
【金猿技术展】一种基于词嵌入的文本分类训练样本扩充方法——用于提高小样本分类任务中自动扩充数据的质量
数据猿 | 2024-01-10 22:19
【数据猿导读】 该技术由中新赛克投递并参与“数据猿年度金猿策划活动——2023大数据产业年度创新技术突破榜单及奖项”评选。

设计并实现了一种基于词嵌入的文本分类训练样本扩充方法。本技术所述的基于词嵌入的文本分类训练样本扩充方法发明了一种利用已有样本数据来自动高效得扩充已有样本中样本量偏小的类。该方法主要创新点:一是利用文本外的词来扩展已有的训练样本,使得新增样本中的词的表达更具丰富性;二是利用K最近邻文本分类将基于词嵌入所生成的候选样本进行筛选,剔除掉无关的、错误的候选训练样本,获得高概率的可用训练样本,达到扩充训练样本的目的。
本技术的应用价值在于缓解了简单样本扩充和提高分类器算法效果不理想问题。文本分类是一种典型的有监督学习问题,有监督学习面临的一个主要问题就是需要通过大量的人工标记的训练样本来进行学习。然而在实际应用中,获得有标签的训练样本通常需要耗费巨大的人力物力,这就是所谓的“标注瓶颈”。因此,有监督学习所能获得的有标签的训练样本往往是有限的,它表现为训练样本的数量有限,以及训练样本所包含的信息不足。由于有限(数量和分布信息有限)的训练样本不能很好地刻画出数据的总体分布特性,因而导致学习得到的分类器泛化能力差,这就是所谓的“小样本”问题。本技术正是针对这种“小样本”问题所提出的一种有效解决方案。
本技术可以广泛应用于各类文本分类任务中,从而提高分类的精度。分类任务包括但不限于:情感分类、新闻主题分类、垃圾邮件过滤、产品评论分类、聊天意图分类、健康疾病分类、政治倾向分类、法律文件分类等等。
技术说明
本技术具体实施例的详细步骤如下:
第一步,获取小样本关键词,构建小样本关键词集合。如图1所示,文本分类训练样本集分为小样本类和非小样本类。小样本类经过关键词提取获得关键词集合。本实施例中,获取关键词的方法采用PositionRank算法。PositionRank提取关键词算法与TextRank算法相似,都是基于PageRank的图关系计算词的得分。用表示词的重要性得分,其公式如下:
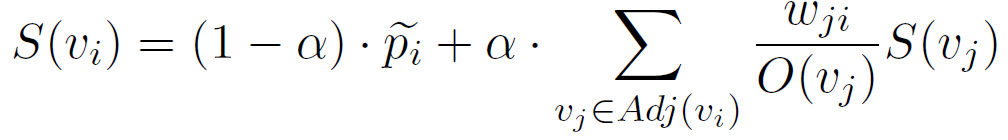
其中,表示阻尼因子,一般设为0.75;w表示图的边的权重,即词之间的相似度;表示词所有出向边的权重和。词的初始得分跟词在文本中的位置成反比,跟词频成正比:
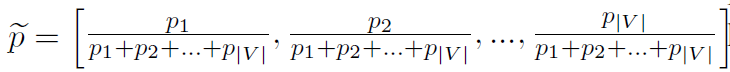
假定词v在文本的第2、第3、第8位置出现,则 =1/2+1/3+1/8。
如图2所示,一篇文本分词后,得到A、B、C、D 、E、F 6个词,经过PositionRank算法后,A、B、C、D、E、F各词的权重分别为0.025、0.34、0.12、0.036、0.032、0.047,然后从该篇文本选3个关键词,得到权重靠前的3个关键词:B、C、F。实施中,每一篇文本所选取的关键词个数与文本自身长度n有关,用f(n)表示文本需要选取的关键词个数,其表达式如下:
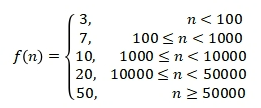
第二步,将非小样本类的所有文本分词,随机抽掉一半的词,并从小样本关键词集合中有放回地随机选取相应数量的词,替换非小样本类文本中被抽掉的词,形成新的语段。分词算法采用中科院的ICTCLAS中文分词实现。
第三步,用文本相似度计算新语段与已知训练样本的K最近邻。两文本相似度采用DSSM模型计算。DSSM (Deep Structured Semantic Models)的原理是,通过搜索引擎里查询和标题的海量的点击曝光日志,用 DNN (深度神经网络)把查询和标题表达为低维语义向量,并通过 余弦距离来计算两个语义向量的距离,最终训练出语义相似度模型该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
如图3 K最近邻算法分类新语段所示,训练样本集包括3个类别:类1、类2、类3,在K=5时,与待分类新语段最相似的前5个类分别是类1、类1、类1、类2和类3,由于类1数量最多,所以把待分类新语段归为类1。实施中,K的个数与小样本量有关,设定K=,其中是一个超参数,根据经验来设定,表示下界取整,如。
第四步,将经过K最近邻分类后归为小样本类的新语段筛选出来,与文本分类训练样本集合并,形成扩充后的训练样本集。

图1文本分类训练样本扩充流程
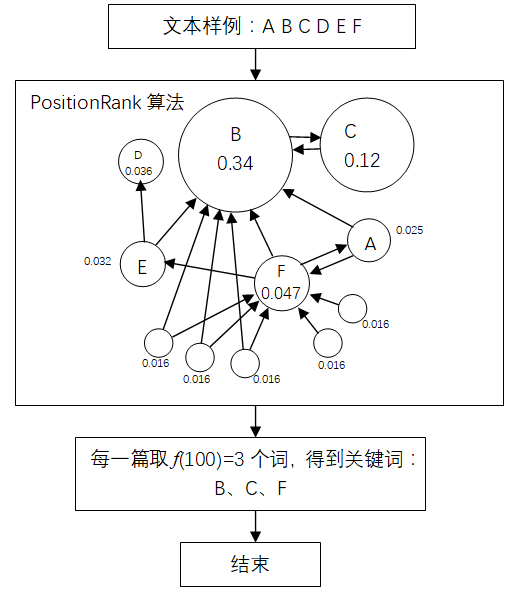
图2 基于PositionRank算法的关键词抽取图
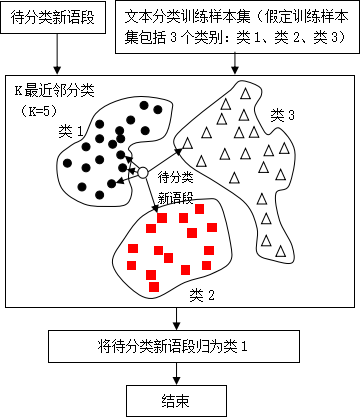
图3 K最近邻算法分类新语段
★专利申请号/公开号:ZL 2019 11119076.5
开发团队
·带队负责人姓名:卢云川
卢云川,中新赛克副总兼大数据产品线总经理。清华大学硕士,高级工程师,现任中新赛克大数据产品总经理,中国数据库专委会委员,中国互联网网络安全威胁治理联盟成员单位负责人,南京市人工智能行业协会副理事长。在电信、大数据、人工智能领域深耕20余年,拥有知识产权5项,主导并参与国家242信息安全专项、江苏省战略性新兴专项等8项省部级科技项目。
团队其他重要成员姓名:张全、卓可秋
·隶属机构:OceanMind海睿思/中新赛克
南京中新赛克科技有限责任公司(简称:中新赛克)成立于2007年,前身是中兴通讯旗下子公司,现由深圳市创新投资集团有限公司投资控股。公司于2017年在深交所挂牌上市,股票代码:002912。
OceanMind 海睿思,是中新赛克旗下的大数据操作系统品牌。海睿思在业内创新性提出系统化、线上化数据建设解决方案,重新定义企业数据工程,提供基于业务驱动、线上化、可视化、无缝衔接的数据建设服务,即数据建设咨询→成果落地→应用建设→数据管理“四位一体”的数据建设一站式解决方案,成功解决企业咨询方案难落实、咨询成果难落地、数据应用难建设、数据体系难运营的四大难题,为企业数字化转型保驾护航。同时提供数据中台、智能数仓、主数据管理、指标管理平台及行业大数据业务分析应用,紧扣企业经营管理业务场景,深化运营状态可视、运营过程可视和运营风控可视的理念,打造企业经营管理数字化解决方案,不断助力企业数字化转型。
相关评价
中新赛克基于人工智能的审计档案挖掘利用系统,解决了一直以来我们应用电子版审计档案困难、档案价值难以挖掘的问题,大大提升了我们利用海量已有档案的效率,并在业内形成了良好的示范效应。
——聊城市审计局
电子数据科科长 宋鑫昌
中新赛克海睿思的智能搜功能,创新性的把自然语义能力加入到了全局数据、资料的搜索中,使得我们可以高效的基于实体要素,迅速的、结构化的提取原本分散在多个系统的数据,并可自动生成报告,极大减少了我们人员搜集材料、编写材料的工作量。
——中国能建江苏省电力设计院
IT经理 黄丕全
来源:数据猿
刷新相关文章
















































我要评论
不容错过的资讯















大家都在搜







