
【AI大模型展】天云数据Elpis——强化学习后训练国产信创大模型
数据猿 | 2025-08-22 00:25
【数据猿导读】 该AI大模型由天云数据投递并参与数智猿×数据猿×上海大数据联盟共同推出的《2025中国数智产业AI大模型先锋企业》榜单/奖项评选。

该AI大模型由天云数据投递并参与数智猿×数据猿×上海大数据联盟共同推出的《2025中国数智产业AI大模型先锋企业》榜单/奖项评选。
天云数据Elpis VR是基于高效低成本数据合成技术、可验证强化学习的领域增强、多策略偏好调优,通过全流程自动化分布式训练构建的强化学习后训练国产信创大语言模型,具备即插即用和快速微调的能力,通过强化学习融合了人类高阶知识,通过数据合成降低整体训练成本。
应用场景/使用群体
一、应用场景
场景一:政务智能化
政策分析与公文处理:自动解析政策文件,生成符合政务规范的解读报告。
智能政务助手:支持地方方言和政务术语的智能问答,提升政务服务效率。
信创适配:符合国产化替代要求,适配党政机关自主可控技术体系。
场景二:金融合规与智能投顾
智能风控与反洗钱:基于多源数据生成合规报告,降低人工审核成本。
财富管理助手:快速微调适配银行、证券等机构的投资咨询需求。
信创适配:支持国产化数智技术平台,确保数据安全。
场景三:工业制造与知识管理
设备故障诊断:结合企业维修日志,快速构建故障知识库。
工艺优化与培训:基于技术手册、操作指南提供答疑服务,降低培训成本。
信创适配:可在国产工业服务器部署,适配制造业数据安全需求。
场景四:医疗健康与辅助诊断
电子病历结构化:自动解析非结构化病历,生成标准化诊疗记录。
医学知识问答:基于合成数据增强罕见病案例库,辅助医生决策。
信创适配:支持国产医疗云平台,符合医疗数据合规要求。
场景五:教育科研与智能辅导
个性化学习助手:根据学生需求生成定制化学习方案、习题和解析。
科研文献分析:快速提炼论文核心观点,辅助学术研究。
信创适配:可在国产教育信息化平台部署,满足数据本地化要求。
二、核心使用群体
1、政府机构与事业单位
地方政府信息中心、政务服务大厅、公共安全部门(如公安、应急管理)
2. 金融机构与金融科技公司
银行、证券、保险公司的科技部门、金融监管机构(如央行、银保监会)、金融科技初创企业
3. 高端制造与工业企业
制造业企业研发中心、工业互联网平台、设备运维服务商
4. 医疗机构与健康科技企业
三甲医院信息科、互联网医疗平台、医药研发企业
5. 教育机构与科研单位
高校人工智能实验室、K12智慧教育服务商、在线教育平台
产品功能
天云数据Elpis大模型提供的是基模能力,基于基模能力,可以面向企业提供开箱即用的AI服务,还可以拓展垂直领域应用场景。天云数据数智平台应用均是基于Elpis构建:
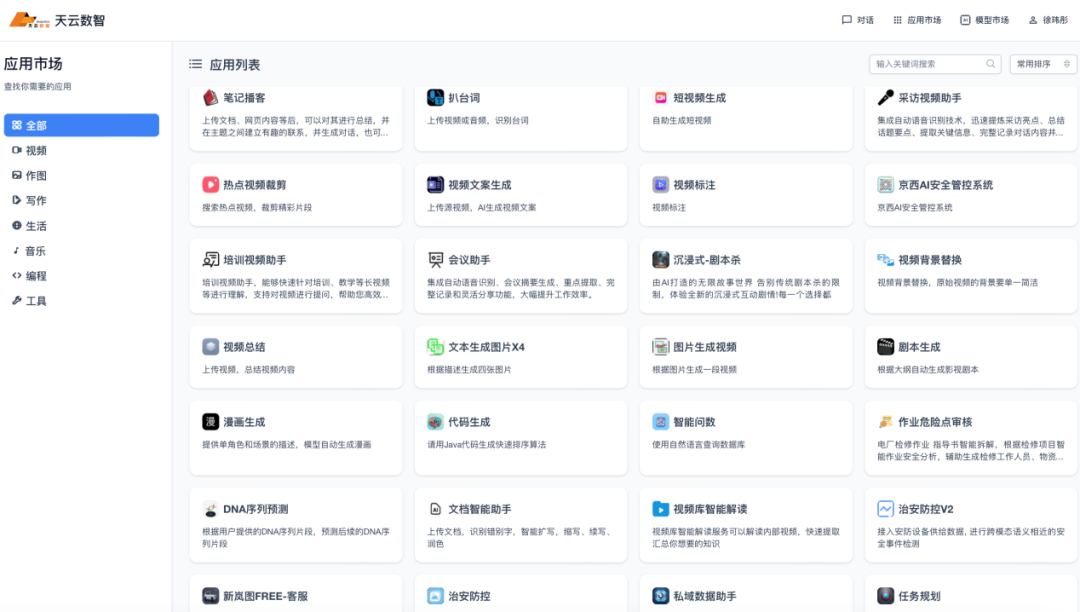
模型能力
一、强化学习是训推一体的后训练架构,与预训练有本质区别
强化学习则采用完全不同的范式——“训推一体”,相当于“做练习题”,只有自己懂了方法才能得到正确答案。其机制包括奖励驱动、环境交互、自主探索。
二、奖励工程取代了提示工程,成为后训练时代的关键方法
后训练奖励工程突破了预训练对高质量标注数据的依赖、赋予了模型真正的目标导向性、为复杂任务的分解和解决提供了自然框架,模型可以通过分层奖励机制来攻克难题。这种转变不仅提升了模型性能,更重要的是开创了AI发展的新范式,为通用人工智能的实现提供了可行路径。
三、强化学习的奖励是训练数据之外的独立数据类别
强化学习的奖励机制代表了一种全新的数据范式——它不再是固定的训练样本,而是来自环境、用户或特定目标的动态反馈信号。这种奖励数据具有独立于训练数据、永不枯竭的特性,为AI的持续进化提供了无限可能。
四、强化学习的探索机制,用不确定性换取突破性进化
强化学习开创性地采用"用不确定性换取奖励"的创新机制,通过工程化的方法,主动保留那些低概率但可能带来高回报的行为选项,从而在算法层面实现了对"熵坍缩"的有效延缓。不仅显著提升了模型性能的上限,更赋予了AI系统类似人类的"冒险精神"。
技术说明
1. RLVR:面向复杂推理能力的强化学习范式
RLVR是利用具备明确、可自动化验证的奖励信号来替代传统强化学习中对人类反馈的依赖,从而高效、规模化地提升模型的特定能力,尤其是逻辑推理、数学计算和代码生成等复杂任务。
技术要点:
自动化奖励机制:与依赖人工标注进行偏好排序的RLHF不同,RLVR将奖励函数建立在可被程序自动校验的结果之上。例如,在代码生成任务中,奖励信号直接与代码是否能通过单元测试挂钩;在数学问题上,则与最终答案是否正确相关联。这种机制摆脱了人工标注的规模与成本限制。
精准对齐目标能力:通过将模型的探索方向与“可验证”的正确结果强行绑定,RLVR能够极其精准地强化模型在特定领域的“求解”能力。模型生成的每一次输出,都会经过验证器的评判,获得正向或负向的反馈,模型则通过策略优化算法不断调整自身参数,以最大化获得正向奖励的概率。
提升推理路径的确定性:经过RLVR优化的模型,在处理同类问题时,能够更稳定、更直接地生成通往正确答案的推理路径。它不仅学会了“什么是正确答案”,更重要的是掌握了“如何稳定地得到正确答案”。这显著提升了模型在单次调用中的准确率,使其在需要高确定性输出的应用场景中表现更可靠。
规模化与效率:由于奖励的生成和验证过程是自动化的,我们可以在极大规模的问题集上对模型进行持续、高强度的迭代训练,极大地加速了模型在特定技能象限上的进化速度,这是传统依赖人工标注的优化方法难以比拟的。
2. 大模型语料数据合成:构建高质量指令微调的基石
数据质量是决定大模型能力上限的核心要素。天云数据借鉴并发展了业界前沿的数据合成实践,建立了一套成熟、可控的大规模高质量语料数据合成体系。该体系旨在通过程序化、模型化的方式,生成海量、多样且具备特定技能属性的指令微调数据,从而低成本、高效率地引导模型学会遵循指令、掌握新知识和新技能。
技术要点:
“教师-学生”模式的指令生成:我们采用一个或多个能力更强的“教师模型”,基于少量高质量的人工编写“种子指令”,通过精心设计的提示工程,驱动教师模型生成海量、多样化的新指令。这个过程并非简单的模仿,而是通过指令进化等策略,系统性地提升生成指令的复杂度、新颖性和领域覆盖度。
多维度、多视角的指令设计:为了确保合成数据的多样性和深度,我们在指令生成过程中引入了“角色”概念。通过为教师模型设定不同的角色,可以引导其从特定专业视角出发,创造出符合该领域思维方式和知识体系的指令及高质量回答,从而构建出具备专业壁垒的训练数据集。
合成数据的质量控制与过滤:并非所有合成数据都具备高价值。我们建立了一套自动化的数据过滤与清洗流水线。该流水线利用一系列指标和辅助模型,对生成的数据进行严格筛选,剔除简单、重复、有偏见或事实性错误的内容,确保最终用于模型训练的每一条数据都是高信息密度且准确的。
偏好数据与直接策略优化的结合:除了生成“指令-回答”对用于监督微调(SFT)外,我们还利用合成技术生成大量的偏好数据对。这些数据可以直接用于直接策略优化等更先进的对齐技术,让模型在没有显式奖励模型的情况下,也能高效地学习到人类的偏好,使其回答更符合用户的期望。
闭环迭代的数据生态:我们将模型在实际应用中的表现数据,以及新合成的数据,持续地反馈到数据生成和筛选流程中,形成一个数据驱动的闭环迭代系统。这使得我们的数据集能够不断进化,动态地弥补模型的短板,并快速响应新兴的知识领域和应用需求。
服务客户
某股份制商业银行惠企政策智能匹配:
采用人工智能技术将政策的核心要素、范围等相关信息抽取成“知识”,并构建对应的模型,完成知识沉淀。根据企业实际情况精确匹配适用的惠企政策,并对企业进行推送,实现自动化处理。实现从需求方出发的流程转换。平台实现了精准的政策解读,通过自然语言技术构建了丰富的政策标签体系,获得惠企政策知识;通过向企业提供政策匹配服务,扩大政务服务范围,争取更多优质企业落户地市;通过将企业核心要素与政策要素的碰撞,让政府更加了解企业经营状况,提前发现企业经营风险;沉淀惠企政策知识包,并为新的惠企政策提供支撑。
上线首周:解读惠企政策超过400条,匹配企业超过1000家,累计为企业提供政策解读服务达到近6000次。
某直辖市政务政府公文自动生成:
天云数据Elpis产品在某直辖市部署,应用在政府公文自动生成不仅通过实体抽取、统计、计算及内容扩写等完成了政府公文的自动生成,还通过代码处理抽取进行数据累加汇总以及根据生成内容提供Top 3诉求依据子标题、包括相关建议的大小标题。
某国资企业:
部署天云数据多模态大模型,系统可精准识别并分析30余类安全规范执行情况,并支持开放语义的泛场景发现与分析。其独创的区域智能管控技术,能通过连续帧实时进行复杂逻辑监测,例如人员未按要求着重并进入生产区域、未按规范手册作业或高危设备操流程不规范等行为,并触发多级联动报警机制。凭借行业领先的AI处理能力,系统可在10秒内完成从异常识别到生成完整分析报告的全流程,大幅提升企业安全管理效率。
某行业科技机构:
部署天云数据多模态大模型,将广告的实际投放效果(如点击率、转化率)作为奖励信号,反向优化内容生成策略。这使得广告不再是“一次性生成”,而是能够根据市场反馈持续迭代支持制作多样化的广告形式涵盖产品展示、品牌形象宣传、营销推广等各类视频内容,并针对不同媒体平台的传播特性和受众特征进行智能优化适配。联手北京科技记者编辑协会、中央广播电视总台、北京广播电视台、北京科技报社打造的“每月科学流言榜”项目,获北京市科学技术协会首都科学传播优秀案例。
关于企业
·天云数据
天云数据,两度荣获CAAI人工智能奖项“吴文俊人工智能科学技术奖”,首批国家级专精特新小巨人企业,北京市科学技术奖厂商,提供L5级别MaaS平台服务。
上层MaaS平台产品提供多芯多租户多集群统一运营管理、构建弹性智能体工作流服务,无缝对接业务流程和跨应用数据,支撑企业业务应用智能化重构。MaaS模型池由下层Elpis系列后训练基础模型支撑,包括多模态和严谨推理的训推一体强化学习Elpis-VR,面向具身智能的空间视觉语义的端到端Elpis-VLS及Elpis-VLA模型。
来源:数据猿




























我要评论
不容错过的资讯













大家都在搜


