
国家数据局出手,数据圈迎来“淘汰赛”?
原创 梦芸 | 2025-10-15 22:28
【数据猿导读】 国家数据局发布了首批104个高质量数据集典型案例。

“国家数据局发布了首批104个高质量数据集典型案例。
想象一下:无人机在云层间穿梭,地震台网实时汇聚信号,手术机器人通过影像学习精准操作,自动驾驶车辆在虚拟道路中反复训练——这一切背后,都离不开同一种“能源”:高质量数据。
大模型的发展,催生了高质量数据集的迫切需求。近日,国家数据局发布了首批104个高质量数据集典型案例。这些案例是从全国663个申报案例中精心遴选而出,覆盖了科学研究、工业制造、农业农村、低空经济、具身智能、智能驾驶、智慧海洋、生物制造等多个领域和多个省份。申报单位包括央企、国企、科研院所和民营企业等。
在数字经济与人工智能深度融合的大背景下,国家数据局的这一发布标志着我国数据要素市场化迈入了“深度应用”的新阶段。如今,数据已不再是“沉睡资源”,而是直接参与到生产、治理、科研中的核心要素。这也意味着,AI模型的竞争已进入“数据质量”的关键阶段,谁掌握了高质量、场景化、合规的数据集,谁就将拥有下一代AI应用的“燃料”。
什么是高质量数据集?
数据之于大模型,犹如石油之于汽车。汽车无法直接使用原油,原油必须经过一系列复杂的炼化过程,转化为汽油后,才能供汽车使用。同理,海量原始数据也需要经过“炼化”,形成高质量数据集,才能真正有效地应用于大模型训练。
数据集,亦称资料集、数据集合或资料集合,是由数据构成的集合。简而言之,数据集是围绕特定主题,通过系统化采集与结构化处理形成的可计算数据集合,其核心在于将碎片化信息转化为可复用的生产要素。
高质量数据集,是指经过采集、加工等数据处理流程,可直接用于人工智能模型开发训练,并能有效提升模型性能的数据集合。
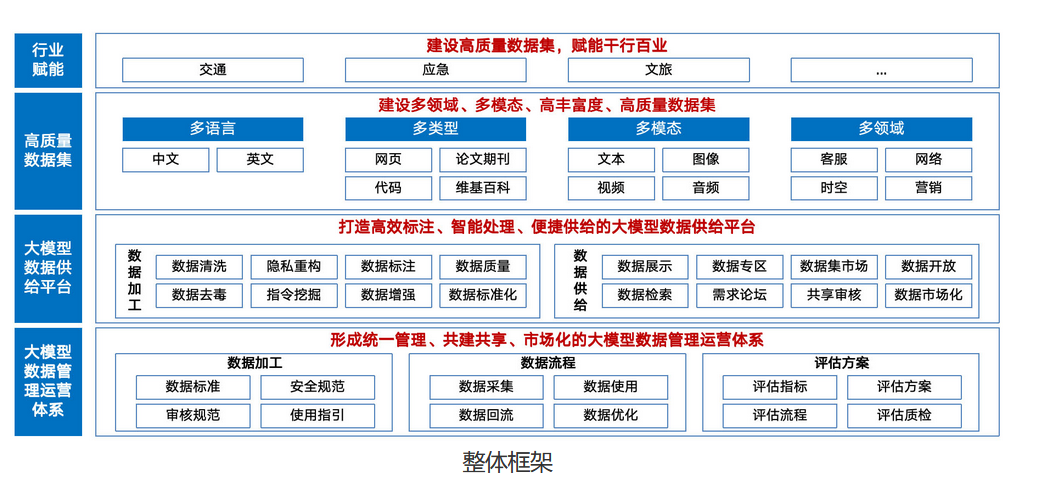
来源:国家数据局官网
在国内典型案例中,以通信领域数据集为例,中国移动通过整合运营商8类核心数据(如基站信号强度、用户行为轨迹),并融合政务、互联网等外部数据,构建起包含650TB多源数据的“九天大模型”训练集。这类数据集已超越传统数据库的存储功能,成为支撑行业智能化升级的关键基础设施。
截至2025年10月,我国在高质量数据集建设领域已形成从顶层设计到具体实施的多层次政策法规体系。这些政策由国家数据局、国家发展改革委、工信部等多部门联合推动,旨在夯实人工智能发展的基础,赋能“人工智能+”行动。
早在2022年12月,中共中央、国务院印发《关于构建数据基础制度更好发挥数据要素作用的意见》,首次提出数据质量标准化体系建设要求。2023年12月,国家数据局等17部门联合发布《“数据要素×”三年行动计划(2024—2026年)》,明确提出打造高质量人工智能大模型训练数据集。
紧接着,专项政策密集出台。2025年1月,三部委联合印发《国家数据基础设施建设指引》,提出制定高质量数据集全流程标准,明确标注、交付、授权等机制。2025年5月,《数字中国建设2025年行动方案》再次强调:加强交通、医疗、制造等重点领域数据标注,建设行业高质量数据集。
各地数据集工作,有哪些进展?
当前,我国高质量数据集建设已迈入规模化、标准化、场景化、生态化的崭新阶段。从国家级产业基地到地方行业专项工程,从央企到地方科研机构,各类主体正紧密围绕真实需求,系统性地打造高质量数据“燃料库”。
国家数据局“百城千集”高质量数据集培育计划(2025年启动),该计划目标是在三年内支持全国100个城市培育不少于1000个高质量数据集,涵盖智能制造、智慧城市、医疗健康、交通物流、能源环保等重点领域。目前,该计划已在北京、上海、深圳、南京、成都、武汉、西安、大连、昆明、苏州等城市率先开展首批试点。
例如,南京作为全国首个国家级数据集产业平台,该基地由国家数据局与江苏省政府联合共建,并已于2025年6月正式揭牌。基地重点聚焦技术研发中心、标准认证中心、产业孵化平台等核心功能。
在公共数据授权运营框架下,多地将“高质量数据集”作为核心产品形态。例如:
北京市依托“京通”平台,发布《城市运行高质量数据集目录》,涵盖交通流量、空气质量、市政设施等12类数据集,支持AI企业申请使用。上海市在浦东新区试点“医疗健康高质量数据集”,整合三甲医院脱敏电子病历及影像数据,用于辅助诊断模型训练。
那么,高质量数据集有哪些最新进展,有什么值得关注的趋势呢?为了搞清楚这个问题,我们从国家数据局发布的104个高质量数据集着手,来进行分析:
从目前国家数据局发布的104个高质量数据集来看,我国高质量数据集呈现出全国统筹、区域特色鲜明的发展态势。
1、数据量庞大,地域分布广泛
从总量来看,截至今年6月底,中国已建设高质量数据集超过3.5万个,总体量超过400PB,相当于中国国家图书馆数字资源总量的约140倍,涵盖医疗、制造、教育、交通、金融等20余个行业。从地域分布来看,首批104个高质量数据集典型案例覆盖了全国20多个省份,从东部沿海到西南边陲(下附图)。
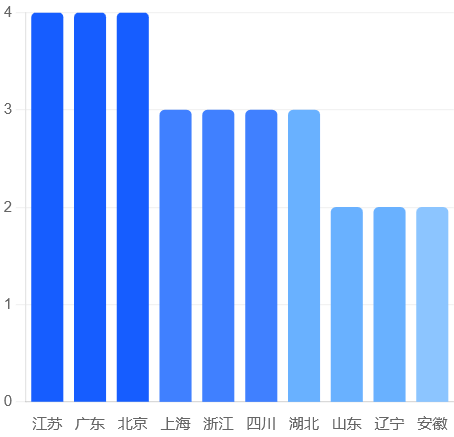
2、区域各有特色,地方数据成为新增长点
从已公布的104个高质量数据集典型案例来看,案例分布呈现出全国一盘棋、区域各具特色的数据发展格局。
江苏、广东、北京、上海、浙江等省市凭借其经济发展水平高、数字化程度领先、创新能力强等优势,在高质量数据集建设方面走在全国前列。
中西部省份同样表现不俗,且各有特色。
四川的地震监测预报预警多模态联合数据集、云南动物资源多模态高质量数据集的构建与应用、地球大数据创新青藏高原高质量数据集等项目,均展现了中西部地区在特色领域的优势,凸显了“数据+地域资源”的差异化竞争力。
例如,四川省数据局发布的地震监测预报预警多模态联合数据集;云南省数据局的云南动物资源多模态高质量数据集构建及应用项目。
3、应用场景拓展:前沿领域高质量数据集快速增长,垂直行业深度应用成为主流
从名单来看,高质量数据集正从通用领域向垂直行业深度渗透,医疗、金融、制造、交通、传媒等行业均在构建具有行业特色的数据集。例如,人民网股份有限公司申报的主流价值语料库,以及主流医疗领域已形成的从影像诊断到临床决策支持的全链条数据应用体系等。
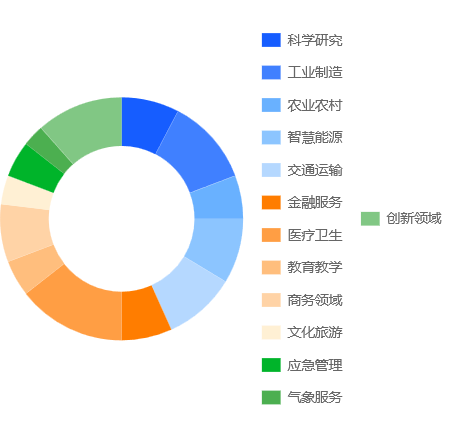
高质量数据集的行业领域分布
除传统领域外,此次数据集还披露了大量新兴领域的高质量数据,涵盖低空经济、具身智能、自动驾驶等前沿领域。国家数据局明确指出,将加速构建具身智能、自动驾驶、低空经济、生物制造等重点领域的数据高地,这些领域将成为未来高质量数据集建设的关键增长极。
在这些领域也涌现出不少有价值的数据集,例如,中国兵器工业集团有限公司提供的人形机器人具身操作数据集。
整体上看,数据集的行业细分更加垂直,前沿领域的数据库也在高速增长,跨领域融合应用正日益增多。越来越多的案例,凸显了不同领域数据融合应用的巨大价值。例如,通过将气象数据与电力负荷数据相结合,能够实现更为精准的电力需求预测;而将交通流量数据与商业数据相融合,则可优化城市商业布局等。
典型高质量数据集建设案例分析
基于国家数据局发布的“高质量数据集典型案例名单”或公开报道,以下选取几个不同领域的典型案例进行详细分析:
案例一:极端环境下的地球第三极多圈层数据集(中科院青藏高原研究所)
针对青藏高原极高海拔、极寒气温和极干旱的环境挑战,该数据集综合整合了卫星遥感数据、地面台站观测数据以及无人机采集数据,构建形成了规模达600TB的多圈层综合数据产品。

数据生产流程
此次案例的创新点之一,在于研发了多圈层智能观测融合技术。针对“地球第三极”地球系统的独特特点,将人工智能、数据同化与空天地一体化观测技术进行深度融合,有效提升了多圈层数据的时空连续性。由此,传统的点状观测方式得以跃升为广域智能监测,显著提高了高原极端环境数据的精度和分辨率。
二是构建了“多源观测+AI智能融合+数据同化”的数据智能生产模式。通过这一模式,生成了高精度、长时序、广覆盖的多圈层数据产品,精准对接国家重大需求;同时,引入国际期刊认证的数据出版流程,提升了数据资源的全球可信共享与影响力,增强了我国在气候变化应对和全球环境治理中的话语权。
该技术能够为川藏铁路建设提供沿线地质灾害预警,使隧道施工风险降低40%;同时,支撑雅鲁藏布江水电开发的生态影响评估,相关数据已被纳入联合国气候报告。
在国际层面,通过与世界气象组织(WMO)共建数据接口,服务全球120多个科研机构,显著提升了我国在第三极研究领域的话语权。
案例二:生命科学的DNA甲基化标准化数据集(中科院北京基因组所)

面向人群复杂特征的高质量DNA甲基化数据集概览
该数据集整合了18万例样本的甲基化数据,覆盖近300类人群特征,是全球规模最大的表观遗传数据库之一。
案例三:百度智能驾驶事业群一“Apollo高质量自动驾驶数据集"

百度智能云自动驾驶高质量数据集
针对自动驾驶技术商业化落地所面临的数据挑战,百度智能云在山西数据标注基地建立了具备甲级测绘资质的自动驾驶数据合规环境,打造了物理层面的“可信数据空间”,并建设了涵盖智能驾舱、道路采集等多元数据产品的综合体系。在确保数据安全合规的基础上,形成了规模宏大、场景覆盖广泛且安全可靠的高质量数据集。该数据集已成功服务于30余家知名车企及Tier1供应商。
其他高质量数据集的特色案例在此不再一一列举。实际上,这些试点与案例不仅验证了数据要素价值化的有效路径,也为广大企业提供了可复制、可推广的建设范式。未来,随着数据产权制度、流通交易机制以及安全治理体系的进一步完善,高质量数据集将成为推动人工智能与实体经济深度融合的核心动力。
当前面临的困境,与未来的方向
尽管建设取得突破,高质量数据集仍处在早期探索阶段。最大的问题不在数量,而在流通、标准、技术与信任。
首先,数据未能充分流动。目前公共数据以政务为主,产业端的核心数据仍处封闭状态,存在“不愿开放、不敢流通”的普遍顾虑。
其次,标准体系割裂。不同领域的数据格式、分类分级与质量评测标准不统一,形成新的“数据孤岛”。
第三,技术链薄弱。多模态清洗、自动标注、质量评测等环节仍依赖人工,智能化治理工具不足,AI驱动的数据引擎尚未成熟。
最后,合规与安全仍是痛点。数据权属模糊、可信流通机制欠缺,差分隐私与同态加密等技术尚未规模化落地。
正如中国信息通信研究院副院长魏亮所言,真正的瓶颈在于认知差距与治理能力。政府和企业尚未充分理解不同行业对数据类型的差异化需求,也缺乏面向大模型的系统化治理思维。数据采集、清洗、标注与评测环节成本高昂、缺乏统一准则,导致“高质量”难以被量化与验证。
本质上,AI竞争已从算法之争转向数据治理之争。未经淬炼的数据,只是原油;经治理的数据,才是智能的燃料。随着《“数据要素×”三年行动计划》的深入推进,数据质量的提升将决定中国智能产业的厚度与速度。
可以说,在智能时代,数据不再描述世界,而是在重写世界。
每一组高质量数据,都是一次对现实的抽象与重构;它们汇聚成模型的认知边界,也决定了人类理解世界的方式。
算法只是形式,数据才是内容。
未来的智能,不只取决于算力的堆叠,还取决于数据的真实、完整与丰富。当数据被精准地采集、净化、标注、归一,人类的知识体系正在被重新编译。
真正的智能,不在机器之中,而在我们如何构建让机器理解世界的那份秩序。这104个数据集,只是新的秩序被书写的序章。
也许,冷静、庞大、无声的变革,已在数据深处开始运转。
来源:数据猿
刷新相关文章















我要评论
不容错过的资讯















大家都在搜


