
AI公司挤破头抢数据:OpenAI“扒”视频内容,谷歌“觊觎”办公数据
原创 王茜茜 | 2024-04-09 20:49
【数据猿导读】 4月4日,在接受Bloomberg Originals采访时,YouTube首席执行官尼尔·莫汉(Neal Mohan)对OpenAI发起了警告,称如果Sora利用了YouTube的视频来训练,这将是违反平台政策和规定的,因为创作者并不希望自己的内容被拿来利用。

4月4日,在接受Bloomberg Originals采访时,YouTube首席执行官尼尔·莫汉(Neal Mohan)对OpenAI发起了警告,称如果Sora利用了YouTube的视频来训练,这将是违反平台政策和规定的,因为创作者并不希望自己的内容被拿来利用。
但有趣的是,当主持人Emily Cheung追问Google是否也用YouTube数据训练过自家的Gemini AI,是否为创作者支付了相关费用时,这位CEO的表述变得有些“暧昧”。他承认Google确实使用了YouTube的数据来训练Gemini,但同时声称他们是“按照条款规则”进行的,并没有透露是否有为创作者支付相关费用。
这种回应显然无法让网友信服,于是他们开始了“花式”吐槽:
“创作者们,看到了吗?YouTube现在说它拥有你们制作的内容。”
“不要把‘不该说’的事情说出来!”
“谷歌也没有为创作者支付数据费用吧?好吧,是的,服务条款说不用付费。”

尽管目前尚无证据显示Sora确实使用了YouTube视频进行训练,但这位CEO的警告很可能是受到最近《华尔街日报》的一篇报道影响。该报道称,OpenAI开发了语音识别工具Whisper,可以将YouTube视频转录为文字,为其大型语言模型提供新的训练数据。
表面上,YouTube似乎站在创作者一边,但实际上,无论是谷歌还是OpenAI,他们都在竭尽全力寻找各种合规或灰色地带的手段来获取大量训练数据,以确保在人工智能领域保持领先地位,而创作者利益等问题,显然并不是他们的首要考虑。
互联网上的可用数据将很快被耗尽
2020 年 1 月,约翰·霍普金斯大学理论物理学家贾里德·卡普兰(Jared Kaplan)和九名 OpenAI 研究人员一起发表了一篇关于人工智能的开创性论文,得出了一个明确的结论—训练大型语言模型的数据越多,它的性能就越好。
自此,“(数据)规模就是一切”成为人工智能领域的一大信条。OpenAI的ChatGPT-3.5的惊艳表现,更是点燃了整个生成式AI赛道的狂欢,引爆了对数据的需求。
Meta全球合作伙伴和内容副总裁尼克·格鲁丁 (Nick Grudin) 曾在一次会议上表示:“唯一阻碍我们达到 ChatGPT 水平的因素就是数据量。”
AI巨头们随之开启了争夺数据资源的激烈竞赛:GPT-3于2020年3月推出,使用了3000亿的token;去年上线的GPT-4使用了12万亿token;如果遵循当前的增长轨迹,GPT-5可能会需要 60 万亿到 100 万亿的token。谷歌于去年推出的PaLM 2使用了3.6万亿的token,而2022年上线的PaLm只用了7800万的token。
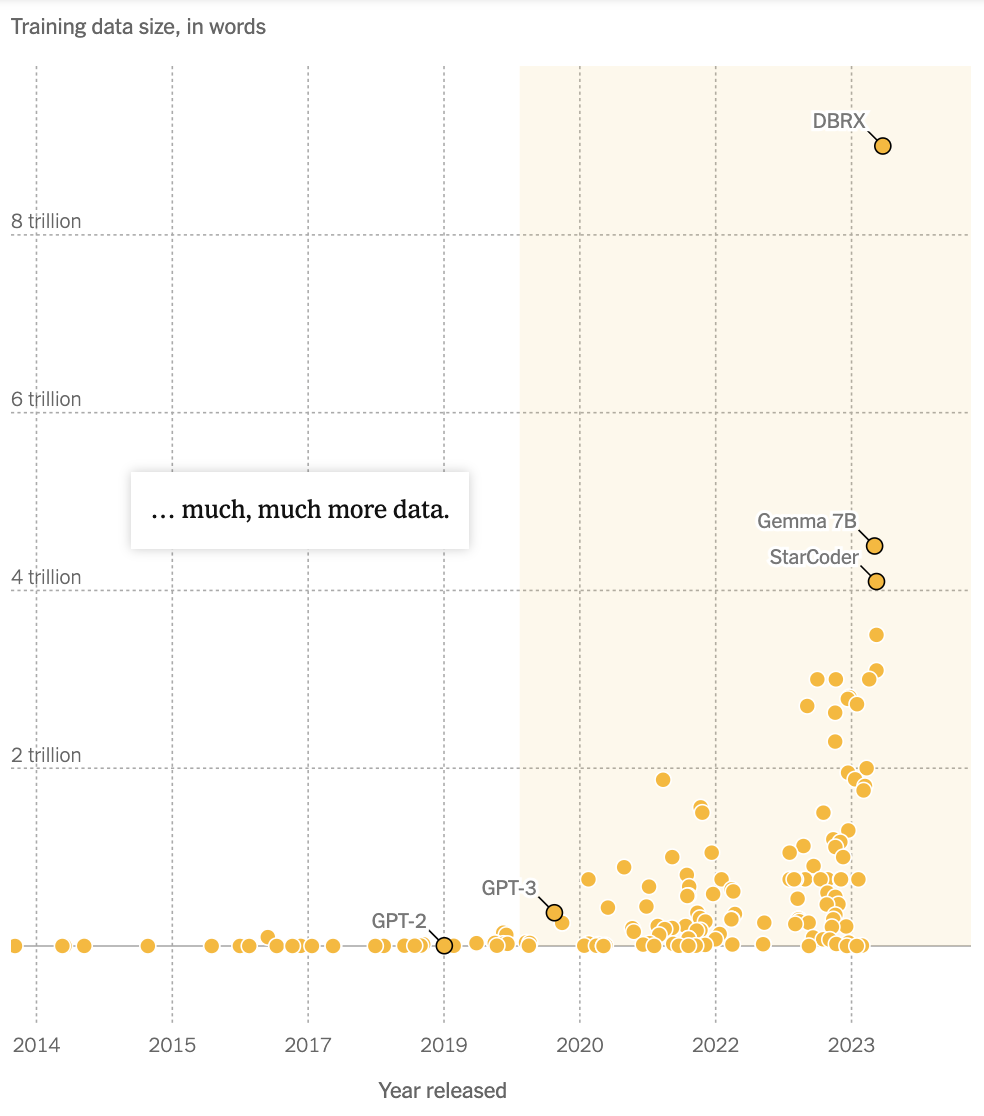
(不同的大语言模型对训练数据的需求量。Credit:《纽约时报》)
由于这些大语言模型使用数据的速度比产生数据的速度还要快,这便导致数据资源,尤其是高质量的,已经被大量“开采”和使用。
根据人工智能研究机构Epoch的预测,到2026年,所有高质量可用数据都可能被耗尽, 去年5月,OpenAI首席执行官Sam Altman也在技术会议上公开承认,AI公司们在不久的将来会耗尽互联网上所有可用的数据。

(低质量的语言数据预计在2050年被用完,高质量的语言数据预计在2026年用完,视觉数据预计在2060年用完。Credit:Epoch)
如果没有新的数据源或者无法提高数据利用效率,那么依赖庞大数据集的机器学习模型的发展速度将逐渐放缓。这意味着,AI公司为了维持技术领先优势,不得不开启激烈的数据争夺战,不断地寻找新的数据源。
新一轮的AI军备竞赛:获取更多“数据”
OpenAI在2021年底就已经感受到了“数据饥渴”的压力,为了训练更大的模型,他们开始四处寻觅数据。在OpenAI总裁Greg Brockman的带领下,Whisper项目应运而生,通过转录超过100万小时的YouTube视频,为GPT-4模型注入新的血液。虽然这种做法有法律风险,但OpenAI的团队依然认为这是值得的。
另一边,谷歌并没有“高尚”到哪去,它也转录了 YouTube 视频为其大语言模型获取文本,甚至还盯上了用户在Google Docs(谷歌文档),Google Sheets(谷歌表格),Google Slides(谷歌PPT),以及Google Maps(谷歌地图)等服务里产生的内容。
据估算,这些应用程序中蕴藏着数十亿个token。为了以后能有机会利用这些数据,去年6月,谷歌要求隐私团队修改政策,并特意在美国独立日假期期间7月1日发布了新政策,以分散公众的注意力。目前,谷歌声称没有在实验计划之外使用这些数据。
在这场“数据淘金潮”中,拥有大量用户数据的平台格外受到关注:
在ChatGPT推出后不久,“受到刺激”的Meta、谷歌、亚马逊和苹果等科技巨头纷纷与Shutterstock等图片库提供商达成协议,获取其数亿张图片、视频和音乐文件用于AI训练。据Shutterstock透露,最初的交易额在2500万美元到5000万美元之间,随着对数据的需求增加,这一数字还在不断上升。
Photobucket,这个曾服务于Myspace和Friendster的图片托管网站,也变成了科技公司争夺数据的焦点。据称,多家科技巨头正在与Photobucket谈判,意图获取其130亿张照片和视频资料,以用于训练他们的生成式人工智能模型。这些资料的定价范围,从每张图片的5美分到1美元不等,而视频的价值则更高,每个超过1美元。尽管Photobucket的当前用户数仅为200万,远低于其7000万的巅峰用户量,它所拥有的庞大数据量仍旧极具价值。
Shutterstock的竞争对手Freepik同样宣布已经与两家大型科技公司达成协议,以每张图片2到4美分的价格,许可其档案中大部分的2亿张图像。该公司还表示,有5笔类似的交易正在进行中,但拒绝透露买家身份。
谷歌与Reddit签订了年度6000万美元的使用协议,获取高质量的长篇内容,用以训练其大型语言模型。
即便拥有Facebook和Instagram这样大规模的社交平台,Meta仍面临着高质量数据来源的短缺问题。由于这两个平台缺少深度内容的沉淀,Meta试图收购Simon & Schuster出版社,以获取长篇作品。此外,为了快速获取数据进行训练,该公司抓取了互联网上几乎所有可用的英语书籍、散文、诗歌和新闻文章,甚至一些受版权保护的内容。
对于创作者来说,他们生产的大量内容在不知情的情况下被科技公司用于训练,而这些公司利用这些数据来优化自己的盈利产品,而创作者却分文不得,这种情况多少有些不公平。
《纽约时报》去年起诉 OpenAI 和微软,称其在未经许可的情况下使用受版权保护的新闻文章来训练人工智能聊天机器人。OpenAI 和微软却表示,使用这些文章是“合理使用”,或者说是版权法允许的,因为他们为了不同的目的而改造了这些作品。
“合成数据”是出路吗?
随着互联网上可用的“天然资源”变得日益稀缺,AI行业正在探索新的数据来源,以满足未来大模型训练的需求。其中,合成数据成为了一条潜在的途径。
顾名思义,合成数据并非直接从现实世界中收集,而是通过算法生成的文本、图像和代码,旨在模拟现实数据的特征和行为,从而让系统能够从自生成的内容中学习。
换句话说,系统从它们自己产生的东西中学习。
这是有成功案例的。例如,Anthropic在上个月推出的Claude 3 LLM就使用了部分“合成数据”来进行训练,在最后的榜单性能跑分全面超越GPT-4。
Sam Altman在去年5月也提出了用合成数据来训练大语言模型的路径:模型可以产生类似人类的文本,然后这些文本数据可以再被用来训练模型,将帮助开发人员构建日益强大的技术并减少对受版权保护的数据的依赖。
理论上,这种方法能够形成一个完美的闭环,既满足了大规模AI模型对数据的庞大需求,又避免了直接从用户那里收集敏感信息的争议和风险。
但我们并不能过分乐观,近几个月来,研究人员发现,在人工智能生成的数据上训练人工智能模型将是一种数字形式的“近亲繁殖”,最终导致“模型崩溃”或“ 哈布斯堡诅咒(Habsburg AI)。”
而进一步模型崩溃会导致生成模型输出低质量、缺乏多样性的结果,不仅降低了模型的泛化能力和应用价值,增加了训练和调试的难度及成本,损害用户对模型及其背后系统的信任和可信度,最终对研究进展和技术创新造成阻碍。
无论是获取天然数据还是生产合成数据,在人工智能竞争中,小型公司都面临着严峻的挑战。他们既没有足够的资金来购买版权数据,也无法获取存放在科技巨头拥有的平台上的用户数据。
在Reddit上,一些创业者感叹道:“是的,这是违反了(YouTube)的用户协议,但老实说,我们处于困境中,因为大科技公司垄断了市场。我的公司因为无法爬取开放网络的内容而崩溃,这是因为 Twitter、Facebook 和 Google 的反竞争行为。”
“这只会引发一系列问题。所有这些公司都在不断地侵犯对方,但这只是为了排挤更小的公司。这些大公司都有罪,否则就无法正常运转。”

在这个以数据为王的时代,AI公司的行为揭示了一个深刻的真相:在追求技术领先的路上,数据的获取和使用成了无可避免的战场。随着数据资源的日益紧张,各大公司不惜一切代价寻找新的数据源,即便这意味着涉足法律和道德的灰色地带。这种做法不仅引发了关于数据隐私、版权、以及创作者权益的广泛争论,也暴露了现有数据利用机制的漏洞和不足。
在这场由数据驱动的技术竞赛中,既有激动人心的进展,也有令人忧虑的隐患。技术的发展不应以牺牲个人隐私和创作者权益为代价,合理合法地利用数据,保护数据来源的同时,开发更加高效、公平的数据利用机制,将是人工智能行业未来发展的关键。随着技术和社会的进步,我们期待一个更加透明、公正的数据生态系统的建立,以此推动人工智能技术健康、持续的发展。
来源:数据猿




































































































我要评论
不容错过的资讯















大家都在搜







