
“数据荒”背后,具身智能行业还欠一笔工程账
原创 数据猿 | 2026-06-23 23:32
【数据猿导读】 五位百亿估值的具身智能公司CEO,坐在同一张桌子上。整场讨论只有一个问题没有分歧——数据。

“本体告一段落,具身智能进入“数据时刻”?
6月13日,北京智源大会。
五位百亿估值的具身智能公司CEO,坐在同一张桌子上。整场讨论只有一个问题没有分歧——数据。
不是融资节奏,不是本体成熟度,不是模型路线,是数据。
这个共识来得并不轻松。过去两年,行业花了大量时间争论“人形还是非人形”“VLA还是世界模型”,但当大家坐下来直面现实时,发现所有争论的前提都被同一件事卡住了:没有足够多、足够好的数据,以上一切都不成立。
但比“数量不够”更隐蔽、也更拖效率的,是另一个问题——大量已经被采集到的数据,仍然无法直接用于训练。原始视频到训练就绪之间,隔着漫长的工程链路:清洗、对齐、标注、质检、格式转换,每个环节都可能卡住。
行业不缺原始素材,缺的是把原始素材变成“训练就绪”数据的工程能力。
高质量数据
已成具身智能的关键瓶颈
智源大会上,嘉宾们的判断高度一致:算力和参数不是当前最缺的,模型架构固然重要,但在数据严重缺乏的情况下,架构意义有限。当前真正的瓶颈,是高质量、可扩展的核心态数据。
这个判断首先建立在数量困境之上。
一组数字说明问题的严重性:全球高质量真实物理交互数据总量仅约50万小时,而训练通用具身智能模型需要千万小时起步。50万小时对千万小时,差了一个数量级。
芯片可以多买,模型可以重训,但物理世界的真实交互数据只能一分一秒地采集。没有大规模、高质量的真实物理数据,通用具身智能就永远停留在Demo阶段。

为了理解这个困境的深层结构,需要拆开来看三个层面。
第一道墙:采集本身就很贵、很慢。
Ego-centric第一人称视角数据,是具身智能最核心的训练素材。它和机器人头部感知高度一致,天然具备“第一人称”的视觉分布。
但真机遥操作采集面临三重限制:量产能力不足,造不出足够多的机器人同时采数据;单台设备昂贵,每采集一小时数据都要占用一台高成本硬件;场景部署成本高,如果要做家庭场景数据,需要把笨重设备运到用户家中。这些限制叠加在一起,导致高质量真机数据的产能极低。
行业已经在探索替代路径——人手采集、触觉手套、头戴设备——但这些方案本身也处于早期,采集效率和数据质量仍在验证中。每一种路径都有其局限性,目前还没有任何一种方案能够单独解决数据供给问题。
第二道墙:工具链高度碎片化。
传统数据服务商的工具链各自为政。采集用一套工具,标注用一套,质检用一套,格式转换和训练对接又是另一套。数据在不同环节之间流转时,标准不统一、格式不兼容,大量时间被消耗在“把A工具的输出变成B工具的输入”这件事上。
而具身智能数据对时序对齐、因果关联的要求,比传统CV数据高得多。一段第一人称操作视频,手部动作和相机视角变化必须精确同步,语言指令和动作片段必须精准匹配。这意味着即便只是简单的格式转换,也可能因为时间戳错位导致整段数据失效。
第三道墙:工程成本失控。
由于外部工具链不完整,模型训练团队被迫自行搭建数据管线。从原始视频导入开始,到清洗、对齐、标注、质检、格式转换,最后导出为训练框架能读取的格式,整个流程高度依赖内部工程能力。这不是算法问题,是工程问题——而且是一个极度消耗人力和时间的工程问题。
有业内人士估算,这部分成本有时是数据采集本身的3到5倍。花1块钱采数据,可能要再花3到5块钱让它变得“能用”。更隐蔽的代价是时间,算法团队的大量精力被消耗在数据处理上,真正用于模型迭代的时间被严重压缩。
数量不够、工具链碎片化、工程成本失控——三重困境叠加在一起,形成了行业当前的尴尬局面:一方面大家都在喊“数据不够”,另一方面大量已经采集的数据躺在硬盘里,离“能训练”还有很长的路。
那怎么来解决这些问题呢?
数据“用不上”的难题
有了一条新解法
上面提到的三重困境——采集成本高、工具链碎片化、工程成本失控——行业并非无动于衷。
事实上,过去一年已经有不少公司在尝试突破。
一批具身智能创业公司在探索数据采集的新路径,有的试图用低成本人手采集替代真机遥操作,给人发一双手套或一个头戴摄像头,就能在家里采集操作数据;有的押注触觉、力觉等多模态数据,希望为模型提供更丰富的物理信号;还有的选择退回到更务实的路线,不追求通用数据,而是在某个垂直场景中打透,形成数据闭环。
但这些探索目前都还处于早期,采集效率和数据质量仍在验证中。
就在这个节骨眼上,一条新的解法出现了——不是从采集端发力,而是从数据处理端入手。
6月22日,如祺出行旗下的“如祺数据”发布了一个具身智能数据平台。它专注解决一件很具体的事:把Ego-centric第一人称操作视频,自动化地处理成模型可以直接使用的训练数据。
如祺出行不是新玩家。这家出行服务公司早在2023年就开始布局全链路AI数据服务,此前在智能驾驶领域已完成能力验证——客户含小马智行、理想、腾讯,2025年技术服务营收1.6亿元,同比增长487%。
它的核心能力,除了凭借每年数亿单打车需求积累的大量高价值、多模态真实出行场景数据外,还有“长期处理真实物理数据的工程方法论和基础设施”。这套能力在智能驾驶领域已经跑通,现在被延展到了具身智能场景,目标是通过将数据处理过程标准化、自动化、可追溯,降低Ego-centric数据处理的边际成本。
具体来看,这套数据平台的核心,是一条覆盖从导入到导出的全链路自动化流水线。

导入环节,平台支持两种模式:直接上传已有预处理结果,或仅上传原始MP4由后台自动处理。上传与算法执行解耦,团队无需在本地维护复杂依赖环境。
AI预处理环节是整条流水线的技术核心。原始视频依次经过三个阶段:手部检测——从单目图像中恢复3D关键点与手部形状;相机位姿估计——输出连续准确的6DoF运动轨迹;手部3D姿态优化——将手部运动从相机坐标系映射到世界坐标系,最终输出结构化的手部运动轨迹。
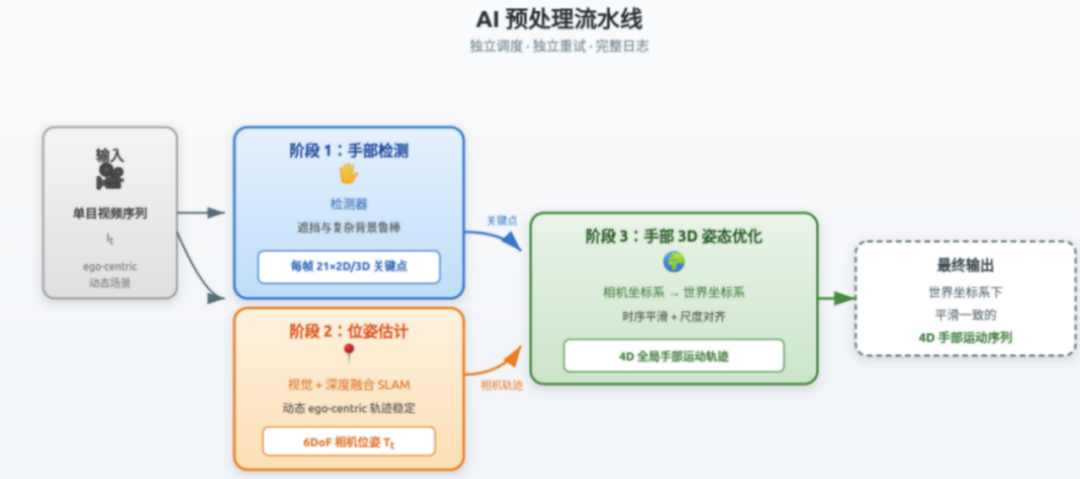
这三个阶段解决的核心问题是:把晃动、遮挡、视角受限的原始视频,变成在三维空间中可量化、可编辑的手部运动数据——这是从“原始素材”到“结构化数据”的关键一跳。
动作标注环节,平台面向的是具身模型特有的需求:带自然语言指令的连续动作序列,而非静态目标框选。标注工作台将当前帧及未来20帧的腕部轨迹投影到图像上,帮助标注员提前感知手腕运动趋势,精准判断动作边界。
审核质检环节,系统自动生成五维质检报告:切片完整性、手部检测质量、相机轨迹质量、语义一致性、样本分布均衡性。异常区域被自动高亮,审核员不再需要逐帧检查。实测表明,单条视频审核时间压缩50%。
导出环节,平台支持多种输出格式——训练框架原生格式(LeRobot、HDF5)、通用交换格式(JSON)、机器人中间件格式(ROS 2 MCap)。从标注完成到开始训练,中间不需要再做任何格式适配工作。
这条流水线的价值在于:过去需要多支团队、多套工具、数周时间才能走完的流程,被压缩成了一条可追溯、可质检、可规模化的管道。

简而言之,如祺出行这套新解法,就聚焦在从采集到训练就绪之间的关键数据工程环节。这也是显示,面对具身智能数据困境,行业已逐步从“死磕采集”开始转向思考如何从采集、处理、审核、标准化、输出等全链条提升已有数据的“可用性”。
数据基础设施
正在成为隐形战场
从智源大会的讨论来看,行业正在发生一个明确的转向。
这个转向背后的逻辑是,当硬件能力逐渐趋同,决定智能水平上限的是“具身大脑”的质量,而大脑的进化只能靠数据喂养。
头部公司已经开始行动,10万小时、100万小时、千万小时甚至上亿小时的数据目标被相继提出。这个节奏部分来自自动驾驶行业的路径验证——自动驾驶中,10万小时可以训练出可用模型,百万小时接近较成熟状态,千万小时则用于突破长尾场景。具身智能的任务复杂度远高于自动驾驶,对数据的需求只会有过之而无不及。
与此同时,数据形态和采集方式正在多样化。核心逻辑正在从“越多越好”转向“有效数据+场景匹配”,不是笼统地追求数据总量,而是在具体可落地的场景中持续积累高质量数据。
但无论走哪条路径,都指向同一个结论:“万台落地”需要数据基础设施先行。
6月9日,工信部与国资委联合启动专项行动,目标是年底推动“万台级规模落地”。万台机器人同时运行,意味着每一台都需要模型驱动,而模型迭代需要源源不断的训练数据。这不是一次性的数据采集能解决的,而是需要持续运转的数据生产管线,需要标准化的处理流程、自动化的质量控制和规模化的交付能力。
对于已沉淀出面向真实世界复杂数据的工程经验,具备构建全链路AI数据服务能力的数据服务商而言,这无疑提供了一个巨大的机会,让类似如祺出行这样的公司可以加快将其物理AI数据能力,从智能驾驶等领域外溢至高增长的具身智能赛道。据接近如祺出行的人士透露,公司已在具身智能领域获得商业化订单。
写在最后
回到智源大会那个圆桌。
五位CEO的共识是:数据是最大瓶颈。但如果我们把目光拉长,会发现这个判断背后藏着一个更底层的逻辑。
每一次技术范式的转移,都会经历一个从“模型崇拜”到“数据觉醒”的过程。
互联网时代,人们相信算法推荐可以解决信息过载,后来才发现用户行为数据才是推荐系统的真正护城河。自动驾驶早期,行业沉迷于规则引擎和感知算法,直到Waymo和特斯拉用数十亿英里的真实路测数据碾碎了所有“聪明算法”的优越感。大语言模型的爆发,本质上是Scaling Law的胜利,是海量文本数据堆积出来的涌现智能。
每一次,都是数据笑到最后。
具身智能正在进入这个拐点。本体已经阶段性成熟,接下来是数据工程的漫长战争。日复一日的数据采集、清洗、标注、对齐,这些看似不性感的“脏活”,最终构成了具身智能行业必不可少的基础设施。
历史反复验证了一件事:所有伟大的进步,最终都取决于那些最不起眼的基础设施。电网、公路、通信基站、云计算,没有这些“无聊”的东西,再聪明的算法也只是空中楼阁。
数据基础设施,就是具身智能时代的电网。
当一万台机器人在真实场景中稳定作业时,人们不会记得是谁铺设了第一条数据管道。但那个提前把管道铺好的人,早已拿到了下一阶段的门票。
来源:数据猿

我要评论
不容错过的资讯














大家都在搜


