
从四大巨头的竞赛 看中国通用大模型的突围之路
原创 珞珈山人 | 2025-07-22 20:43
【数据猿导读】 从阿里巴巴的通义千问到字节跳动的豆包大模型,再到百度的文心一言和腾讯的混元大模型,大厂们纷纷推进技术创新和商业落地。在数智化转型浪潮中,这四家立于潮头的企业是整个中国通用大模型的缩影。通过梳理这四家代表企业的战略布局、产品创新、资金研发投入及市场表现,我们可以窥见中...

“当下,我们更需要大模型的“通才”还是“专才”?
2024至今,中国通用大模型领域正经历前所未有的高速发展与激烈竞争。
从阿里巴巴的通义千问到字节跳动的豆包大模型,再到百度的文心一言和腾讯的混元大模型,大厂们纷纷推进技术创新和商业落地。在数智化转型浪潮中,这四家立于潮头的企业是整个中国通用大模型的缩影。
通过梳理这四家代表企业的战略布局、产品创新、资金研发投入及市场表现,我们可以窥见中国企业如何迎接挑战与机遇,又如何在全球AI竞赛中摸索前进。
中国通用大模型 巨头的竞速
“数智化转型”代表着数字化、网络化与智能化的深度融合,旨在驱动经济社会范式的根本性变革 。
在这一转型浪潮中,通用大模型已成为核心驱动力, 通用大模型模型参数量往往在百亿到万亿之间,接受过系统“通识教育”的全才。通过微调或提示工程,通用模型可以执行包括文本生成、翻译、问答、代码生成、推理在内的多项任务。
2024年至2025年被视为通用大模型发展的关键时期,标志着该领域从技术探索阶段迈向规模化应用阶段 。市场数据显示,中国AI大模型市场规模在2024年已达到约294.16亿元人民币,并预计到2026年将突破700亿元人民币 。这种高速增长不仅体现了企业和消费者对AI技术日益增长的采纳度,也预示着大模型技术正从实验室走向广泛的商业实践。
市场扩张的背后,是国家层面的战略引导和地方政府的积极支持。“AI+”战略已被写入政府工作报告。在地方上,北京、上海、杭州、厦门等多个城市陆续出台鼓励人工智能发展的政策。
同时,开源生态的繁荣成为中国技术突围的关键路径。以阿里通义实验室为例,其阿里已开源200多款模型。而通义千问Qwen衍生模型数量已突破10万,超越美国Llama模型,成为全球第一AI开源模型。

强有力的政策支持和开放的环境,推动中国大模型领域的技术发展趋势与全球前沿保持同步,并在多个方面展现出独特的适应性与创新。
阿里的通义千问正积极布局多模态基础模型 ,剑指构建“云-模型-应用”全栈AI布局,并积极拥抱开源;字节的火山引擎,用极致性价比与规模效应猛冲,张一鸣亲自参与AI战略制定,以激进的低价策略抢占市场份额,推动模型和应用的大规模普及;百度喊出“All in AI”口号,基于原有业务如百度搜索、智能驾驶等进行布局;腾讯的混元大模型则将大模型的研发与能力和腾讯业务深度结合,广泛应用于微信、QQ、腾讯元宝、腾讯会议、腾讯文档等核心产品。
过去一年,中国通用大模型领域的竞争格局日益激烈,以阿里巴巴、字节跳动、百度和腾讯为代表的科技巨头,正通过差异化的战略布局和产品创新,在技术前沿和商业落地方面展开全面竞速。
阿里巴巴的通义千问(Qwen)围绕“云-模型-应用”全栈AI战略,专注于多模态基础模型和AI智能体研发,旨在构建端到端的AI解决方案 。产品创新方面,通义千问发布了包括Qwen2.5-VL(视觉理解)和Qwen2.5-Max等模型,并不断优化文生图模型,如通义万相2.1已于2025年1月升级推出视频生成模型,并在权威评测榜单VBench中位居榜首 。
2025年3月,阿里巴巴发布并开源了轻量级智能体QwQ-32B,其能在消费级GPU上运行,这符合全球模型效率提升和广泛部署的趋势 。面向消费者市场,夸克App作为阿里巴巴AI To C的核心产品,整合了对话、深度思考、搜索、研究、执行等多元AI功能,成为其用户触达的重要载体 。
值得注意的是,阿里巴巴集团宣布未来三年将持续投入超过3800亿元人民币(折合数百亿美元),用于云和AI硬件基础设施建设,创下中国民营企业在该领域有史以来最大规模的投资纪录 。市场表现方面,通义千问Qwen3开源仅一个月,全球累计下载量便突破1250万次,成为近期最受欢迎的开源模型之一 。
其旗下夸克App在2025年1月的平均日活跃用户(DAU)达到3369万,位居中国AI应用榜首 。阿里云(包含通义千问)在中国模型调用量市场中约占19.3%的份额,并在2024年中国AI基础设施(AI IaaS)市场中以23%的份额位居第一 。
字节跳动的豆包大模型采取“极致性价比与规模效应”的激进策略,在市场上攻城略地。在2025年3月的日均Token调用量达到12.7万亿次,同比增长近100倍。其在中国公有云大模型服务调用量市场份额高达46.4%,超越阿里云和百度智能云的总和,使其成为中国最受欢迎的AI产品之一 。
在其产品序列中,基于混合专家(MoE)架构的豆包·深度思考模型表现尤为突出,该模型总参数量达2000亿,但每次推理时仅激活200亿参数,值得注意的是,这个模型实现了低至20毫秒的推理延迟,并将推理成本较传统方案降低了80% 。
截至目前,豆包已支持超过50种应用场景,覆盖30多个行业 ,火山引擎成为少数逆势扩招的中国云厂商之一,拥有超过1万名产品和研发人员以及近2000名销售和运营人员 。
而喊出“All in AI”口号的百度,则将大模型与其原有业务紧密结合。百度搜索结果页中已有22%的内容由AI生成,文库、自动驾驶等同样成为百度的主要发力方向。数据显示,百度智能云的AI相关收入在2024年第四季度增长近300%,整体营收同比增长26% ,文心大模型在2024年12月的日均调用量达到16.5亿次,相较于2023年末增长了33倍,百度文库AI功能的月活跃用户数在2024年12月达到9400万,同比增长216% ,百度自动驾驶出行服务平台Apollo Go在2024年第四季度提供了110万次乘车服务 。
腾讯则依托其强大的内容生态,打造了国内首个多模态领域开源大模型。自2024年全面开源以来,混元大模型覆盖文本、图像、视频和3D生成等多模态。混元大模型作为国内首个采用MoE架构的万亿参数大模型,通过动态路由机制实现计算资源优化;通用任务调用3—5个专家模块,专业任务激活“15+”模块;推理效率较密集架构提升3倍,训练成本降低40%。
腾讯混元大模型在云上提供Turbo、Pro、Standard、Lite、Vision等多个版本,目前已接入700余个腾讯业务和场景(如腾讯元宝、腾讯云、QQ、微信读书、腾讯新闻、腾讯客服等)及腾讯旗下协作SaaS (软件即服务)产品,为业务赋能。以腾讯元宝为例,这款应用的日活跃用户在2025年2月至3月期间激增了20多倍。
数智化转型中的大模型赋能与产业变革
毫无疑问的是,通用大模型作为大模型的基石,正在多方面重塑中国的数智化转型,其影响深远且广泛。
借助混合专家(MoE)架构和先进注意力机制,大模型显著提升了生产效率与管理水平。例如,豆包实现了低至20毫秒的推理延迟和80%的成本降低 ,这直接将技术效率转化为实际运营效益,使得企业能够更快地做出决策并实现流程自动化。随着模型 “思考”能力的增强,大模型能够执行更复杂的逻辑、数学和规划任务,进而驱动产品与服务创新。通用大模型几乎已经成了“标配”,在工业、交通、能源等众多行业得到了广泛应用。
比如说,在政务领域,西湖区依托阿里云“通义千问”大模型开发的“西小服”AI专员,整合了全区17.6万家企业的数据标签,精准匹配政策并实现诉求的智能流转。通过“浙里办”入口,企业可实时获取政策推送、在线申报及进度查询服务。
在医疗领域,腾讯与明德医疗合作开发了全球首个针对重症监护病房的人工智能医疗模型,名为启元重症大模型,目前已在国内部分医院进行临床试验。
在能源领域的矿山安全场景中,文心4.5 Turbo准确识别掘进机作业画面中的误闯人员。该模型通过大小模型协作架构,在矿山边缘侧先用小模型初判,再触发大模型二次校验,实现准确率与经济性的平衡。
不只是在B端,通用大模型同时也在赋能C端应用的发展,阿里夸克、字节豆包、腾讯元宝已经牢牢占据了前三的位置。阿里夸克月活更是已经过亿,超级AI应用的锋芒已经显露。
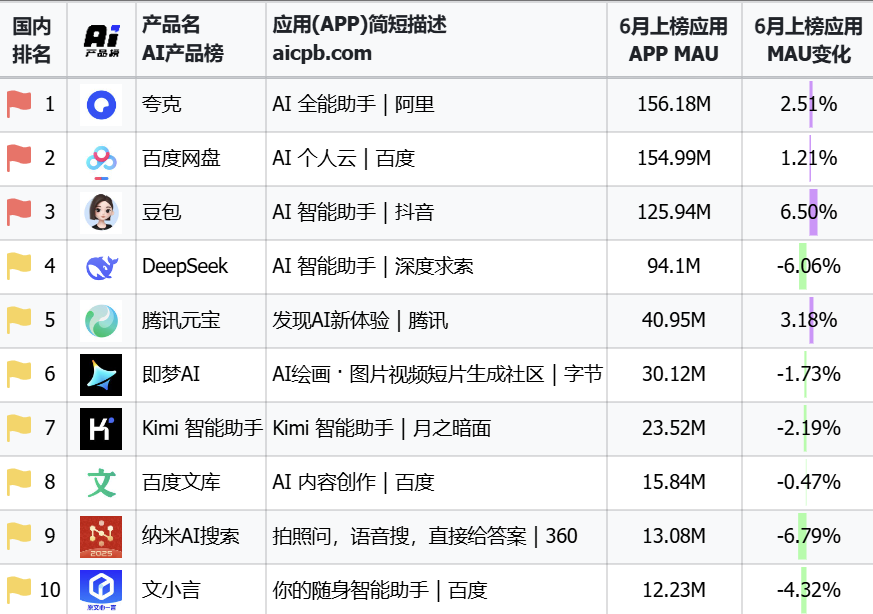
可以说,中国大模型行业正处于一个重要的战略机遇期,这背后是多重有利因素的汇聚:
中国拥有庞大的人口基数和快速发展的数字经济,为大模型提供了广阔的应用场景和用户群体。从消费级应用到企业级解决方案,各行各业对智能化升级的渴望,构成了大模型发展的肥沃土壤;
作为全球最大的互联网市场之一,中国积累了丰富的文本、图像、语音等多模态数据,这些数据为大模型的训练和优化提供了宝贵的“燃料”;
而国产化替代趋势,又为本土大模型企业带来了独特的发展机遇 ,随着中国对核心技术自主可控的需求日益增长,国内企业不断加大研发投入,推动底层技术创新,并积极构建自主可控的AI生态系统。
但不得不客观的说,通用大模型的发展并非一帆风顺,仍有多重挑战需要面对。
通用大模型的研发、训练和部署需要巨大的资金投入,尤其是在算力、人才和数据方面。然而,许多应用场景的商业化模式尚不成熟,投资与回报仍存在巨大的落差。另外,尽管通用大模型虽然看似是“通才”,但其在各行各业的落地往往呈现出零散、定制化的特点,企业需要强大的工具、服务和专业知识来在现有IT基础设施和业务流程中定制、集成和管理这些模型,使得大模型规模化落地变得困难。
不可忽视的一点是,这些巨头们在通用大模型领域的布局非常深厚,投入在人才、算力等方面的资金,是一个天文数字。这既是优势又是劣势,大模型技术路线不断发生着变化,正所谓船小好掉头,往往一个新技术的突破,就能瞬间消解巨头们的能力优势。最典型的就是Deepseek的横空出世,包括智谱AI、kimi等新兴力量的崛起,都在昭示着这么一个信息:通用大模型不只是巨头们的赛场。
中国大模型加速追赶国际领先模型
从2024年开始,我国头部大模型加速追赶国际领先模型(如GPT-4o、Claude 3、Gemini等)。在一些特定测试基准和中文能力上,国产模型甚至有所超越 。

由斯坦福大学李飞飞团队编撰《2025年人工智能指数报告》指出,美国在人工智能研究和模型开发领域长期占据主导地位,中国则稳居第二。然而,最新证据表明,这一格局正在快速变化,中国开发的模型正逐步赶超美国同行。2023年,美国领先模型的性能显著优于中国模型。在LMSYS Chatbot Arena平台上,2024年1月,美国顶尖模型的表现比中国最佳模型高出9.3%。但到2025年2月,这一差距已缩小至仅1.70%。2023年底,在MMLU、MMMU、MMATH和HumanEval等比较基准中,中美模型的性能差距分别为17.5、13.5、24.3和31.6个百分点。而到2024年底,这些差距已大幅缩小至0.3、8.1、1.6和3.7个百分点。然而,结构性差异依然存在。美国在复杂推理和数学能力上保持技术纵深,例如OpenAI的O1模型在理科任务得分达87.3分,显著高于中国模型的72.0分。
性能加速追赶的同时,成本优势急剧攀升。
数据显示,国产领先大模型平均每百万Token调用成本显著低于国际水平,平均为38.2元人民币/百万Token,而国际平均为158.3元人民币/百万Token,这意味着国产模型拥有近5倍的成本优势 。
换言之,国内企业能够以更具吸引力的价格提供性能相差不大的服务,尤其是在一个高度重视效率和实际应用的市场中。这种成本效益不仅促进了国内市场的普及,也可能对全球LLM API定价产生下行压力,从而加速基础LLM服务在全球范围内的商品化进程。
国产通用大模型领域的快速发展,正成为推动中国数智化转型的新引擎。尽管面临算力、数据、商业化等多重挑战,但政策的强力支持、市场的巨大潜力以及企业间的创新博弈,国产大模型有望在全球AI竞赛中占据更重要的地位。
来源:数据猿
刷新相关文章





































我要评论
不容错过的资讯















大家都在搜


