
最强AI!三大维度、70项指标、3728道考题,文心3.5再拿第一!
【数据猿导读】 7月25日消息,中文通用大模型综合性基准SuperClue发布了最新中文大语言模型排行榜。榜单结果显示,百度文心一言总分超GPT-3.5-Turbo,领跑国内大模型。

7月25日消息,中文通用大模型综合性基准SuperClue发布了最新中文大语言模型排行榜。榜单结果显示,百度文心一言总分超GPT-3.5-Turbo,领跑国内大模型。
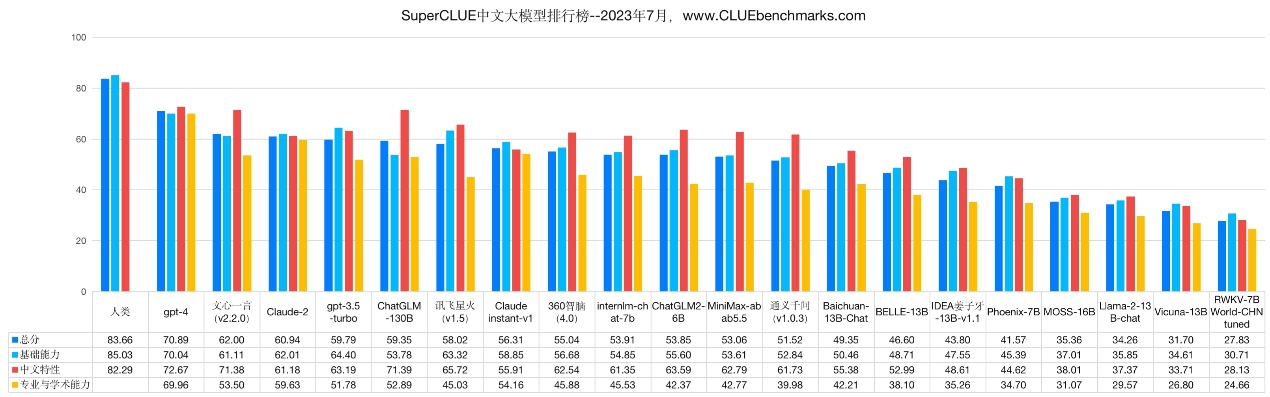
SuperCLUE-Opt评测基准是SuperCLUE综合性三大基准之一,每期有3700+道客观题(选择题),由基础能力(10个子任务)、中文特性能力(10个子任务)、学术专业能力(50+子任务)组成,用于考察大模型在70余个任务上的综合表现。
此次SuperCLUE从基础能力、专业能力、中文特性能力三个维度70余项子能力,选取国内外20个有代表性的可用大模型进行测评,兼具综合能力考量与中文特定任务理解积累的考察,并通过自动化测评以相对客观形式进行效果测评。在总分榜中,文心一言紧随GPT-4,总分超GPT-3.5及国内其他大模型,模型效果最佳。
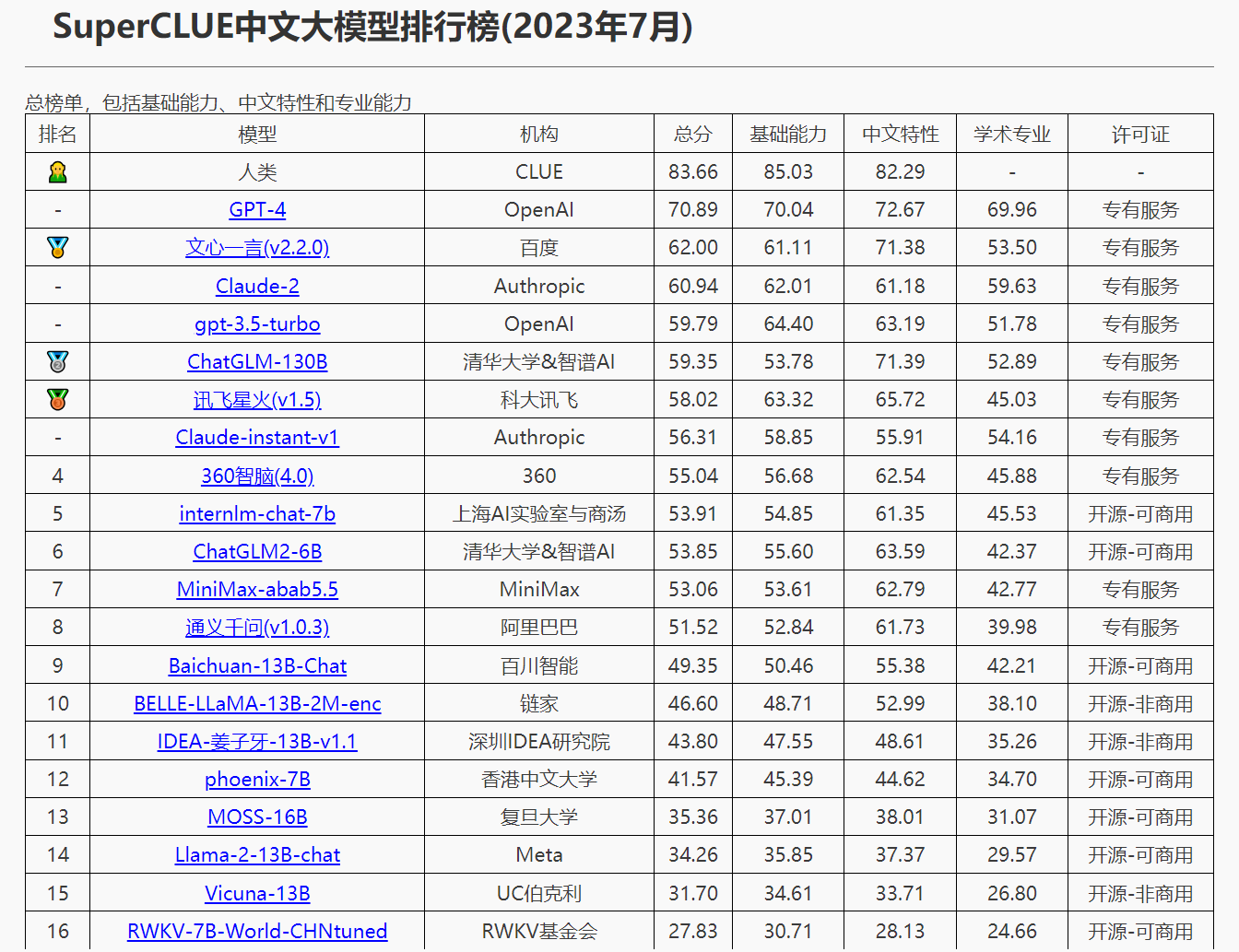
从榜单结果可以看出,虽然国外GPT-4效果较领先,但国内GPT模型也有不俗表现。在中文领域,国内研发的大模型在部分维度表现突出,整体在逐步缩小与国际先进模型的差距。整体来看,国内大模型中百度文心一言表现最优。文心一言v2.2.0版背后搭载的是文心大模型3.5,文心大模型自2019年3月发布1.0版后,现已升级到3.5版。新版本模型效果提升50%,训练速度提升2倍,推理速度提升30倍。
据了解,这次评榜的SuperClue是一个由国内发起的大模型榜单,是中文领域权威测评社区。相较于国外的UC伯克利LLM排行榜和斯坦福排行榜AlpacaEval两个流行榜单,多了一些国内大模型,更加适合国内用户来横向比较。作为针对中文可用的通用大模型测评标准,SuperCLUE使用多个维度能力对一系列国内外代表性模型进行测试,因其为封闭式问题,对大模型来说是“闭卷考试”,测评更难。
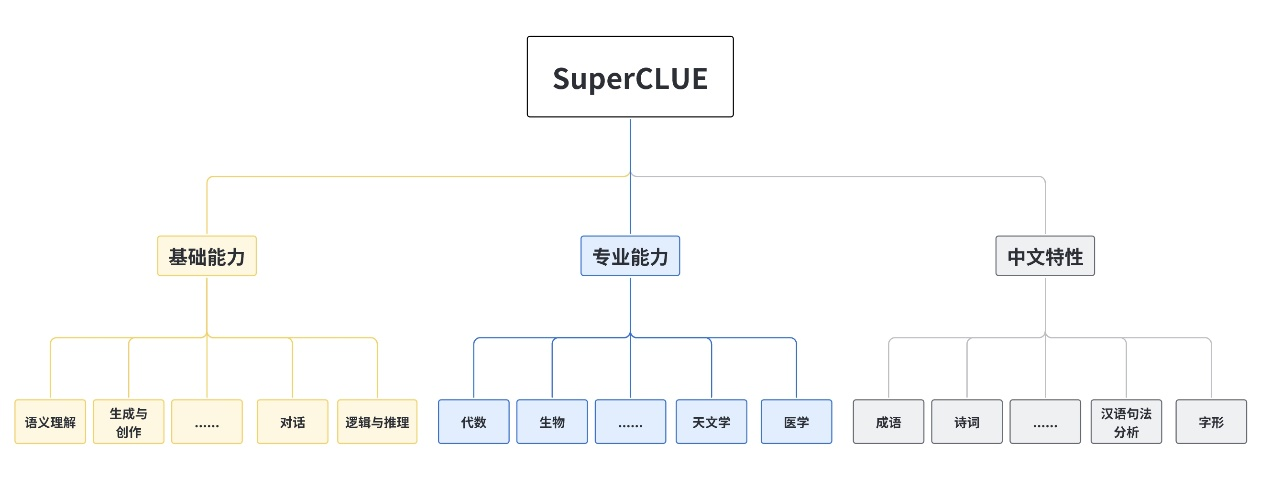
评测基准中,基础能力包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色扮演、代码、生成与创作等10项能力;专业能力包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力;中文特性能力包括了中文成语、诗歌、文学、字形等10项多种能力。
值得一提的是,全球领先的IT市场研究和咨询公司IDC最新发布《AI大模型技术能力评估报告,2023》显示,百度文心大模型3.5拿下12项指标的7个满分,综合评分第一,算法模型第一,行业覆盖第一,其中也是算法模型维度的唯一一个满分 。
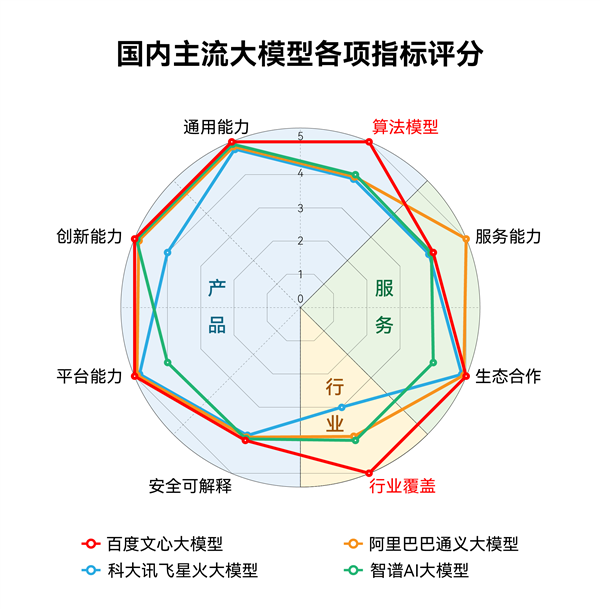
另据近期多个公开测评显示,文心大模型3.5版支持下的文心一言中文能力突出,甚至有超出GPT-4的表现;综合能力在评测中超过ChatGPT,遥遥领先于其他大模型,稳居国内第一。
来源:数据猿
刷新相关文章


































































































我要评论
不容错过的资讯












大家都在搜





