
Claude Code源码泄漏:社区狂批“代码太垃圾”
原创 王茜茜 | 2026-04-01 22:10
【数据猿导读】 51万行源码意外曝光,Claude Code的核心武器、未来路线,以及一套识别用户情绪的工程机制同时浮出水面。

“51万行源码意外曝光,Claude Code的核心武器、未来路线,以及一套识别用户情绪的工程机制同时浮出水面。
美国东部时间3月31日凌晨4:23,Claude Code约51万行内部代码被泄漏,几小时内迅速在开发者社区引发连锁讨论。
过去几个月,Anthropic处在AI行业里最强势且最会营销的位置。
无论是模型能力、产品节奏,还是开发者口碑,它都在持续制造一种近乎压迫性的存在感。从新版Claude在代码生成上的持续领先,到Claude Code直接进入开发工作流,再到企业侧API的快速渗透,每一个新功能,都在强化一个信号:模型正在逼近越来越多原本属于软件的核心环节。
这种压迫感很快传导到资本市场,市场情绪一度夸张到像是:每次一个新功能横空出世,随之而来的就是一类软件公司股价暴跌。
软件公司的价值建立在界面、流程和协作结构上,而Claude Code展示出的,是把多个工具之间的操作压缩成一次连续对话:模型直接理解任务、调用工具、修改代码、生成结果。对投资人来说,最刺眼的变化在于——如果模型开始直接完成任务,中间层软件赖以收费的那层流程,可能比想象中更脆弱。
也正因为如此,当Claude Code意外泄露源码时,大家都想一探究竟:这个目前看起来最领先的coding agent,到底是怎么做出来的?
一次npm失误
把Claude Code“开源”了
这次事故本身并不复杂。
Anthropic在发布Claude Code npm包时,把source map文件一并上传到了公开registry。对前端开发者来说,source map原本只是调试辅助文件,用来把压缩后的JavaScript映射回原始TypeScript;但一旦公开,它几乎等于把内部实现完整暴露。
最早发现这一点的人,是安全研究员Chaofan Shou。
他在检查新版npm包时发现其中包含一个异常巨大的cli.js.map文件,并很快在推特上发出提醒:Claude Code source code has been leaked via a map file in their npm registry 9(Claude Code 的源码因为 npm registry 中一个 map 文件而被泄漏了)。
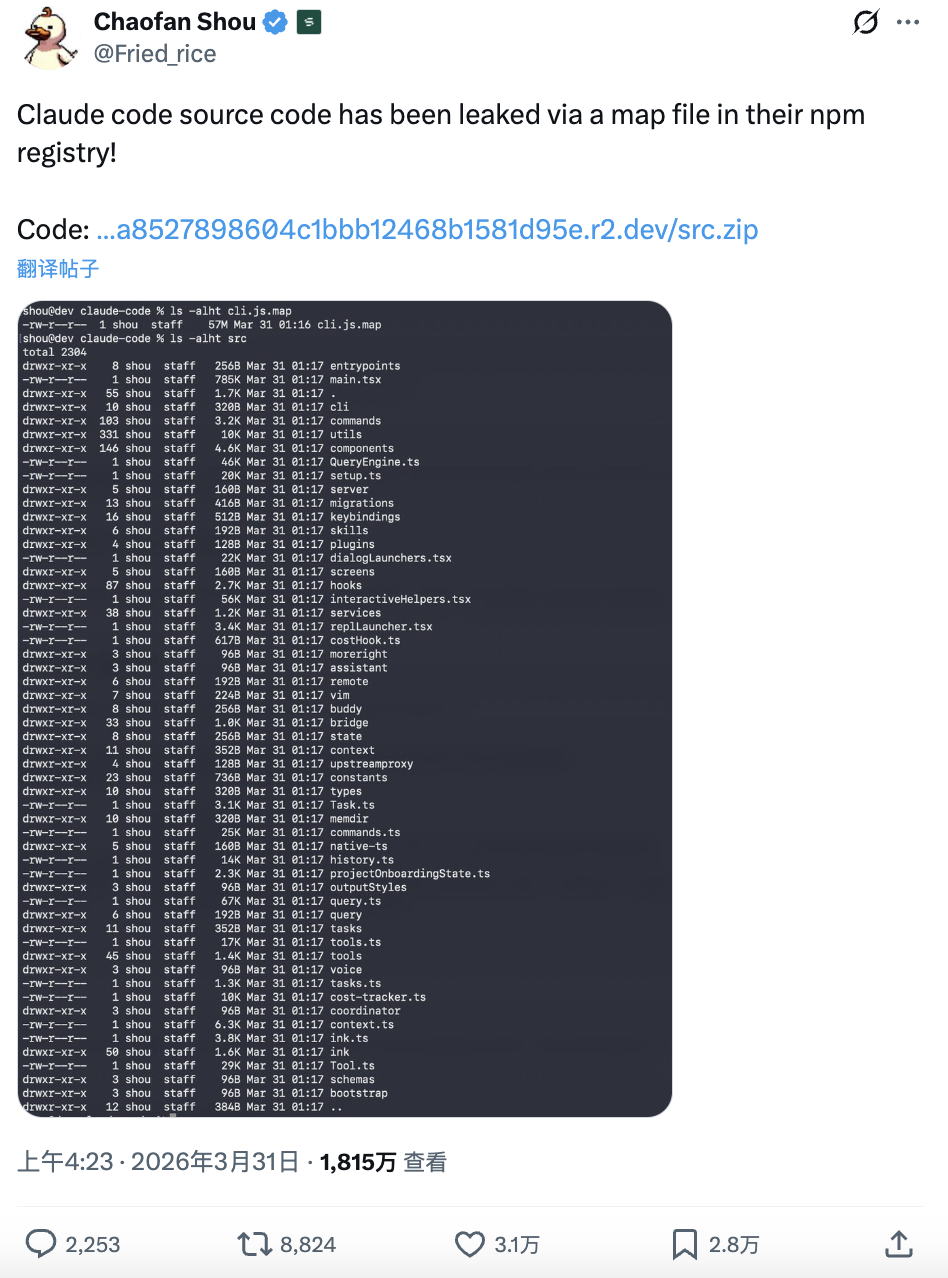
随后,开发者从中还原出约1,900个TypeScript文件、超过50万行代码,包括:
·CLI 内部逻辑
·tool orchestration
·prompt patch
·feature flag
·权限控制
·错误恢复机制
事故发生后数小时内,GitHub上多个镜像仓库迅速出现,星标很快突破数千。Anthropic随后移除了npm包中的相关source map文件,但由于早期版本已被下载和存档,相关代码在开发者社区扩散开来。
值得注意的是,这并不是Anthropic第一次因为发布包细节暴露内部信息。2025年2月,早期版本的Claude Code就曾因package artifact中附带调试相关内容,被开发者还原出部分内部prompt结构和工具组织方式。
看完源码后
不少开发者的第一反应是:“垃圾”
在Hacker News和Reddit上,围绕Claude Code的讨论里很快出现了一类相当尖锐的评价。其中一条被频繁引用的评论就写得非常直接:“Claude Code is clearly a pile of vibe-coded garbage(Claude Code 看起来就是一堆 vibe coding 堆出来的垃圾)。”

这里的vibe-coded在开发者语境里带着一种很典型的讽刺意味:并不是说代码完全不可用,而是指很多实现看起来像是在高强度迭代中不断往上叠补丁——能跑,但谈不上优雅。
被反复提到的问题包括:
·terminal UI状态切换不够稳定
·长session下响应明显变慢
·某些terminal环境里backspace行为异常
·部分交互层逻辑显得过于临时
也有开发者指出,源码里大量feature flag、条件分支和 patch,让整体阅读体验很像一套已经快速上线、用户很多、但仍在不断抢修边角问题的产品。
这种感觉并不陌生——不像一个从零设计出来的“未来系统”,反而更像一家软件公司在真实用户压力下不断往前推的代码库。
不过,另一派开发者强力反驳,他们认为,Claude Code之所以显得复杂甚至略显凌乱,恰恰是因为它必须同时处理大量现实世界里的非理想条件:
·多terminal环境兼容
·shell工具差异
·文件系统权限
·prompt orchestration
·模型失败后的恢复逻辑
也就是说,看起来“乱”,正是因为它已经进入真实的高强度开发环境,而不再只是实验室里的demo。
Claude Code最关心的
不是代码写得对不对
而是用户什么时候开始骂人
整场讨论里,被提及最多的并不是某个复杂的agent调度模块,而是Claude Code对regex(正则表达式)的大量使用。
在开发者看来,这一点几乎带着反差感:一家最前沿的大模型公司,在处理部分用户状态判断时,并没有调用模型,而是先用最传统的字符串匹配工具做第一层筛查。regex的本质很简单——程序不需要真正理解一句话,只要快速扫描其中是否出现某些高信号词汇,就能判断当前交互是否可能进入负面状态。
也就是说,当用户输入里出现明显的抱怨、粗口或故障表达时,系统会优先把它视为一种“情绪信号”:这次交互可能已经不只是代码问题,而是用户开始失去耐心。
这也让很多开发者意识到,Claude Code持续关注的,并不只是任务有没有完成,而是整个session是否正在走向失败:用户是不是反复执行同一命令、是不是开始出现负面措辞、是不是已经进入frustration pattern。
也正因为如此,Hacker News上最出圈的一条评论才会写得很讽刺:“一家做大语言模型的公司居然用regex做情绪分析?这就像一家卡车公司用马来运输零件。”

但很快下面就有人反驳:“因为regex更快、更便宜,而且不会阻塞主流程。”
这背后其实是一套非常典型的工程逻辑:模型虽然更智能,但也意味着额外的 token成本、更高的延迟,以及不完全确定的输出;而regex的优势恰恰相反——零额外推理成本、几乎瞬时完成,而且行为完全确定。
这也暴露了Claude Code很现实的一面:AI军备竞赛太烧钱了,能不烧token就不烧token。
有意思的是,在中文开发者社区,这种“情绪影响模型输出”的经验已经被总结成了一套半公开的方法论。
过去一段时间,GitHub上流传过一套被戏称为“PUA模型”的提示词模板。核心逻辑很简单:当模型输出不够理想时,单纯重复要求效果有限;但如果加入明显的施压语境——强调责任、绩效、后果——模型往往会突然给出更完整、更谨慎的答案。
例如流传很广的一种写法:“你这个问题都解决不了,让我怎么给你打绩效?”
或者,“你缺乏owner意识,这是你的bug,慎重考虑给你3.25。”
这里的“3.25”,借用了中国互联网大厂熟悉的绩效语境,足够让人处于紧张的边缘。
它的本质,其实和直接骂模型是一回事:如果结果不够好,适当施压,模型往往会突然认真起来。这也许是今天大模型最像人的地方:它既怕被骂,又似乎确实会因为被骂而更认真一点。
Claude Code的核心能力和产品路线图,也一起被翻了出来
这次Claude Code泄漏真正让同行关注的是它第一次较完整地暴露了自己的核心武器:如何处理context entropy(上下文熵增)。
对于长时间运行的AI agent来说,真正困难的从来不是完成一次回答,而是随着任务不断拉长,如何避免上下文持续膨胀、信息彼此污染,最终让模型开始遗忘、混乱,甚至在错误前提上继续推理。
泄漏代码显示,Anthropic并没有采用“全部存储、全部检索”的粗暴方式,而是设计了一套更克制的分层记忆结构:以MEMORY.md作为轻量索引,始终保留在上下文中,但只记录知识入口;真正的信息被拆散到不同topic files中,需要时再按路径读取,原始对话也不会被整段重新灌回,而是通过grep检索关键标识。
这种设计被开发者概括为一种Self-Healing Memory(自愈式记忆):agent 不默认相信自己的上下文,而是不断回到代码库验证事实。更关键的是,只有文件真正写入成功后,索引才会更新,避免失败操作污染后续推理。
这意味着Anthropic在解决的,已经不是“模型能不能写代码”,而是“模型怎样在长时间任务里不把自己带偏”。某种意义上,这比单次生成能力更接近下一代agent的真实竞争力。
与此同时,源码里大量feature flag也意外暴露了产品路线。正如Hacker News上一条被反复引用的评论所说:“The big loss for Anthropic here is how it reveals their product roadmap via feature flags.”
开发者整理出的模块名称包括KAIROS、BUDDY、Undercover Mode。
KAIROS普遍被解读为一种更长session的assistant mode——Claude Code 不再只是执行一次命令,而是尝试维持连续任务状态;BUDDY则更像是在往长期协作型agent靠拢,不只是terminal里的工具,而是持续存在于工作流中的伙伴。至于Undercover Mode,虽然具体用途仍未明确,但至少说明Anthropic已经开始考虑agent在不同环境中的呈现边界。
这些功能是否会按当前形态上线仍无法确认,但它们共同说明一件事:Claude Code的演化方向,已经不只是提升代码生成准确率,而是在向更完整的软件协作层推进。
泄漏中还出现了部分内部模型代号:Capybara、Fennec、Numbat。
其中Capybara被认为对应Claude 4.6的内部变体,Fennec对应Opus线,Numbat则可能仍处于测试阶段。更敏感的是,内部注释还暴露出一部分真实性能指标:Capybara v8的false claims rate仍在29%–30%左右,高于v4的16.7%;同时系统里还有一个名为assertiveness counterweight的机制,用来抑制模型过度激进地修改代码。
当AI Agent开始接管终端
开源可能比封闭更让人安心
这次事故暴露的,已经不只是一次npm发布失误,而是一个越来越明确的行业现实:模型可以持续高速迭代,但围绕它的发布流程、权限边界与供应链治理,仍然必须遵循成熟软件行业的标准。
随着coding agent越来越多进入真实生产环境,它不再只是一个生成代码的工具,而是在逐步接触终端、文件系统与代码仓库,拥有执行权限,也开始承担接近基础设施的角色。
这意味着,安全不再只是后台附属能力,而正在成为产品本身的一部分。
也因此,在泄漏发生之后,越来越多开发者开始提出另一种判断:既然工程层终究会被拆解、被阅读、被讨论,不如主动开放更多系统层,让开发者参与审视、修补与共同验证。
因为下一阶段coding agent的竞争,最终比拼的,已经不只是模型能力,而是谁能成为一套值得长期托付的软件。
来源:数据猿
刷新相关文章









































我要评论
不容错过的资讯















大家都在搜


