
国产向量数据库,凭什么挑战谷歌?
原创 月满西楼 | 2025-09-25 20:47
【数据猿导读】 9月25日,出自清华团队的「数智引航」正式发布其最新产品:VexDB——为AI而生的向量数据库。这款定位于“知识中枢”的国产产品,致力于为企业级AI应用打造一套高召回、高性能、便于集成和调用私域知识的数据系统,专治“幻觉”与“业务失联”。

“一个清华团队做向量数据库,能解决模型幻觉问题?
让我们来看这样一个案例:在某头部医疗信息化企业的客服后台,一段时间前曾发生这样一场“AI事故”:值班客服将用户的健康咨询请求交由接入大模型的AI助手处理。看似顺畅的问答后,AI生成了一套“个性化用药建议”,文笔通顺、逻辑完整、甚至引经据典。但细究之下,医生发现——这段建议基于的是一份并不存在的药品说明书片段,内容与患者实际情况严重不符。
这并非孤例。AI“胡说八道”的问题,已经在越来越多的企业PoC测试、行业探索和真实业务中暴露无遗。
这一切的背后,是大模型通用能力与企业真实业务之间的“最后一公里”,仍缺乏真正落地的基础设施支撑。
9月25日,出自清华团队的「数智引航」正式发布其最新产品:VexDB——为AI而生的向量数据库。这款定位于“知识中枢”的国产产品,致力于为企业级AI应用打造一套高召回、高性能、便于集成和调用私域知识的数据系统,专治“幻觉”与“业务失联”。
那么,AI应用到底需要什么样的数据库?VexDB又有哪些独门绝技?让我们来深入的探讨一下这个问题。
大模型很强,
但企业用起来为什么“总差点火候”?
近两年来,大模型的火烧得越来越旺。DeepSeek、OpenAI、Anthropic、Meta、百度、阿里、腾讯、字节、智谱、月之暗面……模型参数越来越大,推理速度越来越快。
但一线企业的声音,却越来越冷静:
“模型是很强,可是我们用不上啊。”“PoC可以跑得很快,真上线就没下文了。”“我们不是不会用,是根本用不起来。”

模型竞速如火如荼,企业却常常“止步PoC”
这不是个别案例,而是普遍现象:不少企业在内部做了大模型PoC实验,接入了ChatGPT或国产大模型,试图构建客服问答、销售辅助、文档总结等场景。但在完成初步展示后,项目就“搁浅”了,甚至一纸不留地归入归档文件夹。
为什么大模型如此强大,却无法接住企业需求的“地气”?
核心问题不在模型,而在 它没有企业级的“知识支撑”。
三大软肋击中大模型系统的“脆弱核心”
经过大量案例观察,可以发现阻碍AI落地的“关键软肋”,主要集中在三方面:
(1)幻觉难控:模型一本正经地“胡说八道”
在开放语境中,大模型非常擅长生成内容,但一旦用于企业严肃业务场景,问题就来了:
·给出的内容看起来“有模有样”,但根本无法确认真实性;
·一旦生成结果出错,企业要承担合规风险、客户投诉甚至舆情冲击;
·对于医疗、政务、金融等行业,更是“一字之差,千钧之重”。
这就是“幻觉”问题——模型在没有知识支撑时,倾向于编造答案,哪怕是自信满满地胡说八道。
(2)知识失联:你有数据,它却用不上
大模型原生训练数据不包含企业的私有知识,它并不了解你公司的制度、业务流程、产品配置文档、历史问答记录。
即使企业拥有PB级私域数据,模型也“看不见”“听不懂”“连不通”。
于是你会看到这样的场景:模型在用户提问时给出的方案,压根没参考本地文档;明明公司产品升级了,模型却还在“默认旧版本”;想让模型“结合案例”推荐产品,它却只会泛泛而谈。
知识失联,是当下RAG系统最常见的落地失败原因。
(3)数据沉睡:文档、图片、视频“看得见,摸不着”
更隐蔽的是,企业内部的数据,本质上是非结构化的:合同、SOP、客服记录、医学影像、视频课件……这些数据沉睡在系统里,没有被结构化加工,无法被模型直接调用或理解。
你或许做了信息门户,也建了数据中台,但模型无法理解“PDF图纸里哪一页有图纸说明”,也无法从语音中提取“客户抱怨的核心情绪”。
在这样的数据现状下,大模型很难发挥作用。它像是一位能力强大的工程师,却无法读懂你公司的“说明书”。
AI没有“知识地基”,业务连接无从谈起
企业希望AI帮忙的是——“辅助判断”“调取资料”“生成决策建议”,而不是仅仅“编一段话”。
这意味着:AI不仅要能生成答案,更要理解上下文、引用知识源、具备业务感知能力。
也就是说,我们需要的不是“内容生成器”,而是“语义理解器”——具备调用知识、理解业务、联想上下文能力的AI系统。
要做到这一点,大模型本身并不足够。
它需要一套可靠的“知识地基”——把企业数据结构化、语义化、可检索化,让模型可以像“检索大脑”一样使用它,构建起真正的认知闭环。
而这,正是新一代“向量数据库”的价值所在。
VexDB,为AI而生的向量数据库
如果说大模型是内容的生成引擎,那么向量数据库就是连接“生成”与“知识”的那座桥梁。
大模型负责生成,向量数据库负责理解与调用。但这并不是任何一个数据库都能胜任的任务。它必须足够懂语义、够快、够稳、够场景化。
而来自清华团队打造的VexDB,正是为这个任务而生的国产答案。
谁是VexDB?它解决了什么问题?
VexDB诞生于清华大学数据研究团队二十余年技术积累,由数智引航团队进行产品化打造,具备典型的“产学研一体”特征。

它的使命,不是做“又一个数据库”,而是专为AI场景而生的基础设施:
·定位明确:不仅是传统通用型数据库,而是聚焦RAG与大模型场景的关系型+向量数据库;
·目标明确:让企业私域数据能被“理解”、被“召回”、被“引用”;
·问题明确:专治两大AI落地顽疾——幻觉与知识失联。
换句话说,VexDB的目标是让AI系统:回答有据可依,不再胡说八道;理解企业语言,能听懂业务中的“黑话”“术语”“上下文”;调用企业知识,实现真正的“私域智能”。它的关键词,是“语义理解+极致检索+稳定可靠”。
VexDB为什么特别“懂AI”?
要想“懂AI”,就要从根上“为AI设计”。VexDB在技术层面做了四个关键突破:
(1)语义理解力强:多路召回+向标混合索引
普通向量库仅支持“向量相似度召回”,但VexDB在此基础上叠加了语义增强能力:
·关键词精准匹配与语义泛化能力结合,多路召回提升检索覆盖率的同时兼顾效率与准确性;
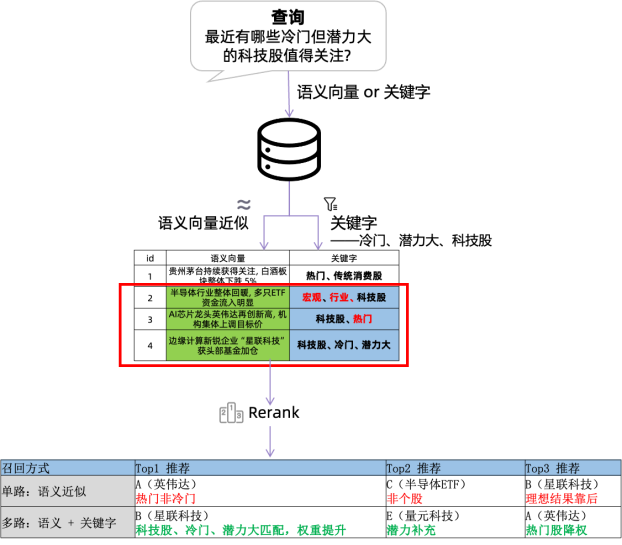
·引入向标混合索引机制(Hybrid Index),将语义相关性与精度过滤结合,提升召回质量;
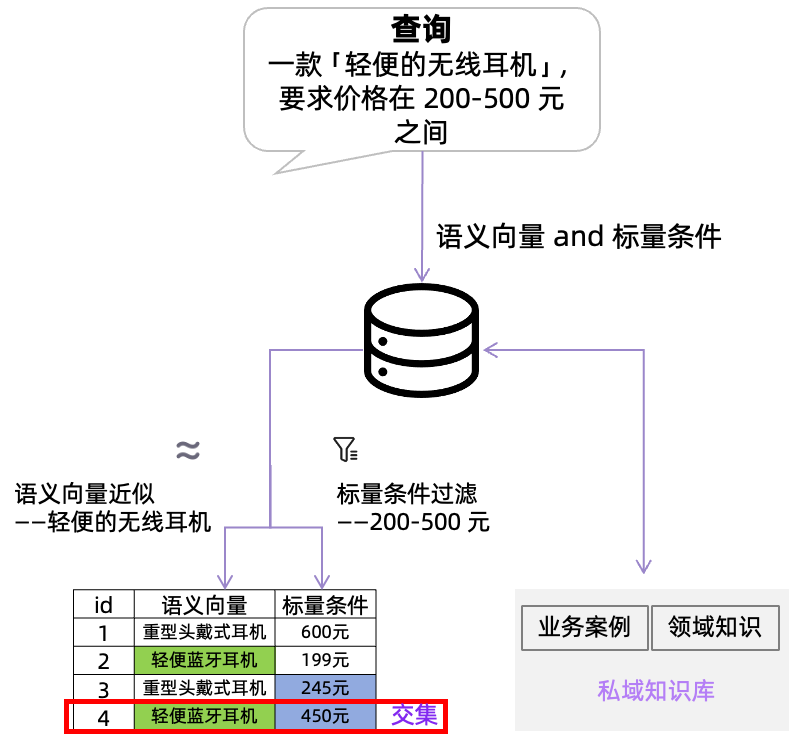
·不只是“找得准”,还能“过滤得对”,让模型少看无用知识,提升生成质量。
这一能力,正是解决“幻觉”的第一步:给模型喂对的知识。
(2)处理能力狠:GraphIndex+SIMD/GPU并行
AI场景下,数据库要面对的不是几万条数据,而是亿级别向量的秒级调用需求。
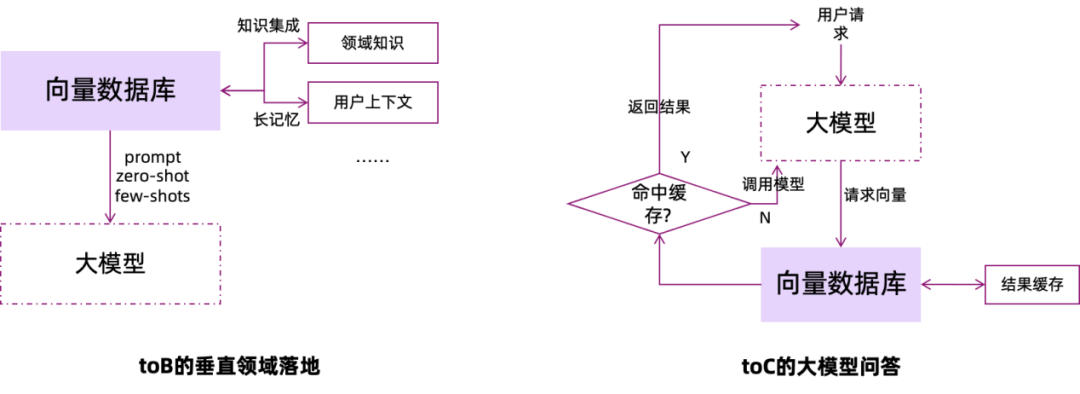
VexDB底层采用:自研的GraphIndex索引结构,加速相似向量的高维空间检索;同时支持SIMD指令集加速与GPU并行调度优化,实现百亿向量毫秒级响应。
这使得它不仅能满足To C的高并发请求,通过向量查询相似结果缓存并返回,提升大模型吞吐、降本增效;也能支撑To B系统负载,解决模型幻觉,进行快速的领域知识集成,成为真正的“在线认知引擎”。
(3)数据一致性硬核:0延迟更新+秒级主备切换
企业系统容不得“知识滞后”。昨天更新的文档、今天发布的标准,必须实时生效。
VexDB支持:0延迟数据更新,新知识可实时向量化入库、立即可查;主备热切换机制,可实现秒级故障恢复与容灾,保障高可用场景下的数据一致性与服务连续性。
这意味着,哪怕是金融、医疗、电信等“秒级容错”的行业,也可以放心把向量库接入业务流。
(4)国产化友好:可落地、可审计、可托管
在数据安全与国产化的趋势下,VexDB提供了:本地化部署能力,支持私有化环境运行;安全审计与访问控制,符合企业合规要求;支持两地三中心高可用架构,可作为大型国企、央企的底层设施。
技术出身,落地为本——这才是国产AI基础设施的正确姿势。
不是空谈技术,而是在关键场景里“真跑起来了”
VexDB不是停留在PPT里的“技术概念”,而是真正“开箱即跑”的系统。多个行业客户,已经在真实业务中落地部署。
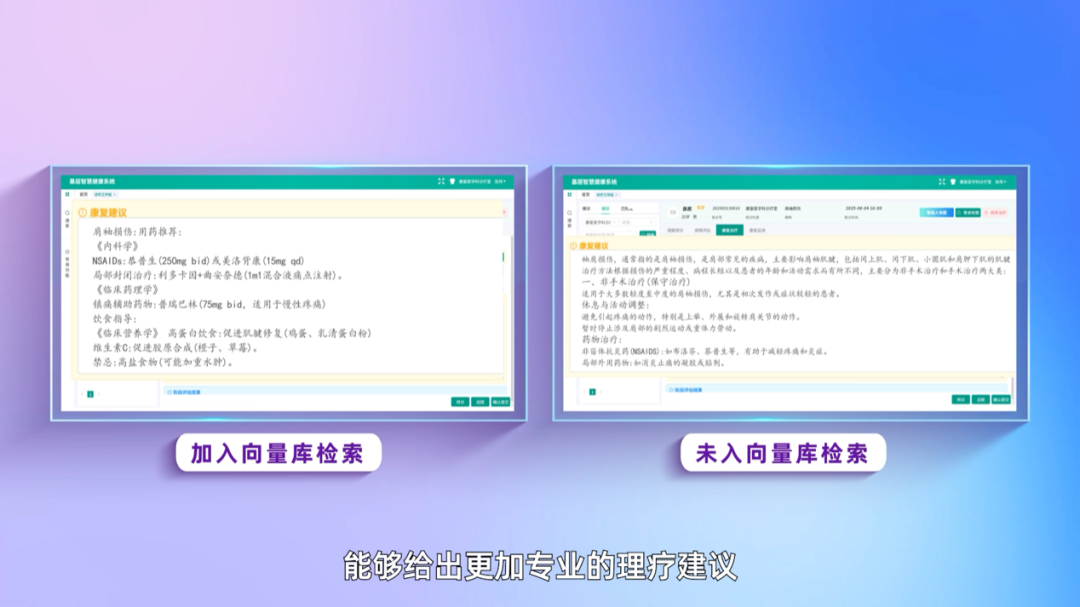
例如,在医疗领域,帮助某企业将海量电子病历向量化处理,实现AI医生辅助生成方案,整体效率提升60%,同时数据不出院门,合规安全;给某三甲医院构建康复设备推荐系统,超400万病例已完成向量化,真正实现“精准推荐”。
在运营商领域,帮助某通信客户基于VexDB构建RAG服务体系,实现客服问答秒级响应、方案自动生成,并接入“AI云盘”,实现“所说即所得”的知识搜索体验。

这些场景,有的是关乎生命安全,有的是面向千万用户,还有的是专业分析——VexDB在其中,不是“做演示”,而是“跑业务”。
普惠开发者,开放生态,让AI“用得起、用得上”
值得指出的事,VexDB并不只是服务头部客户,它在生态开放性与开发门槛上也做了大量工作。例如:提供免费开发版,可快速部署测试,开箱即用;支持对接主流国产模型,构建RAG应用;使用标准SQL语法,降低学习成本;提供多语言SDK(Python、Java等)、完善API文档,适配多种算力环境。
对于中小企业、开发者团队、科研单位来说,VexDB正在让“企业级RAG”成为普惠能力,不再是大厂专属。
向量数据库,
将成为AI时代的“水电煤”吗?
如果说大模型是这个时代的电,点亮了智能的曙光。那么真正支撑它持续发光的,便是背后的数据基础设施——这就是AI时代的“电网”、“自来水管道”、“煤气主干线”。
这些曾经默默无闻的底层系统,如今正站上舞台中央。尤其是其中的新物种:向量数据库,正在悄然成为AI发展的“基础设施担当”。
向量数据库,不只是“技术组件”,而是“AI的认知中枢”
传统数据库的使命,是存储与查询结构化数据;而向量数据库的使命,是让AI理解这个世界。
在RAG框架中,向量数据库完成的是知识“编码-检索-注入”的全过程,对模型生成结果的可靠性、专业性、个性化,有着决定性影响。
VexDB所扮演的,正是这样一个角色:它把你过去“用不上的文档、报告、聊天记录”变成了可以即问即答的知识语料;它让AI不仅“懂通用知识”,更“懂你公司、懂你业务、懂你的客户”;它让AI不再是一个“万能机器人”,而是你专属的数字员工、数字专家。
从清华实验室到多行业落地,它正在验证一条“中国路径”
值得注意的是,VexDB不仅是一项数据库创新,更是一种国产基础设施突破路径的缩影。
它背后的逻辑是:清华数据研究底蕴+工程落地团队,实现“从实验室到生产线”的跨越;自研技术架构+场景实战能力,让产品不仅“能用”,而且“跑得动”;从医疗、运营商到体育场景的全栈适配,不断验证通用性与稳定性;兼容国产芯片、支持国产大模型、符合本地合规架构,打通“国产AI堆栈”的闭环。
这是一条典型的“中国式科技突破路径”:从应用痛点出发,走产业结合之路。而这样的路径,将是国产AI生态长期可持续的关键。
AI时代的“信任引擎”,从数据库开始
过去,我们以为AI的核心竞争力是参数量、是推理速度,是大厂间的算力军备竞赛。但现在我们越来越清楚:AI真正的落地能力,不仅取决于它“能生成什么”,还取决于它“是否懂得你”。
而“懂”,恰恰意味着两个字:信任。
企业要信任AI的答案,员工要信任AI的判断,客户要信任AI的建议——这份信任的背后,需要有“认知的地基”,需要一个能把私域数据真正激活并注入模型的系统性能力。
这,正是向量数据库的价值所在。
当我们把数据从沉睡中唤醒,把知识从冷库中释放,让模型与企业的知识世界深度连接,AI才终于从“幻觉机器”走向“智能伙伴”。
或许未来我们不会再特意谈起“向量数据库”这个术语,就像今天我们很少再去讨论电网、水厂、管道系统——但它们,却在支撑起一切科技的运行。
来源:数据猿
刷新相关文章




































































































我要评论
不容错过的资讯















大家都在搜


