
反叛军的复仇,Claude 3真的能碾压GPT-4么?未必!
【数据猿导读】 大模型的竞赛,真是越来越精彩了。一直以来,这个市场的绝对主角就是OpenAI,它甚至抢走了谷歌、微软这些科技巨头的彩头。但OpenAI的王座并不稳固,一直有不同的挑战者向它发起冲击。最新的一个挑战者是Anthropic刚刚发布的Claude 3,从纸面战斗力来看,这个模型似乎已经超过了GPT-4。...

大模型的竞赛,真是越来越精彩了。一直以来,这个市场的绝对主角就是OpenAI,它甚至抢走了谷歌、微软这些科技巨头的彩头。但OpenAI的王座并不稳固,一直有不同的挑战者向它发起冲击。
最新的一个挑战者是Anthropic刚刚发布的Claude 3,从纸面战斗力来看,这个模型似乎已经超过了GPT-4。
本来想去亲自体验一下这款产品,但它的能力没见识到,但“封号小达人”的威力倒是名不虚传,那就先让我们根据它披露的技术文档,来看看纸面上的战斗力吧。
纸面的战斗力
目前,有不少媒体宣称Claude 3已经全面碾压了GPT-4,这个结论是怎么来的呢?总得拿出证据来吧。
为了评估自己的能力,Claude 3进行了一系列测试,包括:在GPQA、MMLU、ARC-Challenge和PubMedQA等领域的具体问题上进行测试;在英语和多语言环境下解决数学问题;在HellaSwag和WinoGrande上进行常识推理;在DROP上进行文本推理;在RACE-H和QuALITY上进行阅读理解;在HumanEval、APPS和MBPP上进行编程;以及在BIG-Bench-Hard上进行多种任务的测试。
以下是测试的结果,我们只对比Claude 3 Opus(最强大版本)和GPT-4。
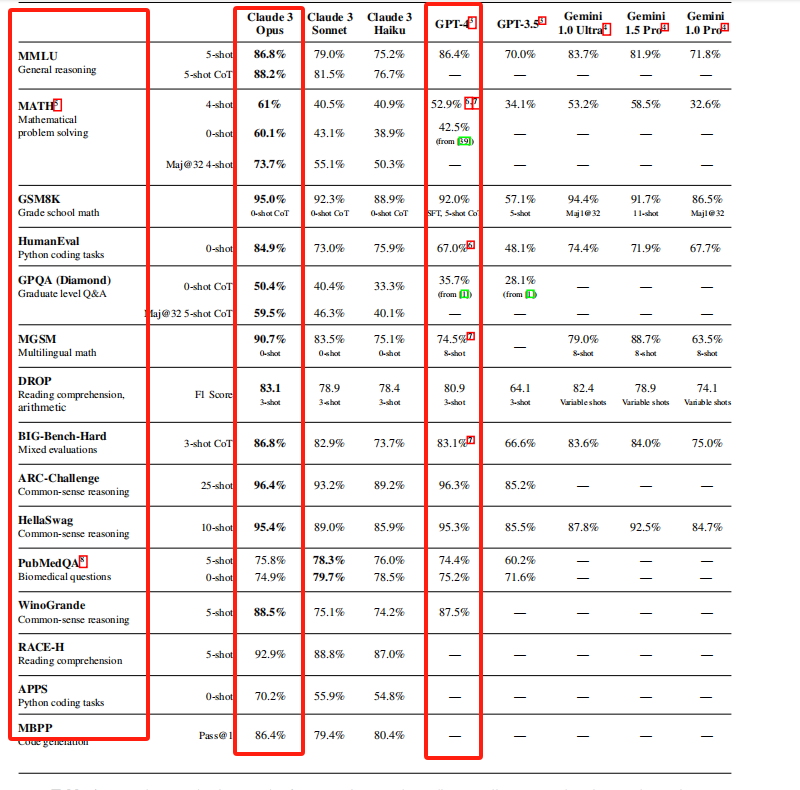
为了更清楚的显示出他们的差异,我们将每个指标的Claude 3 Opus和GPT-4的得分摘取取来,做图表来进行对比。
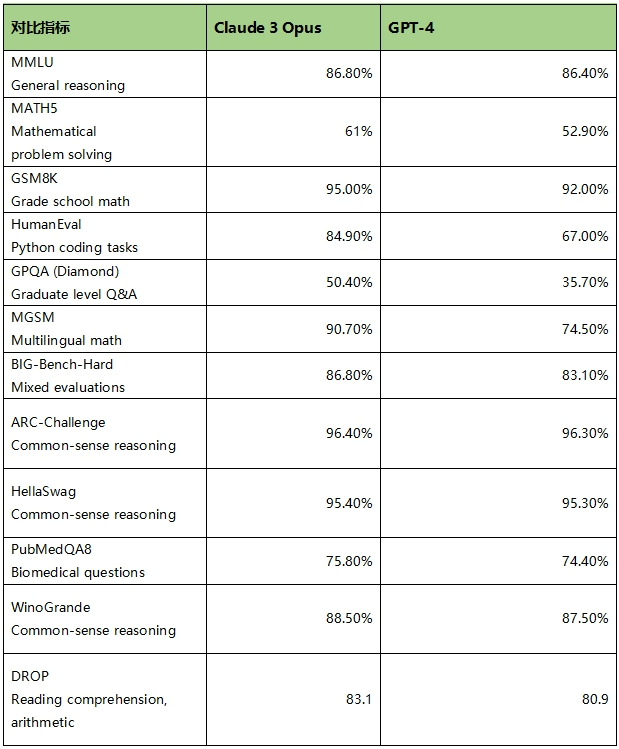
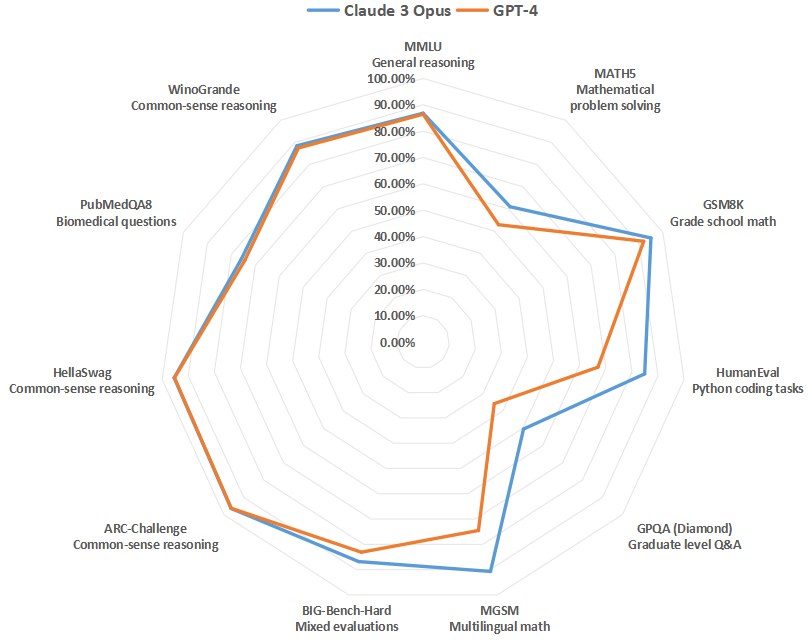
Claude 3 Opus和GPT-4在主要测试上的成绩对比 数据来源:《Model_Card_Claude_3》报告 数据猿分析整理
接下来,我们挑选几个主要的测试,来进行对比分析。
MMLU (Massive Multitask Language Understanding) 是一项综合性的语言理解测试,由斯坦福大学的研究人员发起。该测试旨在评估AI模型在广泛的主题和任务上的理解能力,涵盖了科学、人文、社会科学等多个领域的知识。测试通过向模型提出各种问题,并根据模型提供的答案进行评分,以此来衡量模型在一般推理和领域特定知识上的表现。分数越高,表示模型的理解能力和推理能力越强。在该项指标上,Claude 3 Opus(86.8%)与GPT-4(86.4%)的差异很小。
MATH测试主要评估AI模型解决数学问题的能力,它通过提出各种数学题目,从基础算术到高等数学不等,考察模型对数学原理的理解和应用能力。这些题目可能包括证明、方程求解、几何问题等。模型的表现通过正确解题的数量来评分,分数越高表示模型在数学问题解决方面的能力越强。在该项指标上,Claude 3 Opus(61%)要明显强于GPT-4(52.9%),说明Claude 3 Opus的数学能力更胜一筹,那其数据分析的准确性、数据计算能力可能更好。
而MGSM (Multilingual Math) 上的表现,进一步验证了Claude 3 Opus(90.7%)的数学能力要比GPT-4(74.5%)更强。MGSM测试旨在评估AI模型在多语言环境下解决数学问题的能力,测试模型不仅要理解和解决数学问题,还需要跨语言边界,展现其对不同语言中数学概念的理解,这样的能力反映了模型在全球化应用场景中的适应性和灵活性。也就是说,在中文环境下解决数学问题,Claude 3 Opus在解决数学问题上的表现大概率要好于GPT-4。
值得特别提一下的是GPQA (Graduate-level Google-Proof Question Answering) ,该指标是一项针对研究生水平知识和推理能力的评估测试,旨在检验AI模型在处理高级、专业领域问题上的表现。这类问题通常需要深入的专业知识和复杂的推理能力才能解答。分数反映了模型在接近研究生水平专业知识领域的理解和应用能力。在该项指标上,Claude 3 Opus(50.4%)也要比GPT-4(35.7%)好很多。这在To B领域的领域很重要,该项能力上的差异,意味着基于Claude 3 Opus开发的行业大模型、领域大模型可能表现更好。
剩下的几项指标上,Claude 3 Opus与GPT-4的差异都比较小,Claude 3 Opus略好一点点,具体包括:
BIG-Bench-Hard是一个综合评估,针对AI模型在多个不同任务上的性能进行测试,它旨在通过混合评估来检验模型在理解、推理、语言处理等多个方面的能力。这些任务设计来模拟复杂的现实世界问题,挑战模型的极限。
ARC-Challenge、HellaSwag、WinoGrande都是常识推理测试,其中,ARC-Challenge旨在评估AI模型在处理需要广泛常识知识解答的问题时的能力。这个挑战包括了一系列困难的问题,这些问题要求模型不仅要理解问题的文字表述,还要能够利用常识来推理出正确的答案;HellaSwag旨在评估AI模型在预测文本结尾方面的能力,它提供了一系列情境描述,并要求模型从多个选项中选择最合适的结尾;WinoGrande提出了一系列需要利用常识来解答的挑战性问题,旨在测试模型在理解和推理复杂、模糊或有歧义的情景时的能力。这个测试特别强调了对广泛世界知识的理解和应用,挑战模型在不完全或间接信息下作出准确判断的能力。
PubMedQA是一个专注于生物医学领域问题的评估测试,它旨在测试AI模型在理解和回答生物医学相关问题的能力。这个测试包括了从PubMed数据库中摘录的问题及其答案,考察模型对生物医学文献的理解程度以及能否准确提供医学信息。
DROP (Discrete Reasoning Over the content of Paragraphs) 是一个阅读理解和算术推理测试,专为评估AI模型在处理需要从文本中提取信息并执行算术运算来回答问题的能力而设计。这个测试通过提出结合文本理解和数学运算的复杂问题,检验模型不仅要理解给定段落的含义,还需在此基础上进行计算和推理,以得出正确答案。
考试能力
在评估大模型能力方面,除了一些行业基准测试外,让各个大模型参加考试,也是一个常见的测试方法。
比较常见的包括美国的法学院入学考试(LSAT)、多州律师考试(MBE)、美国数学竞赛(AMC)和研究生入学考试(GRE)等,其中,LSAT是用来评估法学院入学考生逻辑推理和阅读理解能力的考试,而MBE是律师资格考试中的一个重要组成部分,涵盖法律知识和推理能力。AMC是一系列高中数学竞赛,测试学生的数学推理和解决问题的能力。GRE则是一项用于评估研究生入学考生的标准化考试,包括定量推理、语言表达和写作能力。
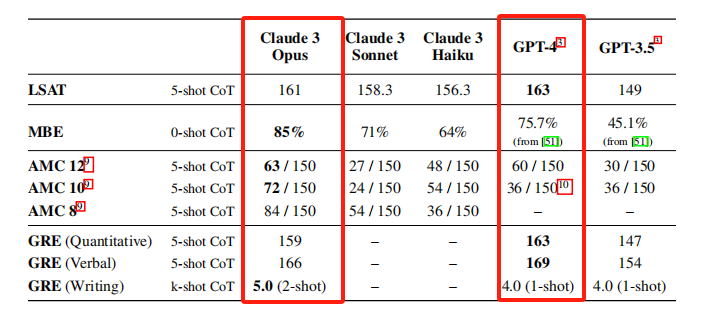
通过对这些测试的评估,可以更好地了解Claude 3 Opus和GPT-4在逻辑推理、数学问题解决、语言理解和写作等方面的能力。从表格中可以看出,Claude 3 Opus在法学院入学考试(LSAT)、研究生入学考试(GRE)上不如GPT-4,但在多州律师考试(MBE)、美国数学竞赛(AMC)上要强于GPT-4,可以说打得有来有回。
多模态能力
接下来,我们看看Claude 3 Opus和GPT-4在多模态任务上的评估结果,包括视觉问答、图表和文档理解等。具体来看,包括以下评估:
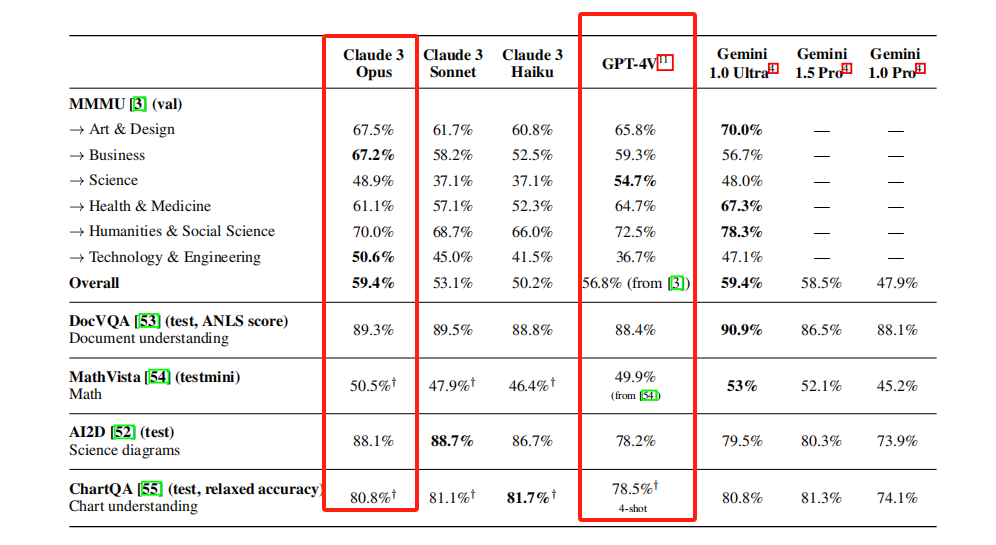
MMMU(val),这是涵盖了多个领域的综合评估,包括艺术与设计、商业、科学等。评估采用了对文本和图像的综合理解。
DocVQA主要评估模型对文档的理解和相关问题的回答能力,评估采用了问答形式,分数的差异反映了模型在文档理解和问答方面的差异。
MathVista主要评估模型在解决数学问题时的表现,评估采用了数学问题解决的准确率作为指标。
AI2D主要评估模型在理解和处理科学图表时的表现,评估采用了图表理解准确率作为指标。
ChartQA主要评估模型在理解和回答关于图表的问题时的表现,评估采用了图表问题回答准确率作为指标。
综合来看,Claude 3 Opus在大部分评估上,其实跟GPT-4都差不多,只是略微好于GPT-4。

Claude 3 Opus和GPT-4在多模态能力上的成绩对比 数据来源:《Model_Card_Claude_3》报告 数据猿分析整理
在多个评估指标上的表现优于GPT-4,说明其在多模态任务中具有更强的综合理解和应用能力。而且,MMMU评估中的Science一项,Claude 3 Opus得分48.9%,要差于GPT-4的54.7%;Health & Medicine、Humanities & Social Science这两项评估上的表现,也不如GPT-4。
但在AI2D这一项上,Claude 3 Opus要明显优于GPT-4,说明其对于图表的理解和处理能力要更强,而且在MMMU的Technology & Engineering这一项上,Claude 3 Opus得分50.6%,要远远好于GPT-4的 36.7%。
GPT-5呼之欲出?
以上,是Claude 3与GPT-4的主要对比结果。可以看出,在很多项目上,Claude 3都更胜一筹。
当然,各种评测标准只是一个参考因素,最终还是要通过大量用户的使用,才能比较出优劣。只是纸面上的战斗力,并不能决定胜负。其实,无论是科技巨头还是初创公司,都陆续推出了一些在纸面战斗力上部分超越GPT-4的大模型,但在实际使用过程中,GPT-4的王者地位依然不可撼动。
而且,目前的各项数据对比结果,也只是来自于Anthropic自己发布的技术文档,他们是否在评测时做了有利于自己产品的一些操作,还不得而知。而且,现在市面上的各种评测很多,这些评测到底有多少合理性,还需要打上一个大大的问号。还是那句话,只有经过大量用户的使用,才是鉴别一个大模型好坏的金标准。
从另一个角度来看这个问题,我们假设上面的各项评测数据都是科学合理的,那从这些数据表现来看,Claude 3是不是就接近OpenAI还没发布的GPT-5的水平呢?这是一个有趣的问题。
不管怎么样,Anthropic作为一个挑战者,给GPT-4带来真实的威胁,这对于整个行业而言,是一件好事。说明这场比赛还远未结束,大家都有机会,这也意味着中国的大模型企业同样有机会。
要知道,Anthropic作为OpenAI的“叛军”,由OpenAI前研究副总裁Dario Amodei和GPT-3论文的第一作者Tom Brown等叛军创立于2021年。既然Anthropic可以挑战OpenAI,那至少说明“王侯将相宁有种乎”,OpenAI并不是不可逾越的高山。
作为一个中国的用户,我们还是希望在国内能早点出现这样的挑战者。即使不考虑国家大义,就是单纯作为一个普通用户,国内的产品用起来也方便的多。追着给人家送会员费,还动不动给你封号的日子,是真的受够了。
关注数据猿,后台回复“Claude 3”,获得Claude 3技术报告原文。
来源:数据猿
































































































我要评论
不容错过的资讯









大家都在搜







