
百分点认知智能实验室:基于知识图谱的问答技术和实践
易显维 苏海波 | 2020-12-01 20:47
【数据猿导读】 随着互联网软硬件相关技术的飞速发展,人们逐渐从信息时代进入智能时代。知识图谱作为承载底层海量知识并支持上层智能应用的重要载体,在智能时代中扮演了极其重要的角色。而利用知识图谱支撑上层应用仍存在诸多挑战,因此基于知识图谱的自然语言问答展开研究是十分有必要的。

编者按
随着互联网软硬件相关技术的飞速发展,人们逐渐从信息时代进入智能时代。知识图谱作为承载底层海量知识并支持上层智能应用的重要载体,在智能时代中扮演了极其重要的角色。而利用知识图谱支撑上层应用仍存在诸多挑战,因此基于知识图谱的自然语言问答展开研究是十分有必要的。
时值2020年新型冠状病毒疫情爆发,2020年全国知识图谱与计算语义大会(China Conference onKnowledge Graph and Semantic Computing 2020)以新型冠状病毒为核心构建了包括新冠百科、健康、防控等多个高质量的知识图谱, 并于此针对知识图谱构建的关键技术及其核心应用提出四个评测子任务。
百分点认知实验室参加了该评测任务中的“知识图谱的自然语言问答”比赛,经过长达3个多月的激烈角逐,百分点认知智能实验室在比赛数据集上得分0.90106,位列A榜第三名。
本文主要介绍实验室在本次比赛和基于知识图谱问答业务的实践中使用的技术方案。
本文作者:易显维、苏海波
一、背景介绍
知识图谱的目的是给人工智能应用提供知识支撑,使得人工智能系统尤其是其中的决策算法在决策过程中能够参考到现实世界中丰富的知识。但是一直以来如何利用其中的知识是人工智能从感知走向认知的一个关键问题。在这个背景下,基于知识图谱的问答成为人工智能算法利用知识图谱的知识的一个突破点,解决了这个问题,意味着人机交互的重要变革,象征着计算机对于人类的自然语言理解产生了巨大进步。
相比于传统的搜索引擎获取知识的方式,智能问答系统基于自然语言交互的方式更符合人的习惯。随着人工智能的进一步发展,知识图谱在深度知识抽取、表示学习与机器推理、基于知识的可解释性人工智能、图谱挖掘与图神经网络等领域取得了一系列新的进展。这些进展让知识图谱的问答系统需要面对的两个问题(问题的理解和问题到知识图谱的语义关联)得到了较好的解决,使得知识图谱智能问答工程应用成为现实。百分点认知智能实验室在多个行业积累了丰富的基于知识图谱问答的技术实践经验。
二、问题示例
数据集以自然语言问句和对应的SPARQL查询语句标记组成,这里简要介绍SPARQL查询语言:
SPARQL [1] (SPARQLProtocol and RDF Query Language),是为RDF开发的一种查询语言和数据获取协议。其语法由三元组组成,其中 x所在where语句中的位置表示需要查询的是哪一个要素。
列举数据集中三种典型问题为例,这三种问题代表了数据集中三种不同的查询类型,查询类型见每个问题的查询路径图:
问题:武汉大学出了哪些科学家
查询语句:select x where { x<职业><科学家_(从事科学研究的人群)>. x<毕业院校><武汉大学>.}
答案:"<郭传杰><张贻明><刘西尧><石正丽><王小村>"
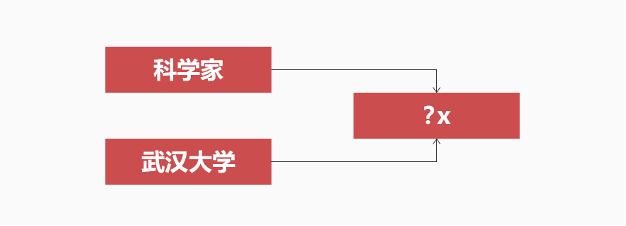
图1. 第一种问题的查询路径
问题:凯文·杜兰特得过哪些奖?
查询语句:select x where { <凯文·杜兰特> <主要奖项> x . }
答案:“7次全明星(2010-2016)” “5次NBA最佳阵容一阵(2010-2014)” “NBA得分王(2010-2012;2014)” “NBA全明星赛MVP(2012)” "NBA常规赛MVP(2014)"

图2. 第二种问题的查询路径
问题:获得性免疫缺陷综合征涉及哪些症状?
查询语句:select x where {<获得性免疫缺陷综合征><涉及症状> x.}
答案:"<淋巴结肿大> <HIV感染> <脾肿大> <心力衰竭> <肾源性水肿> <抑郁> <心源性呼吸困难> <低蛋白血症> <不明原因发热> <免疫缺陷> <高凝状态> <右下腹痛伴呕吐> "
问题:詹妮弗·安妮斯顿出演了一部1994年上映的美国情景剧,这部美剧共有多少集?
查询语句:select y where { x<主演><詹妮弗·安妮斯顿>. x<上映时间>""1994"". x<集数> y.}
答案:"236"
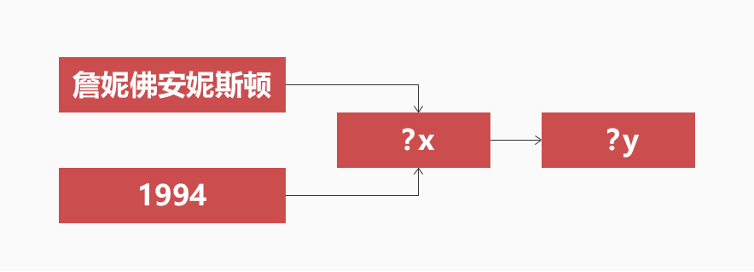
图3. 第三种问题的查询路径
三、技术方案
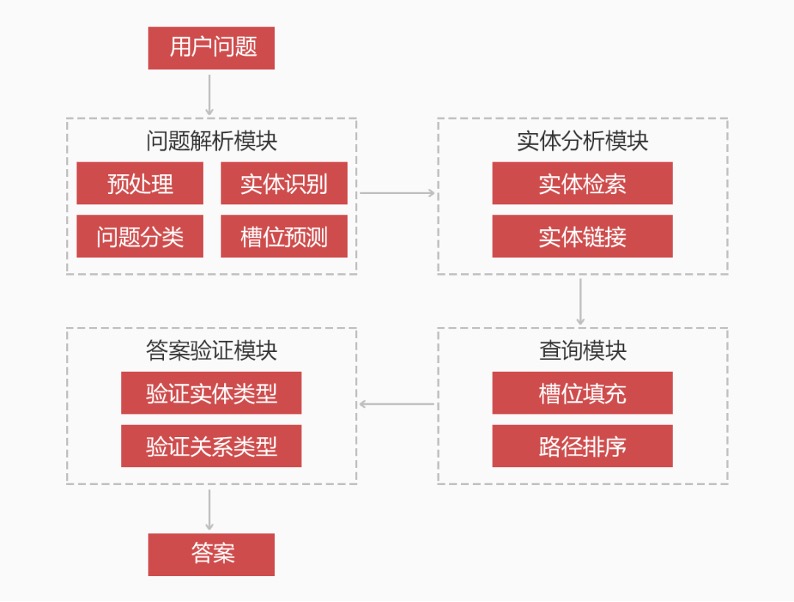
图4. 技术方案框架图
技术方案如上图,下面以“莫妮卡·贝鲁奇的代表作?”这个问题举例说明该技术方案中的步骤。
第一步:我们将该问题进行命名实体识别(预处理模块:实体识别),得到名为“莫妮卡·贝鲁奇”的实体提及,将该实体提及输入别名词典和ES中,得到备选实体名称。
第二步:将问题输入我们的问题结构分类模型(预处理模块:问题分类),得到该问题属于一跳问实体的问题类型,得知该问题有一个实体槽位和一个关系槽位需要填充(预处理模块:槽位预测)。
第三步:将第一步中得到的实体通过语义特征和人工特征进行实体消歧,得到真正的实体为<莫妮卡·贝鲁奇>(实体分析模块:实体链接)。
第四步:根据第二步中预测的槽位,将实体填充到该查询语句中得到select xwhere {<莫妮卡·贝鲁奇><> x.}(查询生成模块:槽位填充)。
第五步:搜索<莫妮卡·贝鲁奇>的所有关系名称,和原文进行语义匹配并排序,得到关系<代表作品>(查询生成模块:路径排序)。
第六步:将代表作品填入第二步所预测的关系槽位中,得到查询语句select xwhere {<莫妮卡·贝鲁奇><代表作品> x.},并转化为图数据库查询语言(查询生成模块:槽位填充)。
第七步:将第六步中得到的查询语言在图数据库中查询并得到答案,并进行答案校验(答案验证模块:验证答案的实体类型)。
四、问题分类
上面方案中的第二步需要对问题进行分类,问题的分类标准有如下几个考量:
(a)问题生成的知识图谱查询语句有几次查询,称为几跳问题;
(b)每一跳的查询中分为是问实体还是问关系;
(c)查询过程中是夹式还是链式。
夹式:为多个实体查询不同的关系之后求交集。
链式:多个实体依次求关系,再通过关系求实体。
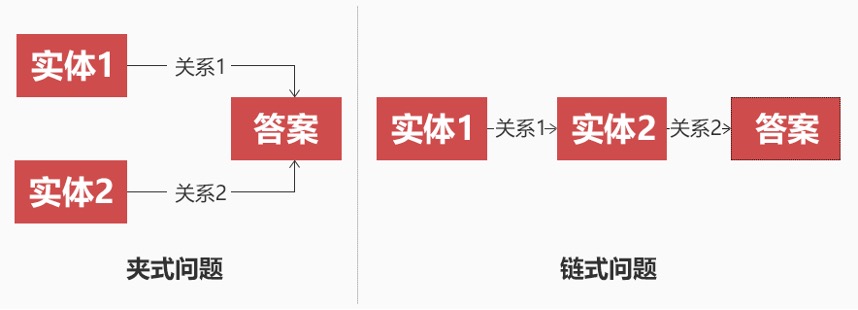
图5. 问题类型示意图
根据上面的分类标准,问题可以具体划分为如下三类:
(a)一跳问实体类型:
莫妮卡·贝鲁奇的代表作? select x where {<莫妮卡·贝鲁奇><代表作品> x.} select x where {<><> x.}
其括号内结构为<主><谓><宾>,得到主语、谓语,问宾语。
(b)二跳链式问实体类型:
发明显微镜的人是什么职业?select y where {<显微镜><发明人> x. x<职业> y.} select y where {<><> x. x<> y.}
其括号内结构为<主1><谓1><宾1><主2><谓2><宾2>,得到主语1、谓语1,匹配中间节点< x>,再根据中间点的“职业”得到链式答案。
(c)二跳夹式问实体类型:
我们会在哪个民俗节日里猜灯谜?select x where { x<类别><民俗>. x<节日活动><猜灯谜>.} select x where{ x<><>. x<><>.}
其括号内结构为<主1><谓1><宾1><主2><谓2><宾2>,得到主语1、谓语1、主语2、谓语2,最终得到宾语1、宾语2。将二者取交集,得到夹式答案。
4.1 问题类型的编码方法
为了能建立一种将自然语言到SPARQL语言的中间表达方式(见参考文献3、4),我们将问题根据上述分类标准,生成每种分类的序列式标签标记,每个标签表示问句中槽位要素的语法成分。我们若考虑二跳以内问题,则编码需要的槽位数量为:

图6. 槽位示意图
其中每一位表示方法:
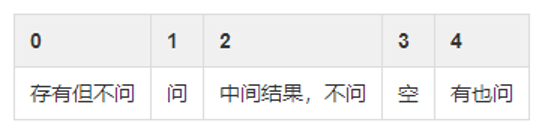
图7. 每一位表示方法图
一跳问实体类型:
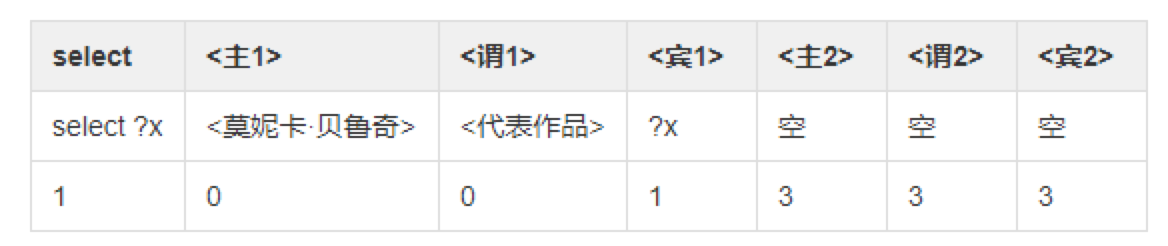
图8. 一跳问实体槽位信息图
采用Bert-Seq(见参考文献2)模型建模,测试集问题通过该模型预测后,得知问题的分类序列,即可得知有哪几个语义槽需要填充,比如一跳问实体需要填充一个实体和一个关系。
五、实体识别
5.1 常见的命名实体识别方法
目前为止,命名实体识别主流方法可概括为:基于词典和规则的方法、基于统计机器学习的方法、基于深度迁移学习的方法等。在项目实际应用中一般应结合词典或规则、深度迁移学习等多种方法,充分利用不同方法的优势抽取不同类型的实体,从而提高准确率和效率。在中文分词领域,国内科研机构推出多种分词工具(基于规则和词典为主)已被广泛使用,例如哈工大LTP、中科院计算所NLPIR、清华大学THULAC和jieba分词等。
在本数据集中主要采用了词向量+条件随机场的方法对自然语言问题中的命名实体进行识别:
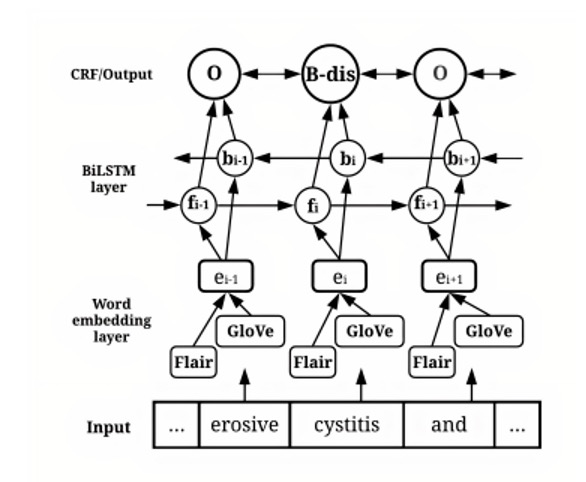
图9. Bert-Lstm-CRF结构图
(参考BioNerFlair:biomedical named entity recognition using flair embedding and sequence tagger)
5.2 检索在实体识别过程中的作用
2020年CCKS基于知识图谱的问答任务中有较多的和疫情相关的医学领域问题:
(a)新冠病毒肺炎有哪些别称?
(b)哪些是非传染性的胃炎?
(c)流感裂解疫苗的规定组织是?
(d)哪种检查项目能检测出耳廓腹侧面局限性囊肿、耳硬化症和耳骨外翻的症状?
(e)有什么样的检查项目能检测新生儿呼吸暂停、先天性肺动静脉瘘和老年人急性呼吸窘迫综合征这些疾病?
这类问题中出现的命名实体的特点是名称较长,组成字符较为生僻,用上文中提到的模型识别效果不理想,会出现少字、识别结果序列中断的现象。为了能够提高召回率,并加速匹配实体名称的过程,我们引入ELK作为命名实体识别的辅助技术手段,并取得了良好的效果。
六、实体链接
下图中,“乔丹”、“美国”、“NBA”这些片段都是mention,其箭头所指的方块就是它们在图谱里对应的entity。其中“NBA”和“联盟”虽然字面上不同,但是都指代了知识库中的同一种实体。实体链接(entitylinking)就是将一段文本中的某些字符串映射到知识库中对应的实体上。
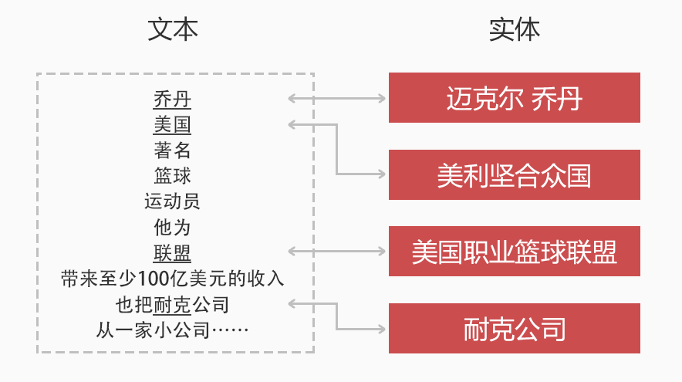
图10. 实体链接示意图
中文短文本的实体链接存在很大的挑战,主要原因如下:
(a)名称变体:同一实体可能以不同的文本表示形式出现。这些变体的来源包括缩写(New York, NY),别名(New York, Big Apple),或拼写变体和错误(New yokr)。
(b)歧义性:根据上下文的不同,同一名称通常会涉及许多不同的实体,因为许多实体名称往往是多义词(即具有多重含义)。“巴黎”这个词可以指法国首都或帕丽斯·希尔顿。
(c)缺省:有时,一些命名实体可能在目标知识库中没有正确的实体链接。这种情况可能发生在处理非常特定或不寻常的实体时,或者在处理关于最近事件的文档时,另一种常见情况是在使用特定领域的知识库(例如,生物学知识库或电影数据库)时。
实体链接的方法大致分为以下几种:
(a)基于排序的方法:Point-wise、Pair-wise。由于实体链接任务ground truth只有一个实体,一般都是用point-wise来做。输入是文本的context、mention、和某个实体的特征,输出mention指向该entity的置信度,以此排序,选出最可信的实体,常用的方法有包括LR、GBDT、RankSVM等算法。
(b)基于文本的方法:利用从大型文本语料库中提取的文本特征(如词频-逆文档频率Tf-Idf,单词共现概率等)。
(c)基于知识图的方法:利用知识图的结构来表示上下文和实体之间的关系。
七、查询构造
在知识图谱问答中,一个关键的步骤就是查询路径的构造。查询构造旨在根据问题,构造出问题的候选查询路径,通过路径排序筛选出正确的查询路径,根据此路径在知识图谱中查找相对应的实体目标,作为问题的最终答案。而在此过程中,提高查询路径的召回率是我们的根本目标。
主要有两种不同类型的问句被广泛研究:
(a)带约束的单关系问题。例如,在问题“谁是美国第一任总统 ”中,答案实体和实体“美国”之间只有一个“总统”的关系,但是我们也有“首先”的约束需要被满足。针对这类复杂问题,我们提出了一种分阶段查询图生成方法,该方法首先确定单跳关系路径,然后对其添加约束,形成查询图。
(b)有多个关系跳跃的问题。例如“谁是Facebook创始人的妻子 ”,答案与 “Facebook”有关,通过两种关系,即“妻子”和“创始人”。为了回答这类多跳问题,我们需要考虑更长的关系路径,以达到正确的答案。这里的主要挑战是如何限制搜索空间,即减少需要考虑的多跳关系路径的数量,因为搜索空间随着关系路径的长度呈指数级增长。一个基本的解决方法就是使用beam search,其次还可以根据数据构造特定的剪枝规则,减少产生的查询路径。
待候选查询路径产生后,须在候选路径中选择评分Top1的查询路径,作为最终选择的目标。其选择路径的方法基本是基于排序模型的,如深度模型 ESIM、BiMPM等算法。以下介绍一种基于计算句子相似度的排序方法,Siamese LSTM。Siamese Network 是指⽹络中包含两个或以上完全相同的⼦⽹络,多应⽤于语句相似度计算、⼈脸匹配、签名鉴别等任务上。下图是整个网络大致的计算过程,左右两个句子输入后,句子中的每个词对应一个数字,左右两句话分别映射成一个向量,各自经过一个LSTM网络抽取特征后,使用曼哈顿距离计算两边向量的差距,最终得出预测结果(见参考文献1)。
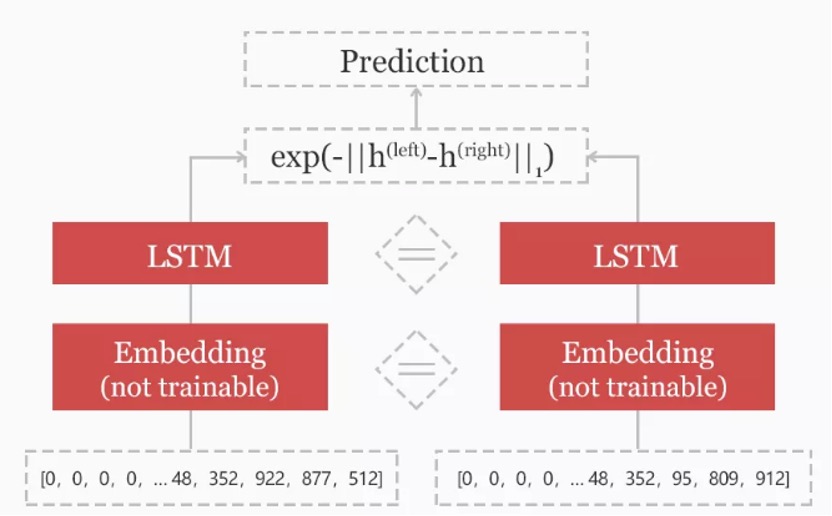
图11. 语义匹配方法网络结构图
(参考Siamese Recurrent Architectures for Learning Sentence Similarity)
通过Siamese LSTM的方法,我们可以计算待候选查询路径和查询问题的匹配得分,选出得分Top1的查询路径就可以作为我们的最终选择路径。
八、评测效果
本评测任务所使用的是2020CCKS(中国知识图谱与计算语义大会)新冠开放知识图谱,它来源于 (http://openkg.cn/group/coronavirus),其中包括健康、防控百科、临床等多个具体数据集。我们将这些数据集整合到一起,同开放领域知识库PKUBAS一起作为问答任务的依据。本任务的评价指标包括宏观准确率(MacroPrecision),宏观召回率(Macro Recall),AveragedF1 值,本文方法最终的实验效果指标如下:
(a)识别效果:Averaged F1=0.901
(b)识别性能:在NVIDIA 2080Ti GPU上,平均响应时间约200ms
总结
最后我们总结一下本方案的应用有效性和价值潜力。在应用有效性方面,通过今年2020年全国知识图谱与计算语义大会知识图谱问答任务数据集的评测得分,证明该方案在公开数据集上性能表现优秀,具有很好的应用效果;在价值潜力方面,本方案执行效率高,并且适合各种不同业务场景的问答需求,表现出良好的可扩展性,适合工程应用。百分点认知智能实验室已经将该套方案部署到了众多不同业务的知识图谱系统中,取得了不错的社会和经济效益。
参考资料
[1]Siamese Recurrent Architectures for Learning Sentence Similarity
[2]Learning Phrase Representations using RNNEncoder–Decoder for Statistical Machine Translation
[3]SEQ2SQL: GENERATING STRUCTURED QUERIES FROMNATURAL LANGUAGE USING REINFORCEMENT LEARNING
[4]Towards Complex Text-to-SQL in Cross-DomainDatabase with Intermediate Representation
[5]BioNerFlair: biomedical named entityrecognition using flair embedding and sequence tagger
来源:百分点






































我要评论












活动推荐more >
- 2018 上海国际大数据产业高2018-12-03
- 2018上海国际计算机网络及信2018-12-03
- 中国国际信息通信展览会将于2018-09-26
- 第五届FEA消费金融国际峰会62018-06-21
- 第五届FEA消费金融国际峰会2018-06-21
- “无界区块链技术峰会2018”2018-06-14
















