
中美AI军备竞赛的核心战场:万亿级预训练模型
凝视深空 | 2021-11-10 18:48
【数据猿导读】 人工智能是一个庞大的产业,要有全面的评估很困难。但是,我们可以从一个典型领域来“管中窥豹”——超大规模预训练模型。

在人工智能这个领域,主流玩家就中美两家。总体上呈现出美国领先,中国追赶的局面。中美都将人工智能作为战略高地,倾注了大量的资源。
可以说,中美之间的人工智能产业竞争,已经非常激烈了。某种程度上,中美正在进行人工智能的“军备竞赛”。
目前的竞赛情况怎么样了呢?
人工智能是一个庞大的产业,要有全面的评估很困难。但是,我们可以从一个典型领域来“管中窥豹”——超大规模预训练模型。
之所以将超大规模预训练模型,作为观察中美人工智能竞赛的“窗口”,因为这个领域比较符合军备竞赛的几个特点:
第一,战略地位显著。
现阶段,人工智能技术局限性还很大,某类模型往往只能解决特定细分领域的问题,模型“泛化”能力很差。通用人工智能才是人们的终极追求,目前的专用人工智能模型显然不能满足要求。解决问题的一种思路,就是不断增加模型的参数量,增大模型的复杂性,提升模型的泛化能力。人们期望更大的参数规模,可以带来更高的模型准确率,以及一个模型解决更多领域的问题。
超大规模预训练模型能否实现通用人工智能,还未可知。但在目前来看,这是最有希望的一条路。量变引起质变,只有“量”够了,才有质变的可能。我们可以对比一组数据:成年人大脑中约包含850-860亿个神经元,每个神经元与3万突触连接,人脑突触数量预计2500万亿左右。
人类的智能是怎么来的,本质上就是来自于这些神经元、突触。人脑也是一台计算机,这些神经元、突触就是基本的计算单元。如果要想人工智能达到人类水平,那在基本计算单元的数量规模上达到甚至超越人类大脑,就是一个必要条件。
按照这个思路,打造超大规模预训练模型,增加模型参数,就相当于增加了模型的计算单元。也许,人工智能的“奇点”就是2500万亿计算单元。当然,预训练模型的参数跟计算单元的概念还不一样。但是,现在也没有其他更好办法,我们只能尽快把模型的参数规模提高到2500万亿量级,看看那时会发生些什么,没准会出现奇迹呢。
从这个角度来看,打造千万亿参数规模的预训练模型,是人类的一个超级工程,可能会对国家甚至人类社会产生重大影响。近代历史有多个超级科学工程,必然曼哈顿计划、阿波罗登月计划、人类基因组计划等,这些超级工程都拓宽了人类发展的“天花板”。
第二,竞赛的成果易于评估。
要评价两个预训练模型谁更厉害,有很多指标,但有一个关键指标,那就是参数规模。总体上,1000亿参数的预训练模型,要比100亿参数的预训练模型更强大。
这有点像海军的军备,评价两艘军舰战斗力,一个重要指标就是看军舰的吨位。万吨级的军舰,战斗力一般会强于千吨级军舰。所有军舰的吨位总和,也成为衡量两个国家海军实力关键指标。
同样的道理,要看中美两国人工智能竞赛的情况,预训练模型的参数规模,就是一个很好的指标。
第三,资源投入巨大,是烧钱的游戏。
跟军备竞赛类似,超大规模预训练模型,不仅需要技术能力,也需要“钞能力”。人工智能的核心要素有三个:算法、数据、算力。一个成功的大规模预训练模型,需要大量天才来解决算法问题,需要积累海量的数据,模型训练需要耗费大量的算力。每一项,都需要“钞能力”的支持。
因此,超大规模预训练模型,是巨头的游戏。目前,全球也就中美两国的少数几个玩家。
第四,“战况”激烈,你追我赶。
我统计了下中美主要的大规模预训练模型,尤其是那些不断打破参数规模记录的一些模型,做了一张统计图如下:
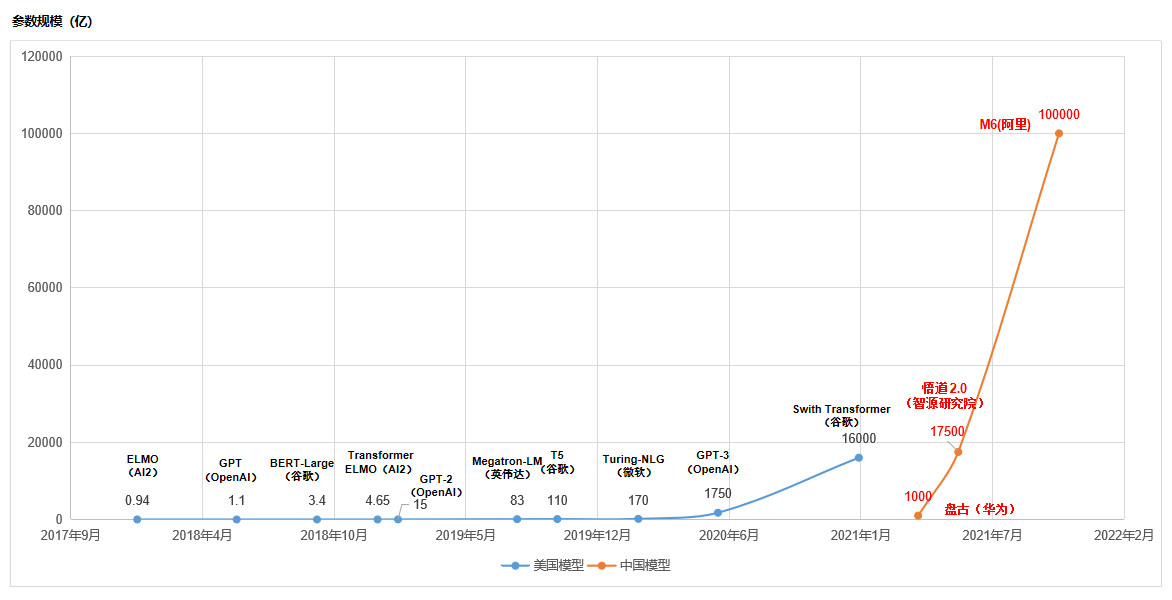
中美预训练模型竞赛
从上图可以看出几个特征:
(1) 美国在大规模预训练模型上起步早,并且在持续不断的进行演进。从AI2在2018年发布只有9400万参数的ELMO开始,谷歌、微软、英伟达、OpenAI等美国公司相继接力,不断打破参数规模记录。而中国是在2021年才开始在大规模预训练模型上开始发力,比美国晚了三年。
(2) 大规模预训练模型只是少数玩家的游戏,无论中美,都只有为数不多的几个玩家。这很好理解,预训练模型的技术、数据、算力门槛很高,只有巨头才能玩这个游戏。
(3) 中国后发优势明显。虽然中国比美国晚几年发力,但一出手就拉高了竞赛的烈度。美国比较著名的GPT-3模型规模还在千亿量级,谷歌的Swith Transformer刚开始迈入万亿门槛。中国的“万亿俱乐部”已经有两个玩家了,智源研究院参数规模已经1.75万亿,超过了谷歌Swith Transformer的1.6万亿。阿里巴巴刚刚发布的M6的参数规模已经突破了10万亿。
应该说,中国企业和机构之所以能够后来居上,跟预训练模型本身的发展特征是分不开的。预训练模型参数规模的增长并不是线性的,而是指数级的。下一代模型的参数规模,并不是上一代的两三倍,很可能会高一个数量级。单看前几年美国的发展,也符合这个规律,参数规模从亿级逐步增加到10亿、百亿、千亿、万亿。
所以,阿里巴巴创造的记录很快就会被再次打破。美国的谷歌、微软、OpenAI、英伟达等的实力,依然强大。下次打破记录的很可能是这些公司。
(4)中国也形成了玩家“军团”。对于一个国家而言,要想在某个领域实现赶超,单靠某一家企业或机构是不保险的,要有多个玩家才行。中国除了此次打破记录的阿里巴巴,智源研究院的实力也很强。华为也参与了这个游戏,虽然目前只发布了千亿级参数规模的预训练模型,但以华为的秉性,以及其对人工智能的重视程度来看,相信华为绝不会止步于千亿规模。
此外,中国玩家还有腾讯、百度、科大讯飞等。比如百度有ERNIE-M,腾讯有派大星,虽然他们在参数规模上没能破当时的记录,但也各有特色,属于“小而美”的存在。
需要指出的是,中美之间是对手,但在面对自然的时候,又是队友。下面我们再来看另一个数据:目前预训练模型的参数规模是10万亿,而人类大脑突触的规模超过2500万亿。人工智能的参数规模,与大脑突触规模,还差了2个数量级。如果考虑到模型参数与大脑突触在“算力”上的差别,这个差距会更大。
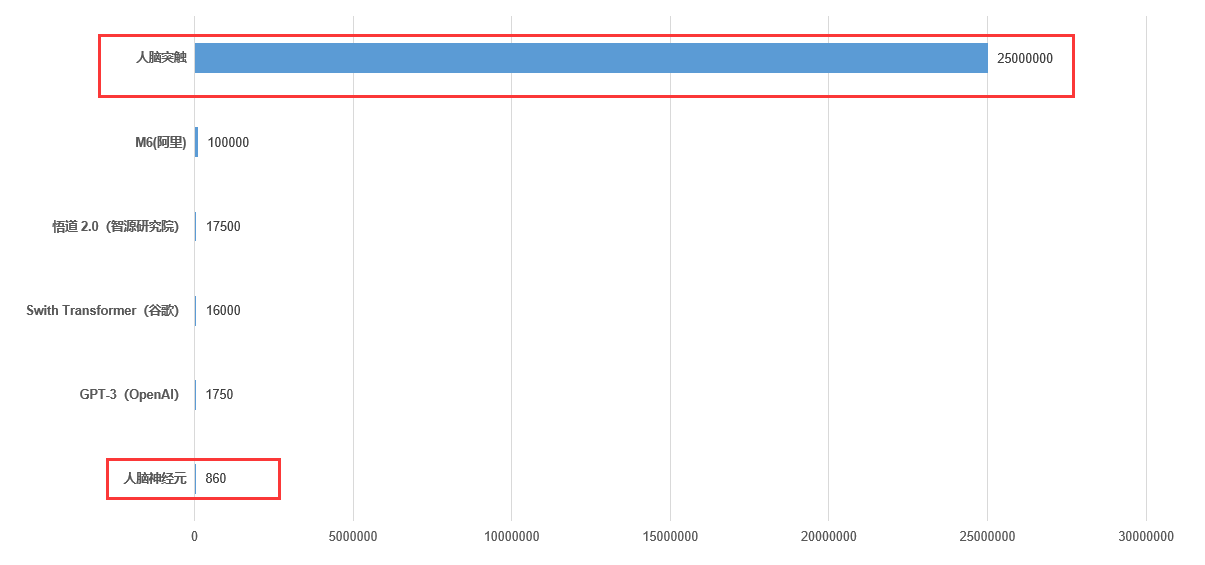
预训练模型与人脑突触规模对比
尽快把模型参数规模提高到2500万亿量级,是人类面临的共同挑战。当然,有能力解决这个挑战的国家,主要就是中国和美国。革命尚未成功,同志仍需努力。
上面提到过,大规模预训练模型是烧钱的游戏。参数规模越大,训练成本越大。以参数规模为1750亿的GPT-3为例,其一次训练成本就高达1200 万美元。那参数规模为2500万亿的模型,其训练费用会是多少呢?虽然训练费用并不随着参数规模线性增长,但更大的模型,肯定会更费钱。假如人类设计出2500万亿参数规模的预训练模型,其训练成本可能会达到几十亿甚至上百亿。
这有点类似粒子加速器。人类为了探索高能条件下的物理规律,粒子加速器造得越来越大,也越来越费钱。目前全球规模最大的粒子加速器是欧洲的LHC,这台机器有几十个国家参加,耗资几百亿。在中国科学界,一直有一个争论,就是要不要花几百亿甚至上千亿,造一个比LHC能级更高的粒子对撞机。
在可控核聚变领域,也有一个类似的项目,就是大名鼎鼎的ITER(国际热核聚变实验堆计划)。ITER装置是一个能产生大规模核聚变反应的超导托克马克,俗称“人造太阳”。即使以1998年的币值算,都要耗资50亿美元,也是几十个国家参与。
在超大规模预训练模型领域,如果发展到最后,发现千万量级参数规模的模型真的要耗资几十亿甚至上百亿,是否也可以参考上面的例子,搞一个全球合作呢?当然,中美是主力,其他国家也就打打酱油。
试想一下,一旦把AI模型的参数规模,提高到人类大脑突触的量级,会不会迎来“奇点”?还是有点小期待啊。
文:凝视深空 / 数据猿
来源:数据猿
刷新相关文章




































































































我要评论












活动推荐more >
- 【大会嘉宾】威马汽车集团战2021-08-02
- 【大会嘉宾】联通智慧足迹CM2021-08-02
- 2018 上海国际大数据产业高2018-12-03
- 2018上海国际计算机网络及信2018-12-03
- 中国国际信息通信展览会将于2018-09-26
- 第五届FEA消费金融国际峰会62018-06-21
















