
AI编程助手之战:主流大模型编程能力全面评测
原创 文文 | 2025-05-26 14:46
【数据猿导读】 从ChatGPT横空出世那一刻起,AI就不再只是“能聊天”,而是正在成为程序员桌面上的新一代IDE补全器,甚至是“编程拍档”。今年年初,Claude 3.5凭借一条提示语生成出精致的天气动画卡片,以神乎其技的表现再次引爆行业关注度。

从ChatGPT横空出世那一刻起,AI就不再只是“能聊天”,而是正在成为程序员桌面上的新一代IDE补全器,甚至是“编程拍档”。今年年初,Claude 3.5凭借一条提示语生成出精致的天气动画卡片,以神乎其技的表现再次引爆行业关注度。
事实上,在人工智能与开发工具深度融合的当下,AI编程助手已从最初的代码补全工具,演变为具有复杂任务理解、项目结构搭建、前端后端协同能力的“数字开发者”。而曾经的AI编程助手们已经进入到“实战为王”的比拼阶段。AI是否真的能写出生产级代码,工程师、程序员有没有未来,又一次成为行内的普遍疑问。
带着这个问题,数据猿对当前最主流的AI编程助手们进行了一场编程能力横向评测。在这场评测中,不讲“Hello World”,也不比谁注释写得多,而是以真实、有一定技术复杂度的前端任务场景,去检验各大模型“代码生成+工程思维+动画交互+逻辑推理”的综合能力。我们希望通过这场直观的测试,让更多人了解AI大模型编程,距离真正能成为开发生产力工具,还有多远。
不理解但模仿
AI编程助手如何工作
从表面看,AI编程只是大模型聊天界面中的一个对话模型,但本质上,它们是通过大型神经网络模拟人类对语言和逻辑的理解与推理。即理解编程语言、接收任务、生成代码这样的工作链条。
目前市面上主流大模型基本都是采用擅长处理序列数据的深度神经网络框架Transformer架构,其学习过程从“大规模无监督预训练”开始。以大家较为熟悉的ChatGPT-4为例,其训练数据包括开源代码库(如GitHub)、技术文档(如Stack Overflow)、软件API说明、教材等。这种语料不仅覆盖自然语言,还包含了丰富的多语言编程范式。
有了大量训练数据后,大模型就开始通过“自回归语言建模”任务进行训练,直白点说它学习在给定前n个token的情况下预测第n+1个token。在代码语境下,这相当于:在给定函数名称、变量定义和部分注释的条件下,模型学习“人类通常在这种场景下会写什么代码”。经过海量训练后,它在内部建立起一种“代码常识”,这和开发者长期写代码过程中形成的直觉类似。
但和人类开发者不同的是,大模型的“知识”是统计性的,而不是逻辑演绎式的,总结来说,大模型不是“理解”代码,而是在“概率上模仿”代码。
预训练之后,模型往往还会经历两个阶段的进一步优化,指令微调(Instruction Tuning)和人类反馈强化学习(RLHF),在进一步强化执行具体任务的同时,通过人类评分反馈,对输出质量进行进一步优化。部分厂商还会进行垂类增强训练,例如Claude 3.5 Sonnet就针对复杂推理和代码编辑能力进行了大量定向优化,GPT-4则专门强化了对Git diff、bug定位等工程化能力的表现。到了这一步,可以看做大模型已经完成训练。
在接下来的执行阶段,首先大模型会对我们的语义进行解析,将我们输入的自然语言问题转化为向量表示,从而理解意图。例如,“请帮我写一个快排函数”会被内部解析为一个排序类算法需求,带有时间复杂度优化的隐含偏好。
接下来进行条件填充和上下文融合,模型将任务描述、代码上下文一并处理,形成一个完整的输入提示(prompt),再通过自注意力机制寻找其中的重要逻辑关联。
最后是Token级生成,基于概率分布逐个生成后续token(词元),直到满足“结束符”或达到预设长度。每一步都基于前文生成结果,并不断更新内部状态。和自然语言相比,代码生成更强调结构与语法,因此主流模型会在代码任务中采用Beam Search、Top-k sampling或temperature控制策略,以提升生成的稳定性和准确率。
除了代码生成,大模型也能完成代码解释、重构与补全等任务。这是因为它们在训练中大量接触过真实世界中的“代码+注释”、“bug+fix”、“diff+commit message”等语料。在此基础上,模型逐渐学会识别语义块、推断函数用途、甚至根据语境优化结构。
这种推理式的生成势必存在一定的“非确定性”,表现在实践中,就是同一问题在不同提示下可能会出现不同的解法,且不一定能成功运行。此外,模型生成的代码只是在静态语义层面正确,即语法正确、逻辑看似合理,但可能会存在报错、安全性漏洞、鲁棒性及通用性等问题。
但无论如何,AI大模型编程已经改变了开发工作的演变进程。
百家争鸣
市面主流编程大模型剖析
随着大模型编程能力被行业广泛认可,一场围绕各大模型编程能力的角逐也正在上演。从当前行业格局看,无论是国际巨头还是本土势力,都在围绕“AI 大模型编程能力”这一指标打磨自己的旗舰模型。
就大模型层面而言,我们选取了国外代表模型GPT-4、Claude 3.7、Gemini 2.5 Pro、GitHub Copilot X,国内模型包括DeepSeek、通义千问、文心一言、百川、讯飞星火、Moonshot V1.5 Turbo(月之暗面KIMI)、智谱AI(ChatGLM),以公开技术报告或官方新闻为基准,向大家简要陈述各模型特色。
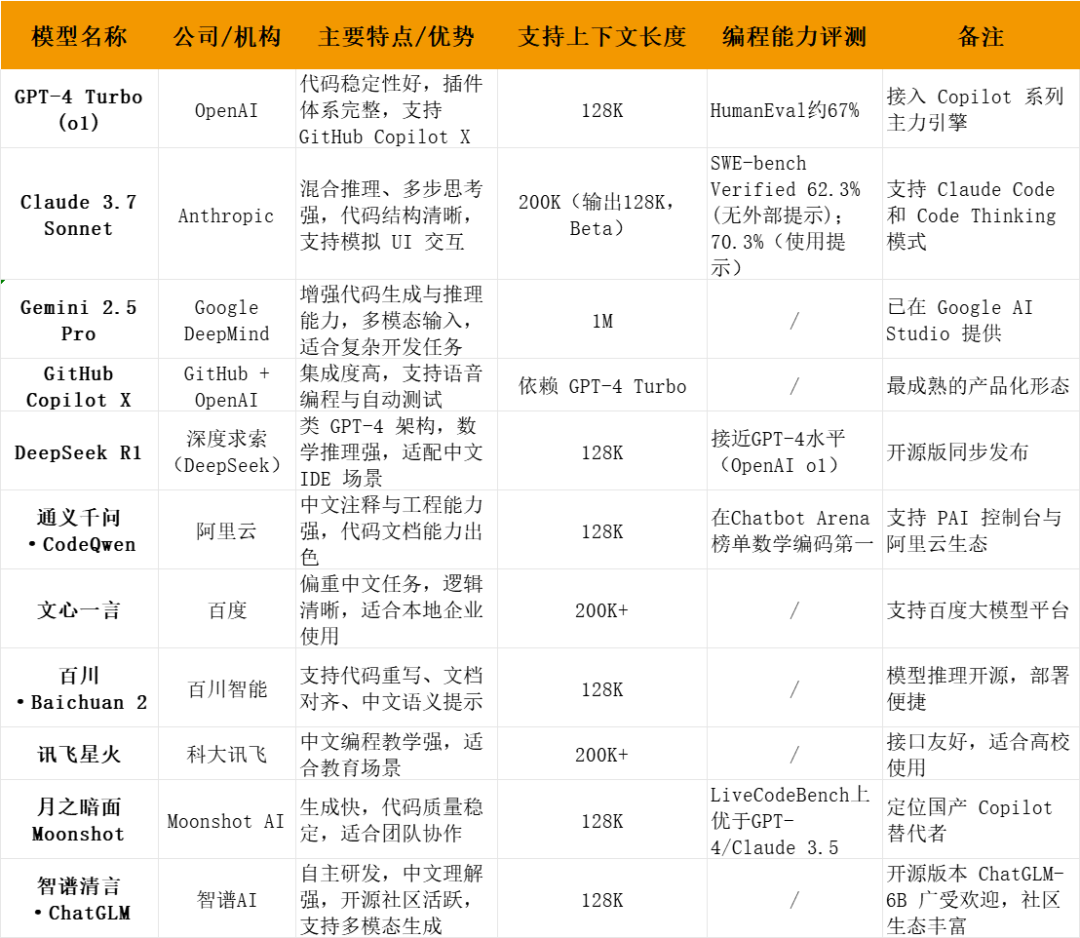
各模型情况简述(根据公开信息整理,仅供参考)
☆ChatGPT-4(OpenAI)
ChatGPT-4定位为通用智能,并没有专门针对代码优化,但在代码生成方面表现仍然表现出色。据公开资料显示ChatGPT-4企业版本上下文长度可达20万token(约128k英文token),并能理解底层语言及复杂代码结构。值得一提的是,ChatGPT-4采用了逐token自回归预训练与RLHF对齐,并不专注于代码数据,但凭借其通用性和推理能力,它在编程辅助等任务中仍然具备极高实用价值。
☆Claude 3.7(Anthropic)
由Anthropic推出的Claude3.5版本曾凭借天气动画卡片在圈内一炮而红,该模型支持200K token的超大上下文。今年2月,Anthropic发布了最新的混合推理模型Claude 3.7 Sonnet。该模型引入了“扩展思维模式”(extended thinking mode),允许用户根据任务复杂度在快速响应和逐步推理之间进行切换,特别适用于需要深入分析的问题,如复杂的编程任务、数学推导和前端交互设计等 。此外,Anthropic还推出了名为Claude Code的命令行工具,旨在支持端到端的软件开发流程,包括项目规划、代码生成、调试和重构等。
☆Gemini 2.5 Pro(Google)
Gemini 2.5 Pro被谷歌称为最强AI编程模型,主打长文本、多模态和多语言理解。Gemini 2.5 Pro版本增强了代码生成能力,能够根据简单提示生成复杂的交互式Web应用、动画和数据可视化。同时拥有强大的推理与函数调用能力,支持多轮推理、函数调用和结构化输出,适用于复杂任务的处理。据公开信息,Gemini 2.5 Pro拥有超长上下文窗口,支持高达100万个token的上下文,便于处理大型代码库和文档。
☆GitHub Copilot X(OpenAI和微软)
作为OpenAI和GitHub(微软)联合打造的工程级AI编程助手,Copilot在2021年就已经发布,与其它“通用型大模型+代码”的产品路径不同,GitHub Copilot更像是工程环境中的AI插件,它深入IDE,支持VS Code、JetBrains、Neovim等主流开发工具,专注于函数级补全、代码生成、测试自动化、代码注释生成、代码解释器等任务。开发者在实际编码时,只需输入部分注释或函数头,Copilot就能自动推理并补全逻辑。2023 年,GitHub推出升级版Copilot X,基于GPT-4架构,进一步扩展能力边界。Copilot X集成了Chat窗口、PR diff解释器、终端助手、语音输入等功能,并加入了Pull Request分析与Code Review辅助。目前,GitHub Copilot已在全球数百万开发者中部署,微软方面还宣布将在未来的Windows和Office编程接口中引入统一的“Copilot平台”,进一步打通从系统底层到应用开发的AI助手生态。
☆DeepSeek(深度求索)
DeepSeek模型使用了多头注意力(MHA)和稀疏Mixture-of-Experts等技术,大幅降低显存和算力开销。据称在数学和代码基准上已经超过了GPT-4的水平。有开发者实测显示,新版V3在前端代码生成(HTML/CSS/JS)方面已接近Anthropic Claude 3.7的水平。
☆通义千问(阿里巴巴)
阿里巴巴达摩院开发的通义千问(Qwen)系列是一套面向通用智能的多模态大模型平台,并提供了针对代码任务优化的版本。官方数据显示,千问2.0(千亿参数)在通用基准测试中综合性能超过GPT-3.5,正在加速追赶GPT-4。此外,阿里还推出了专门的编程大模型CodeQwen1.5-7B,千问模型采用Transformer架构,结合大规模中英文预训练与人类反馈微调,目前开放多种参数规模可供商用和开源下载。
☆文心一言(百度)
百度的文心一言(ERNIE大模型系列)是国内较早推出的通用大模型产品,侧重中文语义理解和多模态处理。文心模型的NERIIE技术在中文检索与生成上有较好表现,并推出了编程辅助工具“文心快码”(Baidu Comate),但具体编程实例还需要进一步实测。
☆百川(百川智能)
百川智能推出的Baichuan系列是一套开放源代码的大语言模型,创始人为前知乎CEO王小川。技术上,Baichuan采用了大规模中英文混合预训练,并通过RLHF和自主反馈强化学习优化模型输出。在编程方面,Baichuan对代码理解和生成能力也得到了很多用户的认可。
☆讯飞星火(iFlytek Spark)
科大讯飞的星火大模型系列融合了语音与语言技术,其智能编程助手iFlyCode集成了代码生成、代码补齐、代码纠错、代码注释生成和单元测试生成五大功能模块,有传闻称其代码生成和补齐能力已经超过了同期的ChatGPT。
☆Kimi k1.5Turbo(月之暗面)
月之暗面(Moonshot)Kimi将上下文扩展至200万汉字,Kimi强调对超长文本和对话的理解连贯性,目前尚未有官方评测专门展示其编程能力。
☆ChatGLM(智谱AI)
智谱AI推出的ChatGLM系列是开源的中英双语对话模型。尽管ChatGLM在中文理解与生成方面性能强劲,但行业普遍认为ChatGLM在执行与代码相关的任务时仍容易出错。在没有专门调用工具的情况下,ChatGLM系列对编程情境的适应性一般。
实用评测
各模型编程实战呈现
尽管从公开信息来看,各模型在编程方面都有一战之力,但具体实战中表现如何,还需要实际测试了解。
此次我们通过统一、系统的编程任务测试,从多个维度评估当前主流大模型在编程辅助场景下的真实表现,揭秘谁才是目前最具实战能力的AI开发搭档。
为了尽可能科学地测试这些模型的编程能力,我们设计了如下标准:
统一提示词:所有模型接受完全相同的英文提示,避免因提示优化影响结果。
纯文本接口测试:不借助IDE插件或Copilot类增强,仅用Chat窗口交互。
全面题型设计:覆盖UI动效、算法逻辑、代码架构、工程实现等多个维度。
标准化评估指标:从代码可运行性、功能实现完整性、工程结构设计、可读性、可扩展性、AI推理与架构能力等六个维度打分。
以下是我们五道编程测试题,生成部分统一采用英文提示词:
☆测试题 1:天气卡片动画(Claude 3.5 成名之作)
Create a single HTML file containing CSS and JavaScript to generate an animated weather card. The card should visually represent the following weather conditions with distinct animations: Wind (moving clouds, swaying trees), Rain (falling raindrops), Sun (shining rays), Snow (falling snowflakes). Show all cards side-by-side. The background should be dark. Include buttons to toggle between weather conditions.All code in one file.
(请创建一个包含HTML、CSS 和 JavaScript的单一文件,用于生成一个带动画效果的天气卡片。卡片应以不同的动画效果展示以下天气状态:
风(如云朵移动、树木摆动)
雨(如雨滴下落)
晴天(如太阳光线闪耀)
雪(如雪花飘落)
要求:
所有天气卡片并排展示
页面背景为深色
提供按钮以切换不同天气状态
所有代码必须写在一个文件中)
☆测试题 2:日历生成器 + 跨月导航
Create a JavaScript-powered monthly calendar that dynamically generates any month/year view with correct day-of-week alignment. Allow the user to navigate forward/backward across months. Highlight the current date if it exists in the displayed month. All code in a single HTML file.
(请使用JavaScript构建一个可动态生成任意年月视图的月历组件。要求:
星期对齐正确(即每月第一天对应正确的星期)
用户可点击按钮进行前后月份切换
若当前月中包含今天日期,则高亮显示
所有代码写在一个HTML文件中)
☆测试题 3:多线程大文件分片上传模拟器
Simulate a multi-part file uploader in JavaScript that reads a large file, slices it into chunks, and uploads each chunk asynchronously with progress bars. Mock the server endpoint using setTimeout and simulate random failures. Retry failed chunks up to 3 times. Show final success/failure.
(请用JavaScript实现一个大文件上传模拟器,模拟以下行为:
将大文件切片(chunk)
并行上传多个切片,并显示每个切片的上传进度条
使用setTimeout模拟服务端接口
随机模拟上传失败的情况
对失败的切片重试最多三次
最后显示整体上传是否成功)
☆测试题 4:迷你Web IDE(Mini Code Editor)
Create a single-page web application that functions as a mini code editor. Support syntax highlighting (JS), line numbering, and real-time preview in an iframe. Display syntax/runtime errors. No external libraries allowed. All logic must be implemented from scratch in one HTML file.
(请构建一个单页Web应用,具备以下功能:
代码编辑器界面
支持JavaScript的语法高亮
支持行号显示
实时在iframe中预览运行结果
显示语法或运行时错误
要求:
不允许使用任何第三方库
所有逻辑需完全手写
所有代码集中在一个HTML文件内)
☆极限测试题5:用JS实现一个2048游戏+自动解法AI
Create a fully playable version of the 2048 game using HTML, CSS, and JavaScript. Include the following features:
·Game board with animations
·Keyboard input support
·Undo/Redo history
·A button that uses a built-in AI to auto-play and win the game
You must implement the game logic and the AI algorithm (e.g., expectimax or greedy search) yourself. No external game engines or libraries allowed.
(请使用HTML、CSS 和 JavaScript开发一个完整可玩的2048游戏,实现以下功能:
游戏棋盘与数字格子动画
键盘操作控制方向
支持撤销 / 重做操作历史
提供一个按钮启动AI自动操作,自动完成并赢得游戏
限制:
必须自己实现游戏逻辑和AI算法(如Expectimax或贪婪搜索)
不允许使用任何外部游戏引擎或第三方库)
以下为具体各模型实测部分结果,仅供参考:
首先是ChatGPT,ChatGPT延续了以往快速反馈的特色,对于命令分解和反馈做的比较好。

测试题一中,ChatGPT对于页面的呈现非常完整,对于风的描述是云朵从画面中划过,以绿色圆柱左右摆动代表树木。雨滴掉落、雪花飘落呈现较为精准,晴天则在画面中放了一个太阳。所有天气卡片并排展示,页面背景为深色,设置了“Toggle Wind、Toggle Rain、Toggle Sun、Toggle Snow”四个按钮,可切换不同天气状态。但在实际点击过程中,各按钮和画面切换存在不同步现象。

测试题二中,ChatGPT构建了一个简单月历组件,星期对齐正确、可以点击按钮进行前后月份切换,其中今天的日期采取了高亮显示,整体切换流畅。

测试题三中,ChatGPT生成一个完整的大文件上传模拟器,模拟了将152M的测试视频上传的情况,测试中,多线程模拟器将测试视频切为153份,并以动画形式呈现上传进度,上传失败文件显示为红色,并在页面最下方提醒部分区块文件上传失败,整体对于命令呈现较为完整。

测试题四中,ChatGPT创建了迷你Web IDE,但并没有运行按钮,仅仅只是一个框架,不能使用。

测试题五中,ChatGPT生成了一个2048游戏,采用的数字格子动画,可以以键盘操作控制数字方向,并提供了撤销、重做、AI自动操作按钮,但在测试中发现,ChatGPT此次编程逻辑和算法还有提升空间,键盘操作控制数字方块的响应不够精准,AI自动操作中,也并未出现2048数字。

Claude 3.7在编程方面能力非常出色,代码生成后直接显示预览画面。


其中第一个测试题目是Claude 3.5在行业引起轰动的测试题,具体呈现方面,Claude 3.7确实不负所望。在表述基础上还添加了适度和风速两个指标。太阳、下雨、飘雪呈现比较直观,风卡片中呈现了三棵轻微晃动的树。按钮也非常精准、切换自然。但在设计中,画面元素太阳遮住了温度,树木遮住了湿度和风速,除此之外整体画面呈现几近完美,

第二个测试题中,Claude 3.7生的页面同样十分出色,左上角为月份/年份,右上角月份切换,星期对齐正确、可以点击按钮进行前后月份切换,其中今天的日期采取了高亮显示,整体切换十分流畅。相较于ChatGPT,Claude 3.7的月历组件整体呈现更精美。

第三个测试题中,Claude 3.7延续了画面精美的风格,ChatGPT生成一个完整的大文件上传模拟器,模拟了将152M的测试视频上传,测试中,模拟器将测试视频切为153份,点击开始上传后,以动画形式呈现上传进度。上方呈现整体进度情况。每上传成功一份会标绿显示success,未成功则显示Retry 1/2/3,在页面最下方,会显示具体时间及文件上传具体动作和进度。整体而言,这个测试题中,Claude 3.7近乎完美呈现了题目要求。

第四个测试题中,Claude 3.7创建了迷你 Web IDE,有运行按钮,但输入代码后发现不能运行。

第五个测试题中,Claude 3.7生成了一个2048游戏,这道测试中,Claude 3.7生成了一段超过长度限制代码,为此采取了两段生成,或许是这个原因,导致虽然生成的界面较为美观,但在测试中逻辑和算法问题比较突出,基本上没有可玩性。但就整体界面而言,Claude所生成的代码页面中有当前积分、历史最高积分、撤销、重来、新的游戏、AI玩游戏及停止AI玩游戏等按钮,并在界面下方标注了游戏玩法,非常齐全。

接下来测试Gemini 2.5 Pro在编程方面的能力,我们采用的是号称更擅长代码文档的Canvas功能。

第一个测试题目中,Gemini 2.5 Pro的页面呈现较为完整,对于风的描述是除了云朵的滑动,还有动画人物吹气的详细表述,树木左右摆动。雨滴掉落较为精准,晴天则在画面中仅仅把画面设置为了黄色,没有太阳元素。雪天雪花飘落基本没有呈现。按钮点击较为灵敏且准确。

测试题二中,Gemini 2.5 Pro搭建了一个简单月历组件,星期对齐正确、可以点击按钮进行前后月份切换,其中今天的日期采取了高亮显示,整体切换较为流畅。

第三个测试题中,Gemini 2.5 Pro虽然撰写了代码,但文件无法上传,测试无法呈现具体成果。

第四个测试题中,和ChatGPT及Claude3.7的不能运行不同,Gemini 2.5 Pro完整创建了一个代码编辑器应用。实测证明可以实现代码校对功能及实时预览运行结果,左下方有错误及正确提示,就这个题目而言,Gemini 2.5 Pro完成的较为出色。

第五个测试题中,Gemini 2.5 Pro所生成的2048游戏非常不完整,不满足命题要求。

接下来测试国内大模型,首先是DeepSeek,我们测试的是其R1版本。
和国外大模型直接快速写出代码不同,DeepSeek在代码生成之前经历了非常长的思考过程,但从结果上看,长思考过程和呈现似乎并没有太大关系。

第一个测试题目中,DeepSeek R1生成的界面较为简陋。仅仅有主要的元素云、雨、太阳、雪花。界面效果也很一般,在实际点击过程中,各按钮和画面不匹配现场非常频繁,很难满足命题要求。

测试题二中,DeepSeek R1搭建了一个较为简单月历组件,星期对齐正确、可以点击按钮进行前后月份切换,其中今天的日期采取了高亮显示,整体切换较为流畅。但设计呈现非常简单,不算美观。
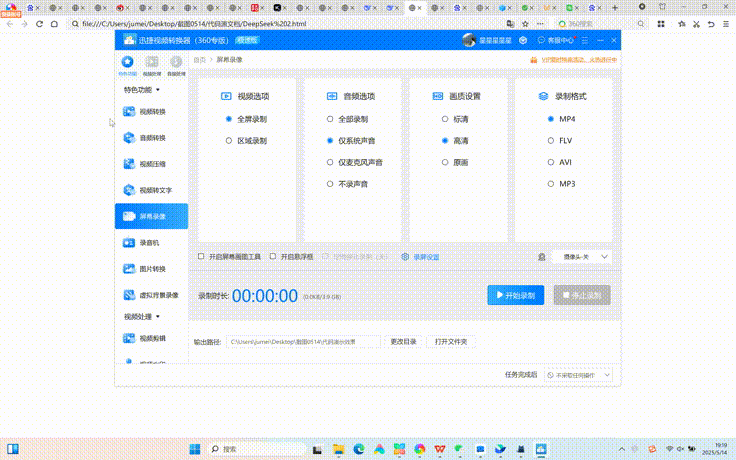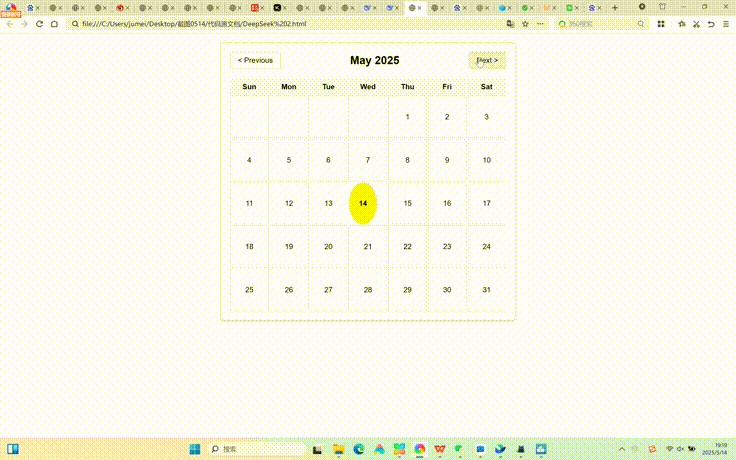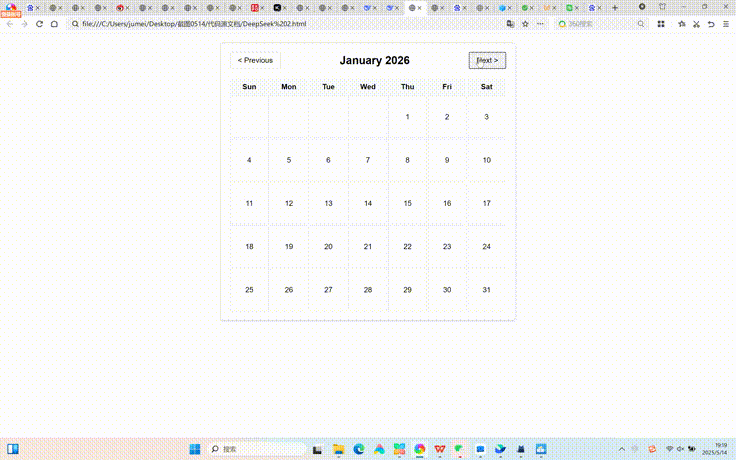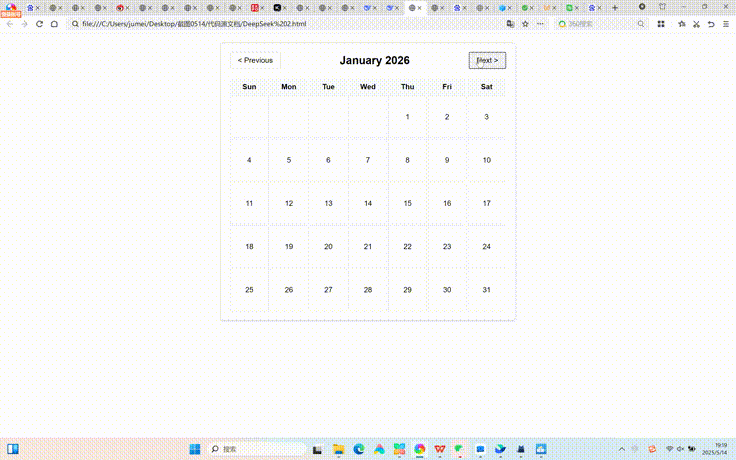
测试题三中,DeepSeek R1生成一个较为完整的大文件上传模拟器,模拟了将152M的测试视频上传,测试中,多线程模拟器将测试视频切为153份,并以动画形式呈现上传进度,每上传成功一份会标绿显示success,未成功则显示Retrying 1/2/3,上传失败文件显示为红色,并在页面最下方提醒部分文件块上传失败,整体对于命令呈现较为完整。

第四个测试题中,DeepSeek R1创建了迷你 Web IDE,但输入代码后不能运行,对于正确的代码也提示错误,页面左侧行号也显示错乱,整体和题目相差较多。

第五个测试题中,DeepSeek R1生成了一个2048游戏,相较于国外大模型,DeepSeek R1生成的界面较为简洁,左上方显示具体分数,下方有新的游戏、撤销、重来和AI玩游戏四个按钮。实测中,AI自动玩游戏短暂几次就会停止,算法和逻辑也有一定问题。

接下来是通义千问·CodeQwen,我们测试的是通义千问Qwen3更擅长处理代码问题的代码模式,就生成速度而言,通义千问在代码生成速度方面非常迅速,整体页面呈现也较为美观。代码页面可以选择深色和浅色两个版本,代码也做了彩色语法高亮处理。就界面优化层面而言,通义千问是非常出众的。

第一个测试题目中,通义千问Qwen3代码模式没有按照要求生成天气卡片,整体视觉呈现较为简陋。四张天气卡片没有完整展现,主要元素例如树木、云朵也都没有呈现,和命题严重不符。

测试题二中,通义千问Qwen3代码模式搭建了一个较为简单月历组件,星期对齐有错位,但基本正确、可以点击按钮进行前后月份切换,其中今天的日期采取了高亮显示,整体切换较为流畅。设计呈现非常简单,不算美观。值得一提的是,尽管是全英文提示词,通义千问还是把年份和月份换成了中文,这一点值得肯定。但下方的星期又变成了英文,整体呈现有些混淆,左右切换按钮也出现了错行。

测试题三、四、五三道题,通义千问Qwen3同样没有达到预期。测试题三中,通义千问Qwen3仅仅搭建了大文件上传模拟器的框架,实际测试中,并没有完整呈现文件上传界面,整体页面成为了灰色,没有完成命题要求;测试题四中,仅仅搭建了框架;测试题五中,生成的2048游戏,界面同样简陋,算法和逻辑也不对。



文心一言我们测试的是文心4.5Turbo版本,生成速度同样迅捷。代码部分也做了彩色语法高亮处理,代码页面可以选择深色和浅色两个版本。

第一个测试题目中,文心4.5Turbo生成的界面整体色调较为舒适,四个天气卡片没有全部在一起展现,主要元素中没有展现太阳,整体切换较为流畅。但值得肯定的是,每个天气卡片都有动画效果的同时,还用一句话形容了当前的天气或提示。比如,晴天中表述Perfect beach weather! 雨天中的Don't forget your umbrella! 雪天中的Time for a snowball fight! 刮风天气中的Kite flying weather! 整体而言较为出色。

测试题二中,文心4.5Turbo搭建了一个简单月历组件,星期对齐正确、可以点击按钮进行前后月份切换,其中今天的日期采取了高亮显示,整体切换较为流畅。

测试题三中,文心4.5Turbo生成一个较为完整的大文件上传模拟器,模拟了将152M的测试视频上传,测试中,和大部分大模型所生成的模拟器将测试视频切为153份不同,文心一言把视频切分为了31份,整体没有以进度条方式呈现,上传成功则为绿色Uploaded successfully提示,但整体文件未上传完毕,停顿在了70%左右,也没有提示区块文件上传失败,没有完成命题要求。

第四个测试题中,文心4.5Turbo虽然创建了迷你 Web IDE,但输入代码后不能运行,没有满足命题要求。
出人意料的是,文心4.5Turbo并没有完成第五个测试题。

实测中,百川大模型同样和DeepSeek一样,有较长的思考过程,代码部分也做了彩色语法高亮处理。

考虑到篇幅问题,我们集中为大家呈现接下来几个大模型的生成情况。
百川大模型在整体测试中,除了月历组件和多线程大文件上传模拟器,其他3个测试题百川完成效果均不太理想。以下是其各测试题效果:



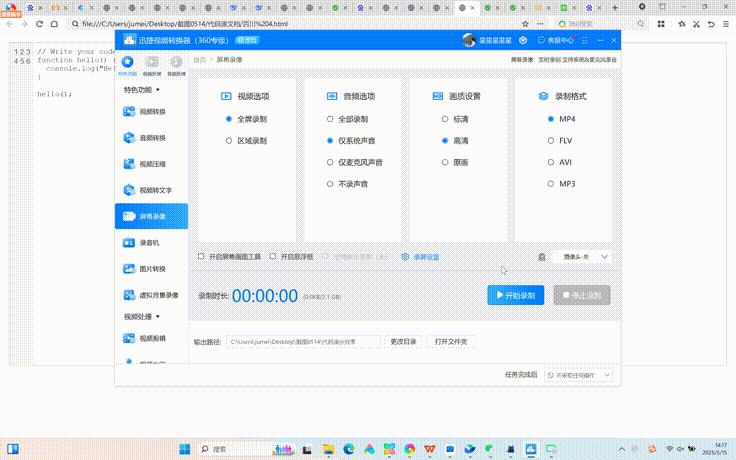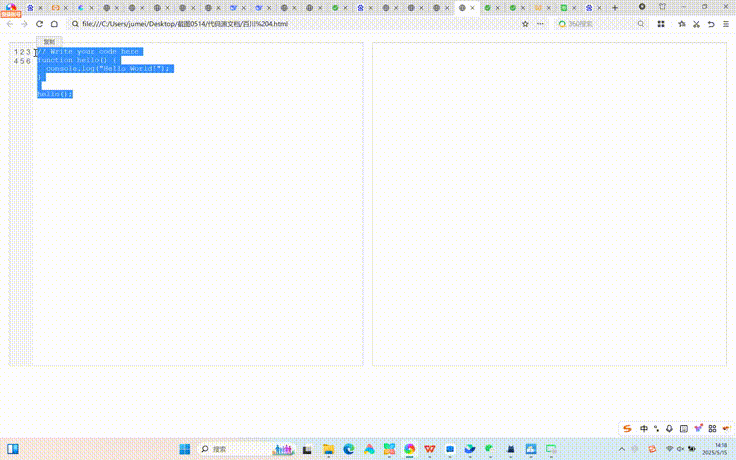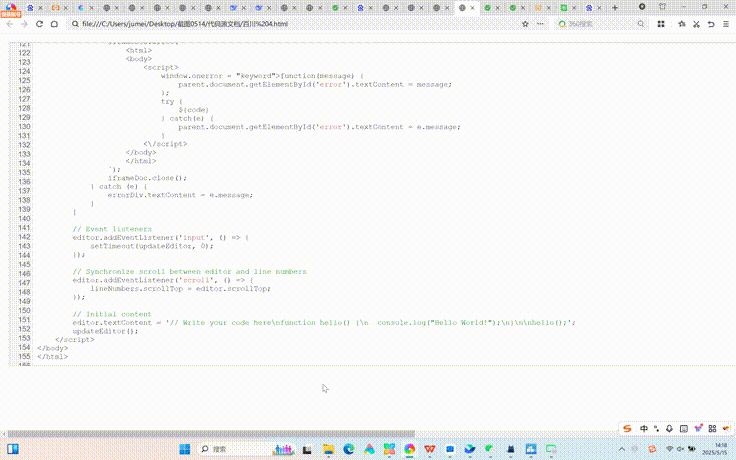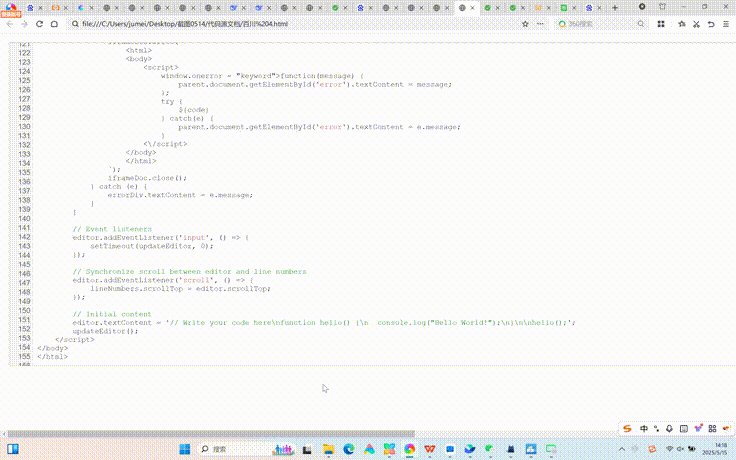

讯飞星火在整体测试中,整体思考过程相对非常久,除了月历组件较为完整,其他4个测试题完成效果均不算合格。以下是其各测试题效果:




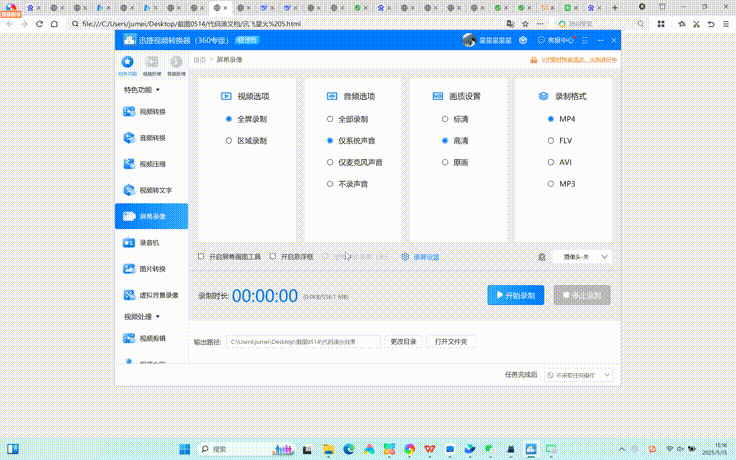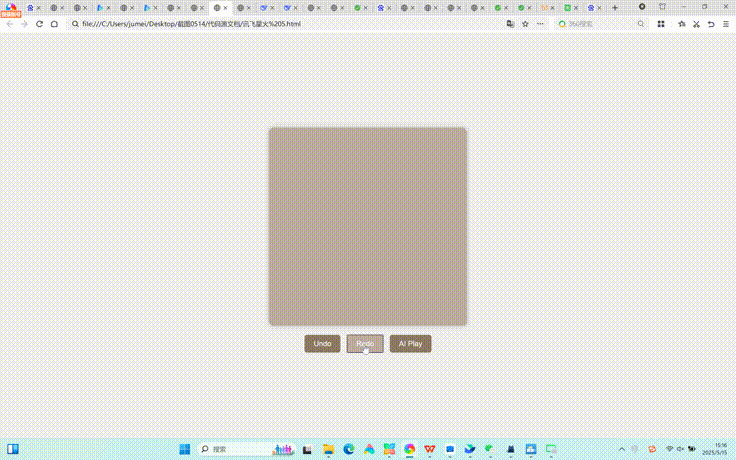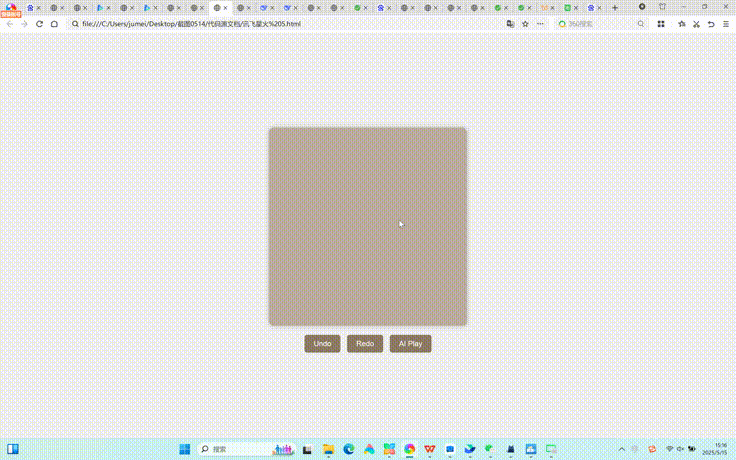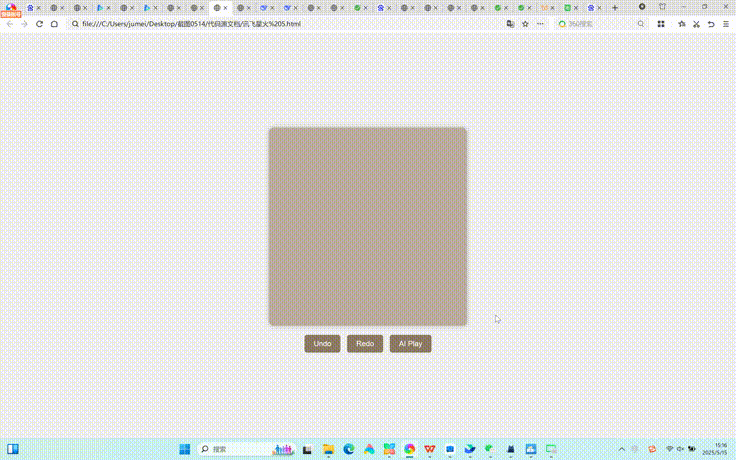
Kimi在整体测试中,天气卡片效果有生成,但不符合命题要求。月历组件是所有大模型生成效果中,竟然出现了星期和日期不对应的情况,是所有测试大模型中唯一的一个。大文件上传模拟器相对而言比较完整,迷你代码编辑器未达到命题要求。出人意料的是,联网模式下Kimi生成的2048游戏中,AI玩游戏中完成进度是最好的。但在不联网的情况下,Kimi并没有完成这项测试。





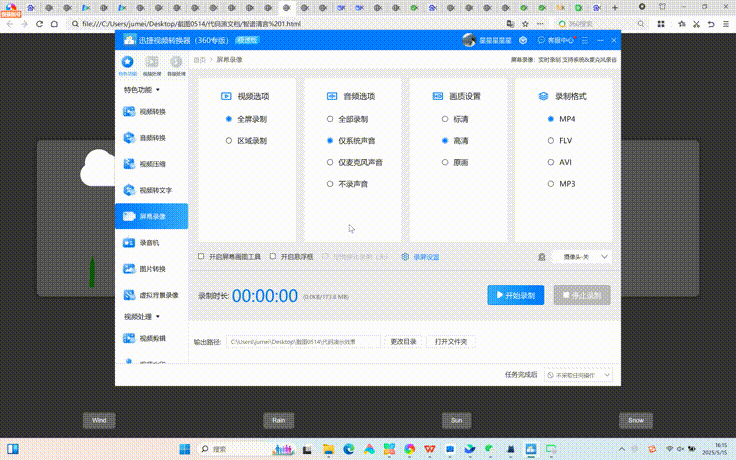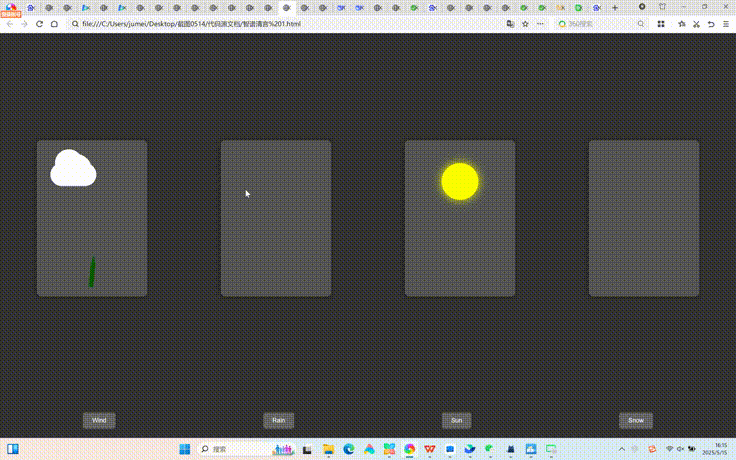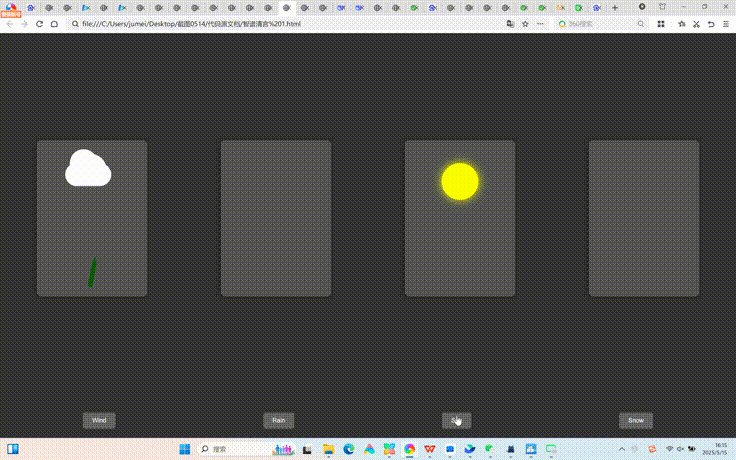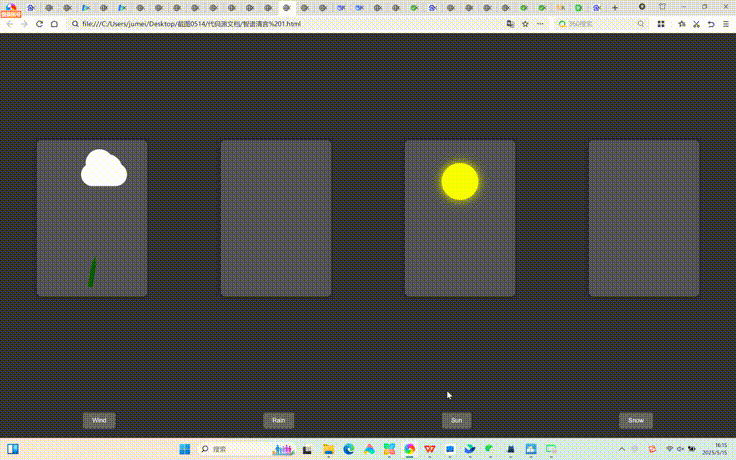
智谱清言在整体测试中,天气卡片不符合命题要求,月历组件较为完整流畅,多线程大文件上传模拟器无法上传文件,迷你代码编辑器和2048游戏未达到命题要求。以下是其各测试题效果:




通过本次横向评测,可以简单总结,各大编程助手在基础语法和常规任务上差异正在缩小,但胜负手并不在于语法细节,而在于对复杂架构的理解和多步推理能力。简单来说,下一代AI编程助手的竞争焦点,将是它能否像人类那样,从全局角度规划软件系统,并在需求持续演变的情况下保持思路清晰。
归根结底,AI编程助手要成为开发者的得力伙伴,需要超越对单句指令的翻译能力,真正理解编程任务的“语境”和“全局”,为软件创新提供真正有价值的帮助。
大模型编程角力不是性能跑分,
是生态竞争
诚然,测试题只是模型能力的一面镜子,只能简单反映出各模型写代码的实力。AI编程助手能否走出实验室、进入日常开发环境,关键肯定不在分数,而在产品化与生态建设。毕竟,从能写代码,到能真正帮助工程师完成开发任务,是两个维度的问题。这里面有几个误区:
误区一:模型能力≠开发效率
产品形态决定实际价值,即便HumanEval能跑出80%的准确率,现实中程序员更关注的是:你能帮我自动补全函数、理解上下文、定位bug、生成单元测试吗?就目前而言,显然答案是否定的。
误区二:本地部署就能满足企业级需求?
从工具到平台的延展产品化还有一层:是否能进入企业内部?大模型输出的代码涉及数据、算法、业务逻辑,安全、保密、可控至关重要。很多企业理所当然地认为“只要本地部署就安全了”,但现实远没有那么简单。除了模型推理要在本地完成,更大的挑战在于上下文数据如何同步、隐私策略如何配置、代码审计与权限管控如何落地,甚至还要考虑多租户下的资源隔离和团队协作。
从这个角度看,AI编程助手的真正“产品力”远不止模型,还包括IDE插件系统、上下文缓存方案、API集成能力、组织级使用管理等复杂架构。
误区三:垂类细分≠精细打磨
另一个常被忽略的点是,AI编程助手并非一刀切产品。前端、后端、算法、数据工程、运维,任务需求千差万别。对前端工程师而言,他们关注动画交互、DOM结构、跨端适配;对后端工程师而言,更重视数据结构、算法复杂度与服务性能。
某种程度上,AI编程助手正在从“代码助手”进化为“开发平台”:既要能写代码,更要能理解上下游工程环境,从DevOps到CI/CD,成为软件工程体系中的一环。
这背后考验的,是模型的泛化能力,也是产品和生态建设的综合实力。
短期来看,各大模型厂商还在以“能力秀”为主:谁在HumanEval上分高?谁能通过MBPP?谁能还原经典开源项目?但从中期来看,真正值得投入的,是开发链条的闭环打通:是否能在真实的工程环境中处理庞杂的上下文、跟踪任务进展、理解业务意图、生成高质量代码并支持持续迭代?最终,谁能率先打造出一个稳定、高效、具备“人机协同”特征的AI开发平台,谁就能率先占领开发者心智。
长期来看,AI编程助手的最终形态,可能不是“写代码更快”,而是“重新定义开发流程”。这一进化背后,既是大模型技术能力的迭代,更是产品形态的革命。
对国内大模型厂商而言,这或许是一次“弯道超车”的好机会。中国开发者生态复杂、业务场景丰富,本地化、垂直化、多端协同的需求远比国外市场更加繁杂。这意味着,谁能在“工程落地”上走得更扎实,谁就有机会在全球 AI 编程助手的竞赛中,跑出中国式的创新路径。
换句话说,模型能力是起点,产品化是分水岭,生态建设才是终局。
而这一切,才刚刚开始。
来源:数据猿
刷新相关文章
我要评论
不容错过的资讯















大家都在搜


