标签也会降低我们选择有效标签的效率。
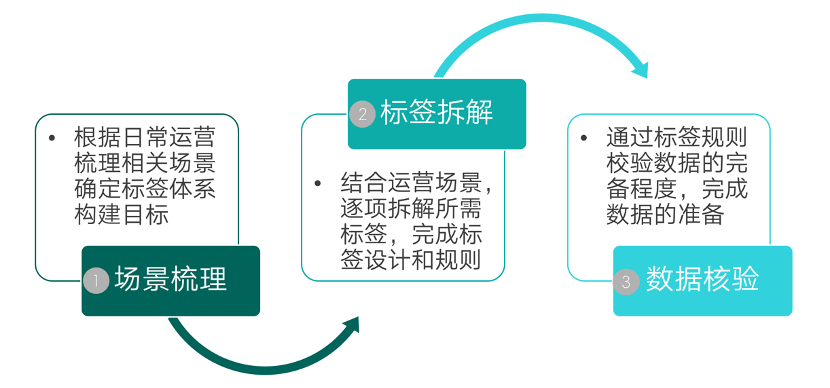
场景梳理
所以,第一步我们需要结合业务诉求梳理相关的运营场景。日常运营场景其实涵盖了大部分运营工作,在日常运营场景之外,我们也会有一些新增的临时运营场景,只要按需进行调整就好了。

调整标签的时候,不同的数据加工存储方式,会带来不同的实施路径。后文中,我们会详细介绍如何更好的梳理数据,才能让标签构建更加灵活,毕竟标签的维护也是日常工作中很重要的一部分。梳理运营场景的时候,我们建议先对场景进行分类,分为主动营销用户和用户行为被动触发两大类,然后在两个分类中进行梳理。
其中的每个场景可以由以下几部分组成:
A.场景名称:用于简单描述和标示场景
B.触发机制:可以是单次手动触发,也可以是周期性循环或者某行为时间触发,用于标示本次场景开始的时间节点
C.用户范围:用于标示本次运营场景涵盖的用户范围,建议划分为用户属性和用户行为
D.投放方式:选择对用户进行投放的渠道,可以是短信、微信、小程序、app push等
例如上图中第一个运营场景:我们需要增加某饮品的预付卡用户,当用户访问会员卡页面的时候会实时触发,通过筛选年龄、工作所处行业、某饮品偏好度以及过去60天的购买行为、购买产品等,对这些用户分群之后,进行小程序弹窗的投放。
标签拆解
场景梳理就绪,我们就可以进行下一步的拆分了。这里我们要重点关注的是用户范围,也就是我们需要对哪部分用户进行分群。这里的用户分群主要就是基于接下来要创建的标签体系,我们需要对上文中梳理的场景进行一条条拆分,得到我们所需要的用户标签,然后对标签进行分类。

标签梳理完毕之后,我们需要对标签的规则进行逐一规范,确保所有项目参与人员对标签的认知是一致的。对于标签的实现,我们可以通过数据工程师写SQL的方式进行,也可以通过标签管理平台直接在前端页面进行配置。SQL的实现方式更加灵活,但是对于标签的后期运维可能带来一定的负担。运营人员如果需要通过相关文档查询才能了解标签的规则实现,我们更建议选择标签管理平台来实现。
选择标签管理平台,要着重考核的是平台对数据类型和算子的支持程度。因为算子越丰富,后期使用以及调整就越便捷。算子的丰富度还可以带来另外一个好处,就是标签规则的透明度。前文也提到,如果通过SQL构建标签,调整标签的时候需要查询相关文档甚至需要跨部门的沟通;而一个好的标签管理平台,会在系统中直观展示出标签的规则定义,并且支持页面直接进行修改,省去了不必要的麻烦。
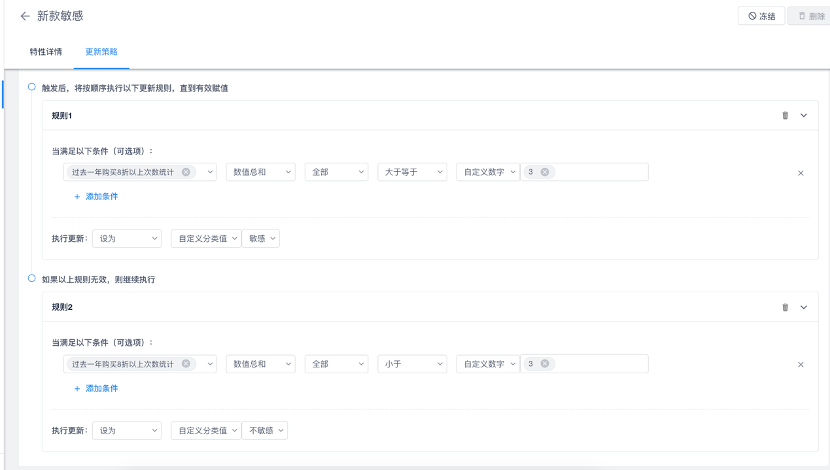
如下图所示,“对于新款敏感”的标签,页面直观展示出了标签的更新规则,即当用户在过去一年购买8折以上产品超过3次的时候,会进行“新款敏感”的标记。假如随着我们的业务变化,新款推出的更频繁了,需要把这一次数调整为5次才进行标记,只需要直接在页面上修改就好了。
数据核验
最后,我们需要进行数据方面的探查来对数据源进行一一确认,毕竟标签构建的基础是数据的完备性,如果没有数据源,我们可能需要进行相关的调整。
随着技术的发展,流式计算框架越来越成熟,使得基于用户与企业交互事件的加工、处理和使用变为可能,也让MOT营销唾手可得。流式数据处理可以准实时的完成对于用户交互事件的反馈,同时事件的处理也让整个运营过程更加清晰。标签的使用和挖掘都建立在良好的数据采集和整理之上,如果基础没做好,一切都将是徒劳,会给我们后续的标签设计和使用带来很多不必要的麻烦。
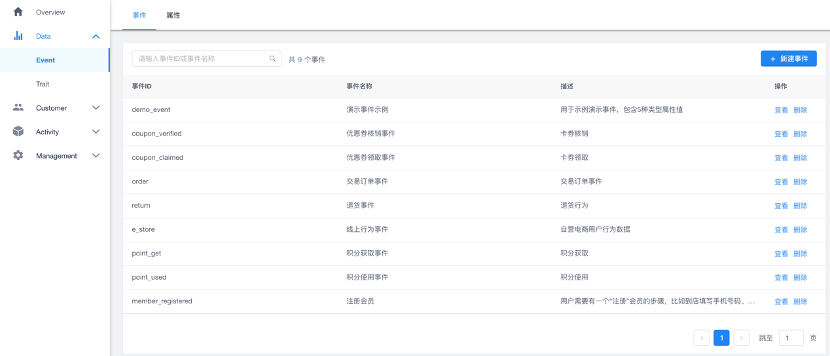
标签更多是对用户的划分,在数据的采集和处理上能够以用户为中心,按照用户事件来记录相关的数据。于是常见的记录用户数据的数据库表变成了一个个的Json对象,如下图中的Json文本记录了用户在什么时间、什么“场”内、产生了什么样的互动。通过对用户事件的标准化处理,我们可以针对行业形成用户事件模版,通过ETL把数据加工成标准化的格式,为后期标签化的处理做好准备工作。
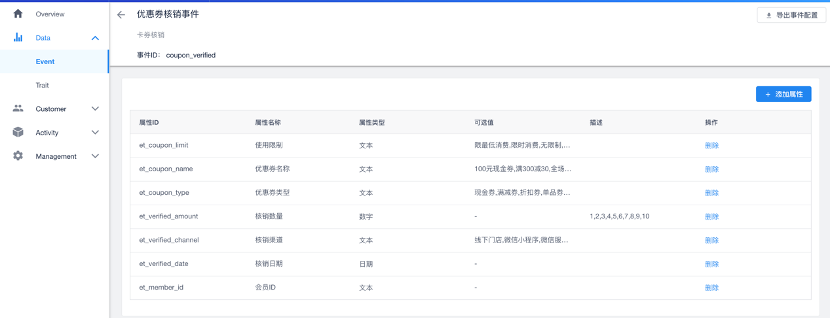
良好的数据整理,可以让运营直观的以业务事件查看数据源,从而可以自主的进行标签建立可行性的评估。例如下图中的“优惠券核销事件”,该Json文本记录了本次事件所发生的用户ID、优惠券的相关属性字段、以及核销的渠道、日期,后续可以根据具体业务需求对事件中的字段进行计算使用。
标签运维
最后我们再聊一聊标签的运维工作。运营场景在变的情况下,我们的标签体系是不可能是一成不变的,随着场景的变化可能会增加很多新的标签,这样会使得标签体系越来越复杂。对于部分不使用的标签,需要对其进行冻结处理,这样才可以不浪费计算资源。
在标签的运营工作中,以流式事件来处理数据做标签管理平台更具优势,这里可以举个例子来说明。在洞察用户行为的时候经常会遇到一个问题,我们希望了解用户在最近一段时间所有购物品类中买金额最高的前几样商品,普通标签管理平台大多是通过数据工程师写SQL的方式来实现这一诉求;如果数据源是以事件形式输入系统的,那结合平台丰富的数据类型和算子,可以直接在前台页面进行配置,操作如下:
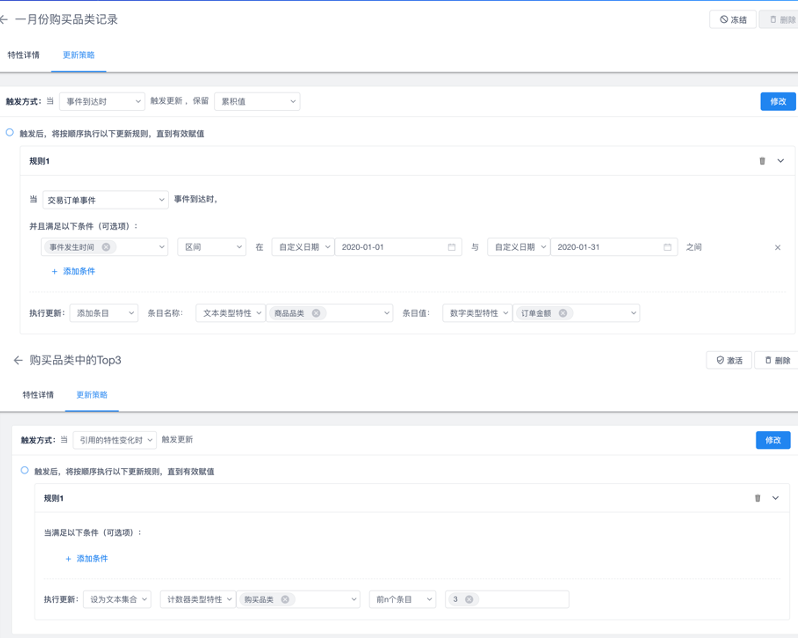
如图示,当交易订单事件进入系统后,记录发生在一月份的用户消费品类以及该品类的金额,然后选择该记录中top3的商品名称即可。如果需要按照业务诉求进行修改,只需要在页面进行操作就好了,而无需协调数据工程师进行SQL的修改。
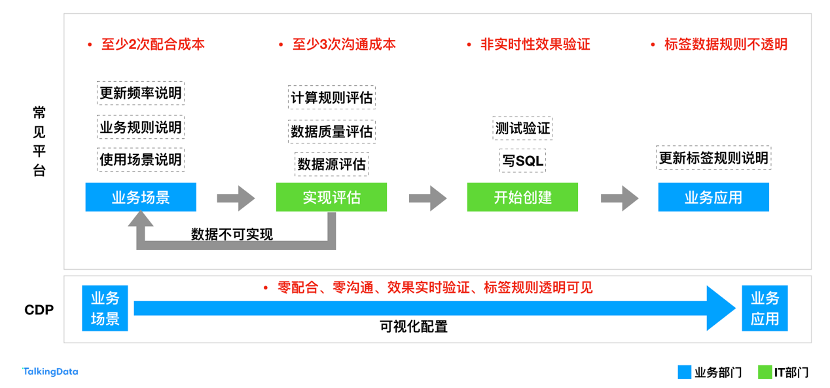
最后总结一下整个标签体系的构建流程。敲黑板,划重点:
1. 以终为始,按需构建
2. 先有场景再拆标签,心中有数,反复查验
3. 场景切忌大而全,数据支撑来保全
4. 灵活调整,节省资源
来源:数据猿
刷新相关文章



































































































我要评论












活动推荐more >
- 2018 上海国际大数据产业高2018-12-03
- 2018上海国际计算机网络及信2018-12-03
- 中国国际信息通信展览会将于2018-09-26
- 第五届FEA消费金融国际峰会62018-06-21
- 第五届FEA消费金融国际峰会2018-06-21
- “无界区块链技术峰会2018”2018-06-14















